
ディスカッションオントロジー:実世界の会議における人間行動解析による知識発見
1 はじめに
ディスカッションマイニングは,人間同士の知識交換の場である会議から,映像・音声情報やテキスト情報,メタデータなどの実世界情報を獲得し,それらを半自動的に構造化した会議コンテンツを生成する技術である.意味構造化された会議コンテンツから議論展開の抽出や類似議論の発見などにより,会議を行うグループの集団知識の活性化が期待される.しかし会議コンテンツからの意味解析には有益な会議コンテンツを生成する方法論の確立が必要となる.そこでベースとなるのが,会議を構成する意味要素間の関係を明確にする会議に関するオントロジー(ディスカッションオントロジー)が必要となる.
そこで本研究ではディスカッションオントロジー獲得へ向け,会議コンテンツの生成とメタデータの解析を行った.会議における議論の中心となる発言に対しメタデータを中心とした解析を行い,発言の分類ならびに議論展開の抽出を行うことで,会議に重要な意味要素の抽出と関係の明確化を目指す.
2 会議コンテンツ生成のためのメタデータ取得
会議支援や議事録作成の研究ではミーティングブラウザのように映像や音声の自動認識技術を用いることが多い.本研究で用いるディスカッションマイニングシステムでは,複数のカメラとマイクロフォンで議論の詳細な様子を記録するとともに会議参加者がブラウザベースのツールや,議論の構造化に必要なメタデータを入力するデバイスを用いて会議コンテンツを生成していく.ディスカッションマイニングシステムのイメージを図に示す.
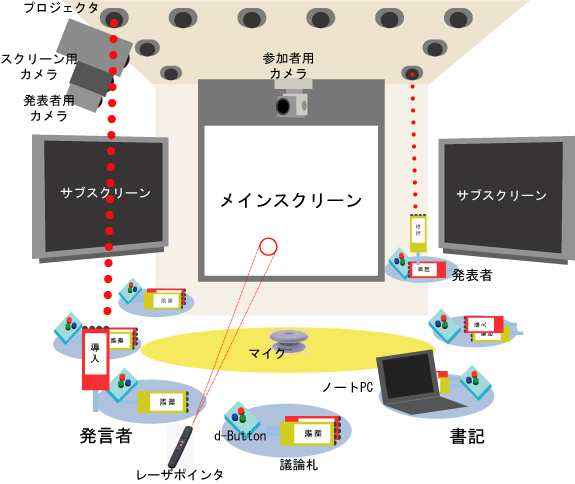
図1: ディスカッションマイニングシステム
また本研究では発表者がMicrosoft PowerPointのスライドを用いて発表を行い,その内容に対して参加者が議論を行う会議を対象とする.スライドに含まれるテキスト内容やスライドを切り替えるタイミングなどは発表者が専用ツールを用いることによって自動的に記録される.また,会議中の発言は議論札と呼ばれる札型のデバイスを用いることで,発言者のIDと「導入(Start-up)」「継続(Follow-up)」という発言の種類,発言の開始時間,終了時間が入力される.具体的な発言内容は,書記が専用ツールを用いて記録を行う.また会議参加者はボタンデバイスによって,現在行われている議論に対する自身のスタンスを表明することができる.議論の記録はXMLとMPEG-4によるマルチメディア議事録としてデータベースに記録される.記録された内容は,Webブラウザを用いて検索・閲覧が可能となっている.
ディスカッションマイニングでは発言者の発言のタイプを議事録構造化の視点から,「導入」と「継続」の2つに大きく分類する.発言の持つ意味については多くの議論があるが,議論の構造化とは議論のセグメンテーションであると考えている.つまり,現在行っている発言が直前の発言(あるいはいくつか前の発言)を受けてなされるものなのか(継続),それとも新しい話題の起点なのか(導入)が議事録理解に大きな影響を与えていると考える.
3 メタデータ解析による発言の分類と議論展開の抽出
3.1 発言の分類
ディスカッションマイニングシステムでは発言に関するメタデータとして,「発言者」「発言の種類(導入か継続か)」「直前の発言の種類」「発言時間」「キーワードの有無」などの情報が獲得できる.そこで,蓄積された会議コンテンツの発言に対しメタデータを中心とした解析を行い分類した.
蓄積された会議コンテンツ数は約370,発言数は約14500であった.これらをメタデータの出現頻度を基に8つの形式に分類した.出現頻度の高い属性の組み合わせの例には「発言の種類=導入,発言者=発表者以外の参加者,キーワード=有,発言時間=短い」などがある.実際の会議コンテンツの発言内容と照合すると,主に技術的な質問という意図を含む発言に多く見られる属性の組であった.分類された形式は,属性の共通点を考慮することで図のように階層的に表現することが可能となる.
3.2 議論展開の抽出
ディスカッションマイニングシステムでは,議論札によってそれぞれの発言に「導入」「継続」の情報が付与される.議論は導入発言から始まり,その発言に対して議論が継続されるなら継続発言が続いていく.この1つの導入発言とそれに付随する複数の継続発言をまとめて議論セグメントと呼び議論の単位としている.
それぞれの議論セグメントに含まれる発言に対し,付与されたメタデータを基に前述した8つの形式のどの分類に当てはまるかマッピングを行う.これによって議論セグメントにおいてどのような形式の発言が連続するかという議論展開を抽出することができる(図).
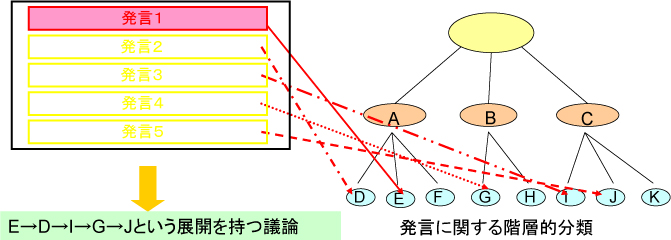
図2: 議論展開の抽出
3.3 議論展開の利用
前節のようにして抽出された議論展開から,任意の議論間の類似性や差分を発見することができる.抽出した議論展開の比較(パターンマッチ)から類似する展開を持つ議論の発見を行ったり,同内容の議論の展開比較を行うことで議論差分を発見したりすることができる.
抽出された議論展開は,議論の特徴とすることができる.これによって議論の文法を定義することができると考えられ,また議論要約や一つの議事録の要約も行うことができる.例えば,質問とそれに対する回答が繰り返される,という議論パターンの場合は,質問→回答→質問→回答の繰り返し,という議論展開となる.ここに含まれる繰り返しパターンを省略することにより議論の要約が可能となる.
本研究では議論における発言形式の分類や,発言の形式を中心とした議論展開の抽出を行った.メタデータの解析によって,会議の構成要素の重要性が明確になり,会議コンテンツ作成ならびに利用において必要な情報の取捨選択が可能になる.さらには会議コンテンツを構成する要素間の意味関係が明確になり,ディスカッションオントロジーを構築することが可能になるだろう.また,従来行われてきたテキスト処理によるキーワードを中心とした議論からの知識発見技術と併せることによって,内容・形式に基づいた効果的な会議議論からの知識発見支援が期待される.
4 まとめと今後の課題
本論文では,蓄積された会議に関する情報から会議の構成要素である発言の意味関係を明確にするディスカッションオントロジー構築へ向けたアプローチとして,会議コンテンツの生成とメタデータの解析を行い,議論展開抽出や類似議論発見の手法について述べた.
今後の課題として以下のことがあげられる。
-
ディスカッションオントロジーにおける会議音声・映像の意味付け
-
類似するテーマや議論を持つディスカッション・グループの発見支援のための議事録公開環境の整備