
状況と嗜好に関するアノテーションに基づくオンライン楽曲推薦システム
概要
現在、プレイリスト(楽曲推薦リスト)の生成技術は、ユーザを楽曲配信サービスや楽曲の購入サイトに誘導することができるため音楽業界の活性化につながる有力な手段の一つと考えられている。本研究では、楽曲の類似度、ユーザ嗜好の類似度を判別するために、歌詞とアノテーションを利用し、視聴時のユーザの状況にあわせたプレイリストを生成する仕組みを提案する。またプレイリスト中の気に入った曲などをフィードバックすることにより、インタラクティブに好みのプレイリストを作成することができる。このようなプレイリスト作成のやり取りから、ユーザごとに嗜好、状況に関する特徴量を変化させ、個々のユーザの嗜好、かつそのユーザが置かれた状況に合った選曲ができるように適応していくことができる。
1 はじめに
近年MP3などの普及により音楽をデジタルコンテンツとして利用することが容易になってきている。ポータブルMP3プレイヤのような小型の機器に何時間分もの楽曲を入れて持ち歩くことも可能になり、Web上にはさらに多くの楽曲が存在している。このような膨大な楽曲の中からユーザにふさわしい楽曲を推薦する仕組みが求められている。
そこで現在プレイリスト生成に関する研究が盛んに行われている。プレイリストとは、コンサートの演奏題目やラジオ局の放送曲目のことであり、現在ではWindows Media Playerなど音楽プレイヤに見られる楽曲再生リストのこともプレイリストと呼ばれる。本研究での楽曲推薦リストとは、ユーザの嗜好に合った曲をまとめて推薦するプレイリストである。プレイリストは手軽に音楽に親しむことのできる手段であり、楽曲配信サービスなどと連携することにより楽曲購入のモチベーションにもつながる。
また、文書やビデオコンテンツなどへのアノテーションの研究が進められている。 アノテーションとは各コンテンツに対してメタ的な情報を関連付けることであり、アノテーションにより従来困難であった検索やコンテンツ簡約など多くのタスクを実現する手助けになる。
従来の楽曲推薦に関する研究は、協調フィルタリングによるプレイリスト生成システム やジャンル、アーティストなどの情報を利用したプレイリスト生成などがある。これらの研究では、協調フィルタリングの有効性や、ジャンル、アーティストについての情報が楽曲推薦について有効であることを述べている。
今回我々は、ユーザの楽曲解釈に関する情報を用いることでさらによい楽曲推薦を行うことができるのではないかと考え、楽曲がどのような情景を歌っているのか、その楽曲をどのような状況で聴きたいかというアノテーションを楽曲推薦に利用した。これらの情報を収集するために、Web ブラウザからアノテーションを収集するシステムを実装し、それぞれの楽曲についてアノテーションを収集した。また、文献では歌詞を特徴量とする楽曲の意味的な解析が可能であると示している。そこで、楽曲を深く聴き入る状況を想定し、歌詞を楽曲の特徴量のひとつとして採用した。
映画や楽曲など、コンテンツを推薦する際に有効であるとされている協調フィルタリングの手法は、膨大な数のコンテンツ中から個人の嗜好にあったコンテンツを探しだすために有効な手段であるが、そのコンテンツ自体を変換することは行っていない。一方プレイリストはコンテンツ集合へのリンクであり、コンテンツ一つのみの推薦ではない。コンテンツをある程度まとめて同時に提示する際には、その集合の提示方法において個人適応を行うトランスコーディングが可能であると考え、本システムのプレイリスト生成の仕組みに取り入れた。本システムでは強調フィルタリングとトランスコーディングを組み合わせ、よりユーザの特性に合わせたプレイリスト生成を行う。
協調フィルタリングやトランスコーディングを行うためには、ユーザのプロファイルが必要となる。ユーザプロファイルを作成する手段としては、直接ユーザがプロファイルを記述する手法や、システムの提示する情報へのユーザの返答によるプロファイルを形成していく半自動的な手法、システムが完全に自動的にプロファイルを生成する手法がある。
今回は、半自動的なプロファイル形成の手法を採用した。直接ユーザがプロファイルを記述する手法に比べてユーザの負担が少なく済み、また音楽は日常的に楽しむものであるため、時間経過に伴うユーザ嗜好の変化などにも対応することができる。また、完全に自動でユーザプロファイルを生成するよりも高い精度を見込むことができる。本システムでは、ユーザがシステムに返すフィードバック情報を元によりよいプレイリストを生成し再提示する。このインタラクションを通じてユーザのプロファイルを変化させ、個人適応を行う。
本システムが目指すユーザに適したプレイリストとは、歌詞と歌っている情景が嗜好に合い、ユーザの置かた状況にも合っった楽曲の集合とする。
2 プレイリスト推薦システム
プレイリスト生成の流れは、図のように、まずプレイリストプールから協調フィルタリングにより種となるプレイリストを選び出し、次にその種プレイリストをよりユーザの嗜好に近づけるためトランスコーディングを行い、ユーザにプレイリストを提示する。さらにユーザからシステムへ返すフィードバック情報を用いてよりよいプレイリストを生成すると同時にユーザのプロファイルを変更し、次回以降のプレイリスト生成のために個人適応を行う。
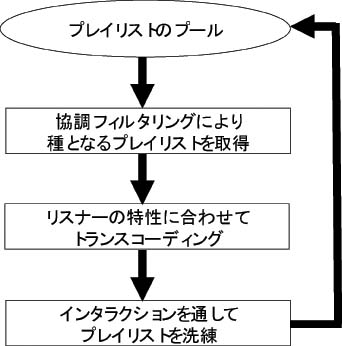
図1: システム構成
今回は、歌詞、楽曲情景、視聴状況という3種類の特徴量を採用しているが、文献などで述べられるように、他にも楽曲推薦の際に有効であるとされているジャンルやアーティストなど多くの特徴量が存在する。本手法はこれらの特徴量を随時取り込むことができるようにするため楽曲とユーザを特徴量空間へマップする手法を採用した。
図の3種類の特徴量空間にユーザをマップすることで、楽曲間、ユーザと楽曲間、またユーザ間での類似度の測定を可能にしている。歌詞と楽曲情景については、それまで視聴した好きな曲の特徴量の平均をそれぞれの特徴量空間にそのユーザの嗜好としてマップされる。視聴状況はそのつど異なるため、プレイリストを生成する時点で視聴状況入力フォームからの入力を視聴状況の特徴量空間にマップする。
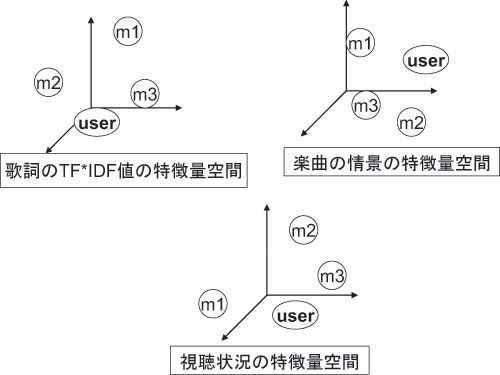
図2: 3種類の特徴量空間
今後新しい特徴量を導入する際には、特徴量空間を追加し、それらの間において以下の節で述べるプレイリスト生成の処理を行うことで、アルゴリズムを変更することなく楽曲推薦を行うことができる。
楽曲間の類似度推定に関するアルゴリズム、またプレイリスト生成の各段階である協調フィルタリング、トランスコーディング、インタラクションについての詳細を以下に述べる。
2.1 歌詞とアノテーションによる楽曲間類似度推定
楽曲情景と、視聴状況については、視聴するユーザの解釈に強く関わる情報であるため、楽曲を自動解析して得ることが困難である。そこで、別途用意したアノテーションシステムにより、曲と歌詞からどのような情景を歌っているか、どのような状況のときに聴きたいかのアノテーションを収集し、その結果を利用した。
収集するアノテーションは、楽曲全体の雰囲気に関するあいまいな情報であるため、多くのユーザからそれらの情報を取得し、統計的に処理を行う必要がある。そこで、Webベースのシステムとして、オンラインで複数のユーザが同時にアノテーション収集を行えるシステムを実装した。
楽曲が歌う情景、視聴したい状況に関するアノテーション項目については、サンプルとしてランダムに選択したPOPS50曲に対して、どのような楽曲情景、視聴状況であるかを調査し、その結果を仮の項目として設定した。さらに、予備実験として得られたアノテーション124個から得られたコメントより新たに項目を加え、楽曲情景のアノテーション項目は表\ref{tab:situation}のように決定した。
視聴状況アノテーションの項目は、表\ref{tab:situation}とほぼ同じであるが、現実的にありえない項目を削除して利用した。同一楽曲についての複数ユーザの解釈を統計的に反映させるために、一つの楽曲に複数のアノテーションが付与されている場合は、各項目についての平均値を利用した。
プレイリスト生成を行うためには、楽曲同士の類似度、ユーザに提示するべき楽曲をユーザと楽曲間の類似度を求め、どの楽曲をそのユーザに推薦するかをランク付けする必要がある。
図のように、歌詞のTF*IDF値、楽曲情景、視聴状況の3種類の特徴量空間を形成することができる。これらの特徴量空間から、以下の式により、
の2楽曲間の類似度を算出する。
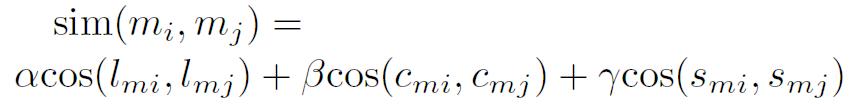
図3: 2楽曲間の類似度算出式
、
、
はそれぞれ各特徴量空間の重みであり、
、
、
はそれぞれ、歌詞、楽曲情景、視聴状況の特徴量空間における楽曲mの特徴量である。
複数の特徴量空間があるため、どの特徴量を強調するかによって、
、
の値は変化する。今回のプレイリスト生成システムでは、ユーザの置かれた状況により適した楽曲を選出することができるようにするため、
、
よりも
の値を大きく設定した。cos(a,b)はa,b間のコサイン距離をあらわす関数である。コサイン距離はある特徴量空間における2要素間の類似度を表すために有効であるとされている。得られた値が大きいほど類似した楽曲であるといえる。
2.2 協調フィルタリング
協調フィルタリングによる種プレイリスト発見の概要を図に示す。まずプレイリスト推薦を行うユーザU4と似ているユーザU1、U2を発見する。次に、それらのユーザが作成したプレイリストP1、P2、P3から、U4の状況と似ている状況で作成されたプレイリストP2を種プレイリストとしている。
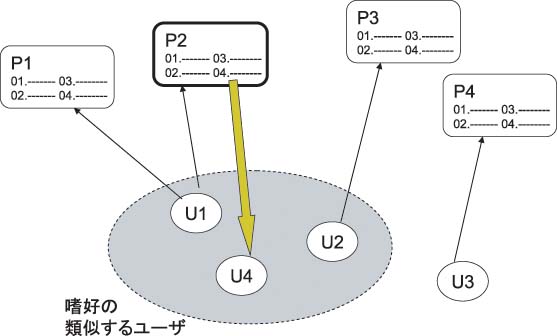
図4: 協調フィルタリングの概要
自分と似ているユーザを探し出す際には、ユーザがマップされている歌詞と楽曲情景の特徴量空間を利用する。それぞれのユーザ間のコサイン距離を足し合わせることにより類似度を算出する。その際の重みは、楽曲間の類似度算出の際と同様の値である。
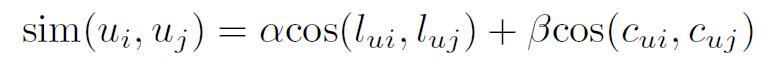
図5: 類似度計算の式
次にユーザの置かれた状況と、それらのユーザが作成したプレイリストが作成されたときの状況の類似度が閾値以上のプレイリストを発見する。それらのプレイリストから、ユーザ嗜好の類似度、またユーザの置かれた状況と、そのプレイリストが作成されたときの状況の類似度、プレイリストのオススメ度を踏まえて、一つの種プレイリストを決定する。
候補となるプレイリストから、最終的に推薦するプレイリストを選出するためには、どの程度そのユーザに推薦できるかを求める必要がある。ここでは、嗜好の類似しているユーザが、似たような状況のときに生成した、推薦度の高いプレイリストを種プレイリストとして選び出すために、各プレイリストについて推薦ランクrankを求め、候補となっているプレイリストの順位付けを行う。
ユーザと、ユーザ
が作成したプレイリスト
における推薦ランクは以下の式で表される。
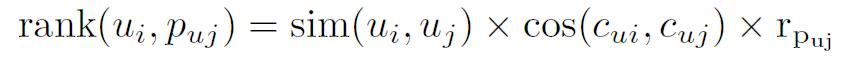
図6: rankの算出
はそのプレイリストのオススメ度である。
と
の類似度、
が置かれている状況と
が作成されたときの状況の類似度、オススメ度からそのプレイリストの推薦ランクを算出する。最終的にこの推薦ランクが最も高いプレイリストを種プレイリストとして選出している。
2.3 トランスコーディング
従来の協調フィルタリングによるコンテンツの推薦に加え、そのコンテンツをさらにユーザの嗜好にあわせるトランスコーディングを行うことが可能である。本システムでは、協調フィルタリングによって選び出された種プレイリストから、ユーザの嗜好に合わせて新しいプレイリストを生成する。
今回実現したトランスコーディングでは、種プレイリストから、ユーザの嗜好に合わない楽曲を除去し、さらに今まで聴いたことのある楽曲と、聴いたことのない楽曲を一定の割合で含ませるといった処理を行っている。今回は聴いたことの無い曲の割合を10曲中3曲含ませた。このように、楽曲の視聴履歴をユーザの嗜好や状況以外の情報からも楽曲推薦を行うことが可能になる。
嫌いな曲の除去などによる代わりに追加する楽曲は、ユーザの嗜好、置かれた状況と類似している楽曲である。ユーザの嗜好、置かれた状況を特徴量空間にマップし、ユーザと楽曲のコサイン距離を各特徴量空間で算出し、類似している楽曲から順に入れ替えを行う曲数を選択する。ユーザと楽曲
の類似度は楽曲間の類似度と同様の式であらわされる。
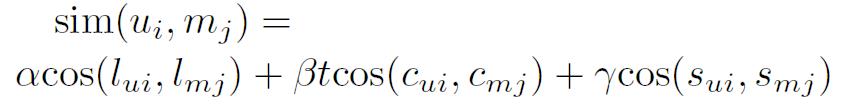
図7: ユーザと楽曲間の類似度算出
今後はユーザの詳細な視聴履歴などを利用して、プレイリストの曲順も含めたさらにユーザの嗜好に合ったプレイリスト生成をする必要がある。
2.4 インタラクション
以上の処理を経てユーザには図のようなプレイリストが表示される。ユーザは実際に楽曲を聴き、以下の情報をフィードバックすることができる。
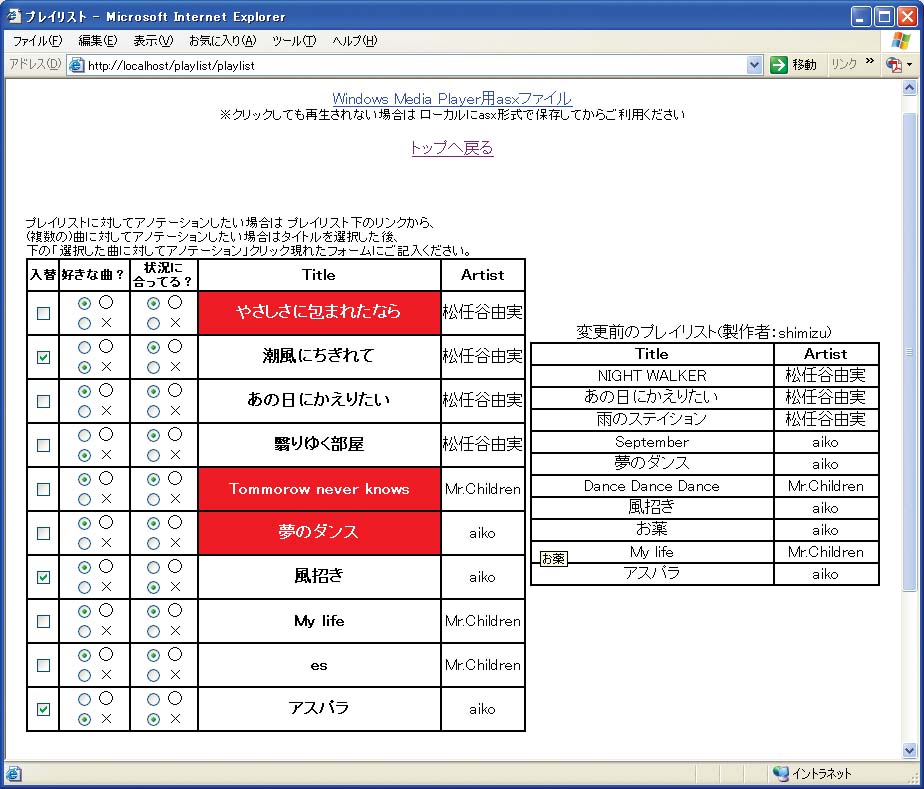
図8: 提示されるプレイリストの例
システムはユーザからのフィードバックを受け取り、状況や嗜好に合わず気に入らない楽曲の入れ替えを行い再度ユーザに提示する。同時にフィードバック情報からユーザのプロファイルを変化させ、個人適応を行い、次回のプレイリスト生成の際によりユーザの嗜好に合った楽曲選択ができるようにする。
好きな曲かどうか、状況にあっているかどうかといった情報から、ユーザの特徴量空間の基底ベクトルの変換を行う。以下は歌詞についての特徴量空間の基底ベクトル変換の式である。
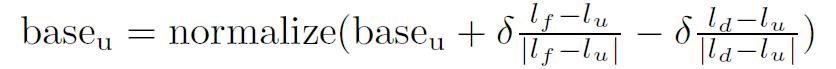
図9: ユーザの基底ベクトル変換
は嗜好に合っているとフィードバックされた楽曲の平均であり、
は嗜好に合わないという楽曲の歌詞の特徴量の平均である。元の基底ベクトルを、嗜好に合った楽曲の方向に短縮し、嗜好に合わない楽曲の方向に拡張している。
楽曲情景についての基底ベクトルについても同様に、嗜好に合っているかいないかというフィードバック情報を用いて変換を行う。また、視聴状況の特徴量空間は状況にあっているかいないかというフィードバックを利用して変換を行う。
さらに、ユーザが今までに視聴した曲や、好きな曲、嫌いな曲、どのような状況でどのようなプレイリストを生成したかといった情報を保存し、楽曲の特徴量空間にユーザをマップする際や、協調フィルタリングによる他ユーザへのプレイリスト推薦、より個人の嗜好に合ったプレイリストにトランスコーディングする際などにそれらの情報を利用する。
また、プレイリストを生成する際に指定した視聴状況をそれぞれの楽曲のアノテーションとして反映させた。これは、収集するアノテーションの情報量が楽曲によって偏ることを考慮し、少ない情報量の楽曲に対して情報を補完するための処置である。
3 予備実験
今回利用した楽曲はRWC音楽DBのPOPS100曲と、一般のJ-POP約130曲である。事前に全230曲中145曲、211個のアノテーションを収集した。
実装したプレイリスト生成システムの個人適応が有効であるかを確かめるための7人のユーザに対して予備実験を行った。
評価実験の方法は、自由に状況を想定し、プレイリスト生成システムに状況を入力してもらう。そしてシステムが提示したプレイリスト中に、「嗜好と状況」、「嗜好」、「状況」に合った曲が何曲あったかを申告してもらった。さらに、嗜好や状況に合わない曲をユーザにフィードバックしてもらい、それらの曲を入れ替えたプレイリストを提示するインタラクションをすべての曲が「嗜好と状況」に合った曲になるまで繰り返してもらった。
「嗜好」に合っているかどうかの判断については、アーティストやジャンルなど、今回は楽曲の特徴量として利用していない情報によってではなく、楽曲の歌詞、歌っている情景から判断してもらった。
以上のプレイリスト生成プロセスを3回繰り返してもらい、以下の値を集計した。
評価実験の結果を図に示す。左からユーザの嗜好と状況に合った曲数、嗜好に合った曲数、状況に合った曲数、インタラクションの回数であり、それぞれ左から1回目、2回目、3回目のプレイリスト生成プロセスにおける結果である。またそれぞれの棒グラフの頂点から標準偏差による幅を示した。
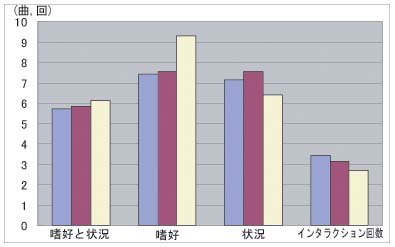
図10: 評価実験の結果
図の、左から2番目に示された嗜好に合った曲数の棒グラフからは、1回目、2回目、3回目と回数を重ねるにつれて増加している。ユーザの嗜好に合った楽曲提示が、プレイリスト生成の回数を重ねるごとに改善されているといえる。また、右端のインタラクション回数に関する棒グラフでは、プレイリスト生成の回数を重ねるにつ入れて減少している。プレイリスト生成の回数を重ねるごとに、少ない回数で満足のいくプレイリストが得られる。
さらに、左端の嗜好、状況共に合った楽曲数も、若干ではあるが改善されてきている。長く利用するユーザほど、嗜好と状況に合ったプレイリストが生成されるようになり、さらに完全に満足のいくプレイリストを得るまでのインタラクションが少なくてすむシステムであるといえる。
一方、左から3番目の状況に合った楽曲数の棒グラフでは、1回目、2回目、3回目とプレイリスト生成を繰り返すことによる増加傾向は見られない。視聴状況に合った楽曲提示については、プレイリスト生成を繰り返すことにより改善されているとはいえない結果であった。
この原因としては、登録されている楽曲の絶対数が少ないため、十分指定された状況に近い楽曲が存在しないという理由が挙げられる。ユーザの置かれる状況は非常に広いバリエーションが存在するので、それらの状況をカバーするためには多くの楽曲数が必要となる。
また、それぞれの楽曲に十分なアノテーションが存在していないことも原因のひとつである。今回の予備実験のために収集した楽曲情景と視聴状況に関するアノテーションは、すべての楽曲に対して均等に付与されていない。複数のアノテーションが存在する楽曲がある反面、ひとつもアノテーションが存在しない楽曲も存在した。このような現象は楽曲数、ユーザの数に関わらず、楽曲自身の人気やユーザの嗜好の偏りなどから、多くのアノテーションを収集できる楽曲が出る一方、一つもアノテーションが存在しない楽曲も現れる可能性がある。
それぞれの楽曲についての情報量の偏りは、多くのユーザの解釈の情報を集めるアノテーションシステムにとって解決しなければならない問題点である。ユーザをアノテーションの少ないコンテンツに誘導したり、\ref{interaction}節で述べたように、プレイリストに対するアノテーションを各楽曲のアノテーションとして反映させるなど、不足しているアノテーションを別の手法で補完する必要がある。
4 今後の課題
よりよいプレイリストを生成するには、今回利用した情報に、従来の研究で有効であるとされているジャンルやアーティスト情報、楽曲のリズムなど、の情報を加えることにより、よりユーザの嗜好に応じたプレイリスト生成が実現できると考えられる。
また、より多くのユーザ情報を取得する必要がある。たとえばある曲を何回聴いたか、どの部分をより好んでいるかなどである。それらのユーザに関する多くの情報からの機械学習によるユーザに特化したパラメータ取得と、それらの情報を取得するために詳細な視聴履歴をユーザプロファイルに反映させる手法について検討する必要がある。それらの情報を用いて、個人の嗜好により適応させるトランスコーディングが可能になる。今後は曲順も含めたプレイリスト生成の実現を目指す。
また、簡単な楽曲のセグメントをマーキングする機能を持たせ、楽曲がどのような区分に分かれるかというアノテーションシステムを考察中である。そのシステムで得られたセグメント情報と、我々がこれまでに作成したアノテーションシステムMiXAによる楽曲の内部要素に対するアノテーションの情報を利用し、楽曲のハイライト部分の抽出などを行う予定である。プレイリストのそれぞれの楽曲を短縮して提示することが可能になるだろう。
作成されたプレイリストの価値を高めるために、ライナーノーツを自動生成することが有効であると考えられる。ライナーノーツとはそのプレイリストの解説文である。今回は楽曲コンテンツの価値を高めるプレイリストの生成を行ったが、プレイリストの価値を高めることができれば、楽曲コンテンツの価値もさらに高まることが期待できる。
5 終わりに
歌詞とアノテーションを用いて、ユーザの嗜好・状況に応じたプレイリストを生成するシステムを実装した。本システムでは、協調フィルタリングとトランスコーディングによりユーザの嗜好、視聴状況に適応したプレイリストを生成する。またプレイリストを洗練するインタラクションにおいてユーザのフィードバックをプロファイルとして取り込み、個人適応を行う。
評価実験の結果、徐々にユーザプロファイルが改善され、少ないインタラクションにより満足なプレイリストが得られることを確認した。
謝辞
アノテーション収集ならびにアノテーション項目の選定に関してNTTコミュニケーション科学基礎研究所の研究員の皆様および名古屋大学長尾研究室の皆様にご協力いただきました。ここに記して感謝いたします。