
ディスカッションマイニング:会議からの知識発見
概要
対面式の会議は、効率的な知識共有活動の一つである。われわれの研究テーマは、会議風景のマルチメディアデータを含む議論内容のコンテンツを作成し、意味的な構造化を行うことでそれらの効率的な閲覧・整理・編集を可能にすることである。本論文では、議論コンテンツに対する構造化を会議中に行うための仕組みと、このコンテンツをネット上で共有し、ユーザーによるコンテンツの閲覧・整理・編集活動を通じた、オンラインでの意味構造化の仕組みを紹介する。
1 はじめに
われわれは日常の活動として会議に携わる機会が多い。何らかの問題事項に関して意思決定を目的とするものもあれば、お互いのアイディアを出し合いブラッシュアップするブレインストーミングを目的としたものまで、われわれは多種多様の会議に参加している。人間同士のコミュニケーションを中心とする社会の形成には、他者との意見交換の場となる「会議」は不可欠なものである。
さまざまな会議の中には、新しい考えを見聞きしたり、既存の考えを新しく捉えなおすことができるような有意義な会議もある。個々人の力を持ち寄ってシナジーを引き起こす会議もあるのである。そのような会議は、そのときだけでなく、後で思い出してみても、得るものは多いだろう。
そのようなよい会議はコンテンツとしても有効である。それは、たとえば、座談会の書き起こし文書を読んでみても、単なる解説記事よりも臨場感があって、異なる意見のぶつかりあいなどが読み取れる、等々、十分にコンテンツとして成立していることがわかる。
われわれは会議をコンテンツとする仕組みについて研究を行っている。会議といっても正確には研究発表会であり、要するに、研究室のゼミである。この風景を複数のカメラとマイクで収録し、オンラインで閲覧可能にするのである。われわれは会議の中で特に議論に着目し、議論構造をメタデータとして抽出し、会議風景のマルチメディアコンテンツと共に配信する。これを議論コンテンツと呼ぶ。
もちろん、会議をコンテンツとする、という試み自体は特に新しいものではない。そもそも、議事録は会議コンテンツと呼ぶことができるし、オンラインミーティングのログを取れば、それも会議コンテンツとなる。同様に、テレビ会議の映像と音声を保存しておいて、見直せるようにすれば、マルチメディア会議コンテンツとすることができる。
議事録はその会議における議論や決定事項の備忘録として有効なだけでなく、会議に参加していない第三者への会議内容伝達にも有効である。また従来では会議議事録はテキストで記録することが中心だったが、近年では、デジタル化された映像や音声などのマルチメディアデータを容易に取り扱うことが可能になり、音声・映像を会議議事録に取り込むことができるシステムも増えてきた。Leeらは、議論の様子を音声・映像情報として記録し、機械処理によるインデックス情報の付与を行っている。また、Chiuらは音声・映像情報の他に、発表時に利用されたスライド情報を組み合わせた議事録の作成を行っている。これらのシステムが生成する議事録では、会議参加者の話す様子や会議場全体の雰囲気などテキストでは表現することが困難であった情報も、音声・映像を用いて提供することができる。
しかし、マルチメディアデータに含まれる情報量は膨大なものであり、そこから議論理解・意味解釈を行うのはきわめて困難である。議事録の要約や特定の意味を含む議事録要素の検索といった技術を開発することで、閲覧者自身による情報処理を容易にすることができると考えられる。これらの技術を実現するには、会議の情報としてテキスト・音声・映像に加え、意味要素を含んだメタデータが有効である。
われわれは、オフラインの(つまり対面式の)会議風景を記録するだけではなくて、できるだけ多くのメタデータを会議中に作成する仕組みを開発し実践している。この場合のメタデータには、発表者の用いたスライドの内容とそれをスクリーンに表示した時間、発言者のIDとその発言時間、発言間の関係(前の発言を受けているかどうか。受けている場合は、肯定的か否定的か、など)、発言内容に含まれるキーワード、などが含まれる。このうち、発言内容のキーワードは書記が入力するのだが、それ以外は自動的に取得している。そのためのデバイスも作成した。それは赤外線信号を発信する札型のデバイスである。発言者は2種類の札のどちらかを選んで、真上に掲げてから発言を開始するのである。札から発信された信号はサーバーに伝わり、発言者のIDと発言タイプ、開始時間を記録し、同時に受光器の位置から発言者の位置を調べ、可動式のカメラをその人に向ける。
このメタデータと会議風景の映像と音声によって、かなり効率よく会議内容と状況を再現することができる。また、議論が活発でうまく会議が進行しているかどうかはメタデータを調べるだけで、だいたい知ることができる。定量的な評価はまだ困難であるが、メタデータのさまざまな特性を調べることで、その会議のうまくいっている部分とそうでない部分を、ある程度自動的に抽出することができるようになるだろう。
これを使うと、会議からさまざまな知識が獲得できるだろう。たとえば、ある提案に関する参加者の意見の違いから、その提案の持つ多様な側面が推論されたり、異なる会議で似たような質問が繰り返されたときに、その回答と合わせたFAQが作成されたり、議論が発散した場合は、その元になった発言が何か新しいアイディアを含んでいるかも知れないので、ブレインストーミングのネタとして利用されたりする。会議は人間活動の中でも特に頭脳労働的側面が強いので、その内容を機械によって利用可能にすることで、人間の創造性を強化できることは間違いがないだろう。
そこで本研究では、「会議」という人間活動にメタデータ(アノテーション)を付与することで議論を構造化して作成した議事録から、人間活動における意味情報の抽出を試みる。また、コンテンツとしての会議を再利用して、文書を作成したり、次の会議のためのスライド資料を作成するなど、知識活動を支援するための仕組みを構築する。会議は知識活動の中心的な役割を果たし、過去の会議と未来の会議をつなぐための活動は人間の知識の再生産を促進することになる。
2 新しい議論ツールと会議へのアノテーション
議論を構造化するために、図に示すようないくつかの議論ツールを開発した。一つは議論札と呼ばれる札型のデバイスで、もう一つはdボタンと呼ばれるボタンデバイスである。議論札は2 種類あって、赤と黄色に色分けされている。赤い方は、新しいトピックで議論を始めるときに、上に掲げてから発言を始める。黄色い方は、同じトピックのままで議論を続けるときに、やはり上に掲げてから発言する。dボタンは赤緑青3つのプッシュスイッチを持ち、発言者が発言を終了するときに緑を、その他の参加者が、現在あるいは直前の発言を支持するときに青を、その発言が理解できない、あるいはそれに同意できないときに赤を押す。緑は、発言者以外が押すときはマーキングの機能を持ち、あとでコンテンツを見直すときに栞の役割を果たす。これらのデバイスは赤外線の送信機能を持ち、各参加者の座席の上の方に設置された受信器にデータを送るようになっている。赤外線受信器はPCにつながっていて、データを受信すると同時にサーバーに転送する。また各受信器はその位置が登録されており、データを受信するとその位置に合わせて参加者をアップで撮れるようにカメラを向けるようになっている。さらに、それと同時に議事録作成用ツールに発言者の名前が表示され、発言内容をタイプ入力するフォームが生成される。

図1: 議論ツール
最近、以上のデバイスおよびレーザーポインタを1個の装置に集約するために、ゲームコントローラであるWiiリモコンを利用している。われわれが会議で使用しているWiiリモコンには、発言に関するメタデータを作成するためのタグ機能、発言中にスクリーン上の対象を指したり、スクリーン上に線を描いて説明を補助するためのポインタ機能、直前の発言に対する参加者の賛成・反対・中立などの態度を入力・集計するためのボタン機能を持たせている。
以下でこれらを順に説明する。
2.1 タグ機能
これまで、前述の議論札を使って、発言に関するメタ情報(発言者ID、発言開始時間、発言タイプ、発言者の座席位置)をリアルタイムに入力して記録していた。特に、発言タイプは、議論を構造化して、トピックごとのまとまりを発見するのに有効である。それで、Wiiリモコンにもその機能を持たせることにした。札を上げるという特徴的な行為を継承するために、リモコンを上に向けて掲げたときの高さや角度(ひねり)を使って、発言者の登録と発言タイプを入力する仕組みを実現した。これは、一般の会議で発言者が挙手をして、司会者に指名されてから発言を始めるのに近い行為である。
たとえば、図のようにリモコンを上に掲げると新規の発言が登録される。

図2: 発言の登録
発言が登録されると、図のようにサブディスプレイに反映される。
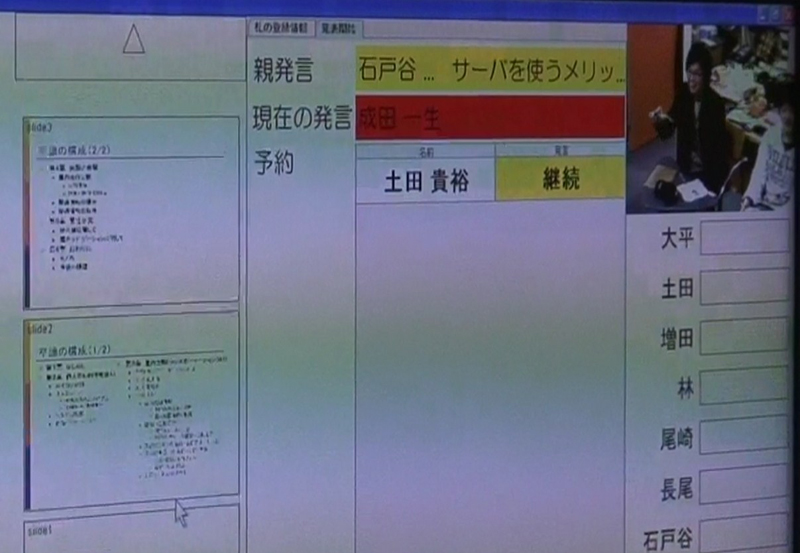
図3: 発言状況
登録した時点で、発言者がいなければ登録者はすぐに発言できる状態になり、誰かの発言中に登録した場合は、発言予約リストに加えられ、直前の発言が終了するとその人の順番になる(ただし、登録者が発表者かどうか、また、発言タイプによって、順番が変わることがある。自分が発言できる状態になったことは、リモコンの振動とサブディスプレイの表示でわかる)。サブディスプレイには、現在の発言者の映像や、発表者が過去に表示したスライドのサムネイル画像なども表示される。
前述のように発言には2種類のタイプがあり、赤く表示されているのは導入タイプ(話題を変えるとき)で、黄色で表示されているのは継続タイプ(話題を変えずに議論を続けるとき)である。これらのタイプは、リモコンを上に向けるときにひねりを加えて角度を90度変えると変更することができる。ちなみに、発言者の名前と発言タイプは自動的に、後述する議事録に反映される。
さらに、位置を表す赤外線IDを使って、登録と同時に発言者の座席位置がわかるような仕組みも実現した。これによって、天井に設置したパンチルトカメラを発言者に向けることができる。ちなみに、発表者はメインディスプレイの隣に座席が固定されているので、固定のカメラで撮影される。
2.2 ポインタ機能
Wiiリモコンには、もともと画面上の任意の部分をポイントして選択するダイレクトマニピュレーションのための機能が備わっているが、その実装の都合上、1つのディスプレイ上の操作に限定されていた。われわれの会議では、メインディスプレイ(プロジェクタスクリーン)とサブディスプレイ(大型液晶ディスプレイ)の複数のディスプレイを利用しているので、Wiiリモコンをマルチディスプレイに対応させる必要があった。
タグ(札)として用いるリモコンを図のように前に向けるとポインタとして利用できる。

図4: ポインタの利用
さらに、ポインタを使ってスクリーン上に線や図形を描くことができる。図は、スライド内の図に円や線を描きながら質問しているところである。
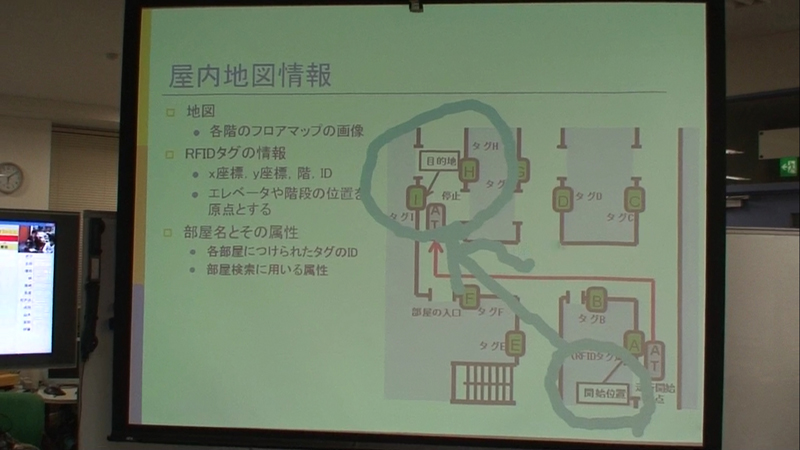
図5: 図形描画
全員がリモコンを持っているため、ある議論中に複数の参加者が同じスライドに印を付けることもある。たとえば、図のように、参加者のポインタは色分けされているので、誰がどの部分に言及しているのかわかるようになっている。
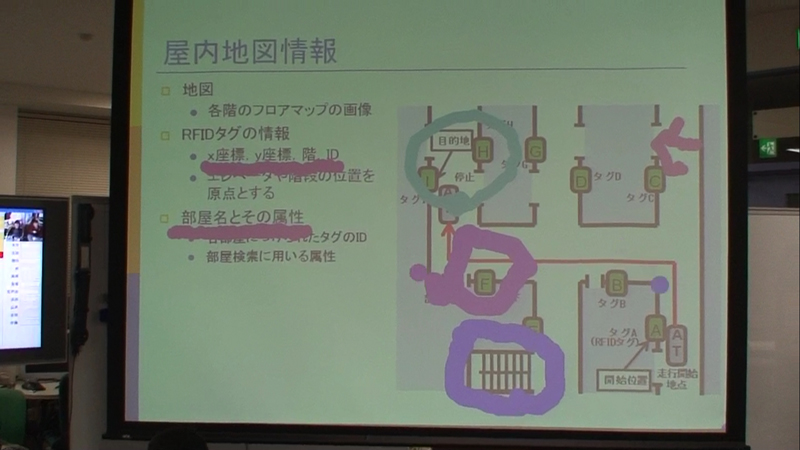
図6: 複数参加者による図形の描画
2.3 ボタン機能
ボタンは、参加者全員が非同期に、直前の発言に対して賛成・反対・中立の態度を表明したり、後で検索しやすくするために発言にマーキングしたり、任意のタイミングで多数決を取ったりするときに用いられる。以前は、前述のdボタンを用いて、この機能を実現していた。これは、3個のプッシュスイッチを持ち、それぞれを押す(2個同時に押すこともできる)と赤外線IDを送信するボタンデバイスである。Wiiリモコンには、11個のボタン(電源ボタンを含めると12個)が備わっているので、そのうちの5個のボタン(+ボタン、-ボタン、HOMEボタン、1ボタン、2ボタン)を使って、必要な機能に割り当てている。
サブディスプレイには、図のように参加者がボタンを押した状況が反映される。青は直前の意見に賛成、赤は反対、緑は中立を表している。
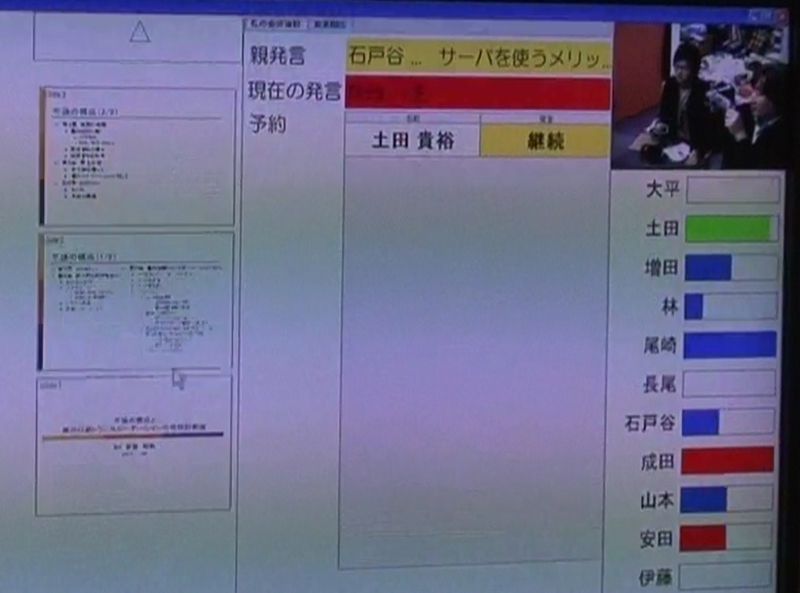
図7: ボタン状況
ボタンは、任意のタイミングで多数決をとるときにも使う。これは、発表者がツールを使って質問を設定すると多数決モードになり、その結果は図のように円グラフとしてサブディスプレイに表示される。
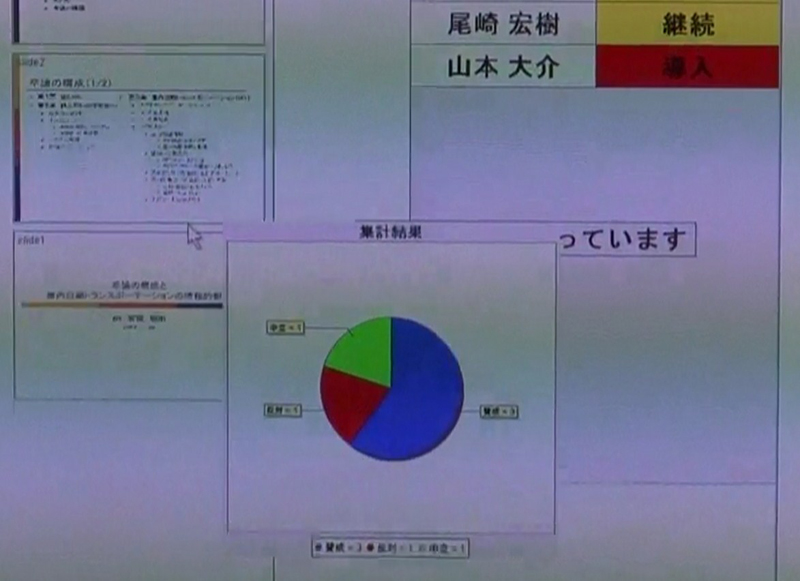
図8: ボタンの集計結果
また、サブディスプレイには以前にメインディスプレイに表示されたスライドの履歴が表示されているが、過去のスライドについて質問をしたいときに、図のように質問者がスライドのサムネイルをポイントして(サムネイルをポイントすると左側に拡大表示される)、Aボタンを押すと、そのスライドが選択されメインディスプレイに表示される。
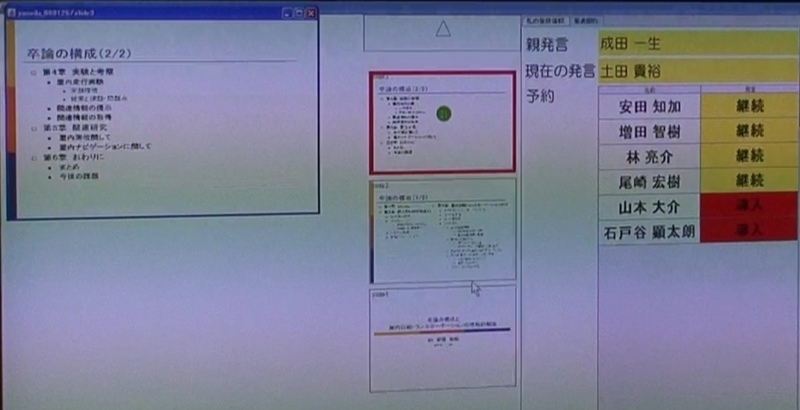
図9: 過去のスライドの選択
以上の3つの機能を備えることによって、Wiiリモコン1台で、われわれがこれまでに使っていた、議論札、レーザーポインタ、dボタンをすべて置き換えることができた。
また、当然ながら、発表者のスライド情報や発表中にスライドを切り替えた時間や、デモ等を行うときの時間や簡単な内容記述も記録して保存している。
重要なのは、われわれの議論ツールであるWiiリモコンが固有のIDを持つことができ、それゆえに、すべての行動を「誰が行っているのか」リアルタイムに識別可能であることである。従来のレーザーポインタはポインタにIDを関連付けることができなかったため、誰がポイントしているのか自動的に知る方法がなかった。この仕組みを使えば、誰がいつどのディスプレイのどの部分を指しているのか簡単にわかる。また、タグ機能によって発言者がわかり、その人が画面上のどのオブジェクトを指しながら発言しているのかわかる。
具体的には、PowerPointで作成されたプレゼンテーション資料からテキストやイメージの画面位置情報を抽出し、テキストならポインタが一定時間以上滞留した文字の情報、イメージならその内部にポインタが滞留した領域をリアルタイムに検出することができる。
3 議論コンテンツ
発言のテキスト情報の入力は自動認識ではなく、書記がタイピングしている。書記は、図のように、もう一つのサブディスプレイの隣に座っていて、ノートPCを使って議事録を作成している。サブディスプレイには、入力中の議事録が表示されている。

図10: 書記の作業風景
議事録ツールは、図のように、Webブラウザをインタフェースにしており、発表者のスライド情報、参加者のタグ・ポインタ・ボタン情報が自動的に反映されるようになっている。
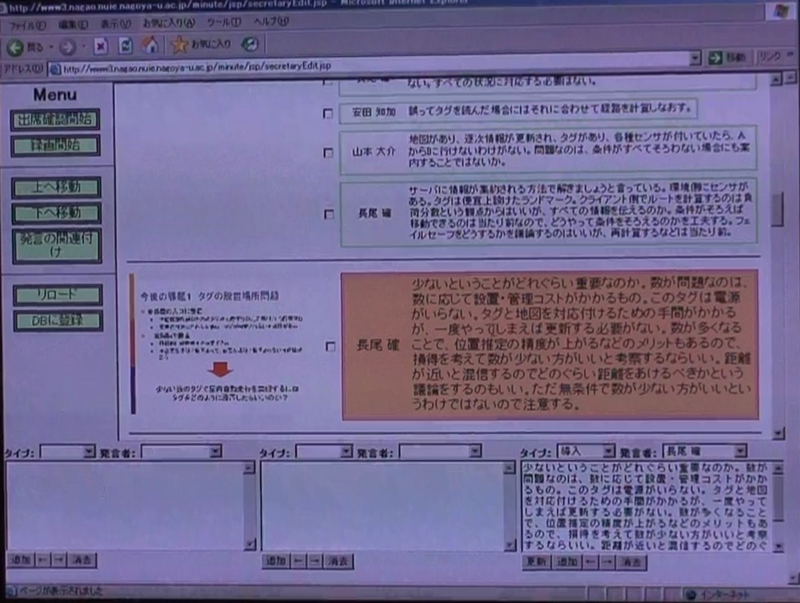
図11: 書記ツールの画面
会議中に収録・獲得されたすべての情報は、議論コンテンツに統合され、次に紹介するディスカッションメディアブラウザで利用できる。
さらに、ポインタ情報は発言に含まれる指示代名詞(「これ」「それ」など)の指し先を明確にしてくれるため、当然、発言の意味を詳細に分析するのに有効である。
3.1 ディスカッションメディアブラウザ
ディスカッションメディアブラウザはWebブラウザ上で動作する議論コンテンツ閲覧システムである。
このシステムは、図に示すように、3つのビデオプレイヤ、層状シークバーと呼ばれる複数レイヤを持つビデオシークバー、タブで切り替え可能なメインウィンドウ、コンテンツ内の検索用のサイドバーから構成される。
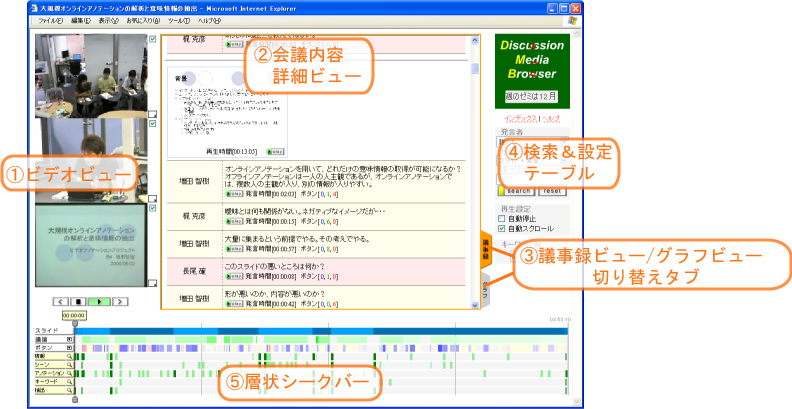
図12: ディスカッションメディアブラウザ
ビデオプレイヤは、上から、参加者映像、発表者映像、メインスクリーン映像(サブスクリーンはその場にいる人が見るだけのものなので記録していない)を表示している。層状シークバーは、スライドの切り替わり、各議論のセグメント(開始時間と終了時間)、どのボタンがどのタイミングで押されているかを示す情報、検索と連動して表示される検索結果の出現時間に関する情報、議事録内で頻出する単語の出現時間に関する情報(表示する単語数は検索サイドバーで変更可能)をそれぞれ異なる層のシークバーで表すものである。
ビデオの現在時間を表示するスライダーをドラッグするとビデオのサムネイルが変化してシーンを選択する手がかりとなる。また、シークバーの任意の部分をクリックするとその部分のビデオが再生される。クリックせずにマウスポインタをロールオーバーするとそれぞれのシークバーに関連した情報がポップアップする。
特に複雑なのは議論に関するシークバーで、任意の議論セグメントにマウスを当てると、その議論セグメントに含まれるすべての発言の発言者名と頻出キーワードなどが表示される(導入発言は特に重要なので、文字制限ぎりぎりまで表示する)。このポップアップウィンドウ内で発言者名をクリックするとその発言のビデオが再生される。
メインウィンドウは、テキストとスライドイメージを含む議事録表示と、議論のセグメントや発言間の関係をグラフ化した表示をタブで切り替えることができる。議事録ビューでは、スライドや発言がビデオとリンクしており、付随して表示されるPlayボタンをクリックすると該当する部分のビデオが再生される。キーワード検索するとマッチする部分がハイライトされる。
また、グラフビューでは、図に示すように、Flashを使って発言間の関係や議論セグメント間の関係が表示される。特に、その発言がどの導入発言に関連しているか、その発言と直接関連する発言はどれか、などが一目でわかるようになっている。当然、発言ノードはビデオとリンクされており、クリックすると該当する部分が再生される。
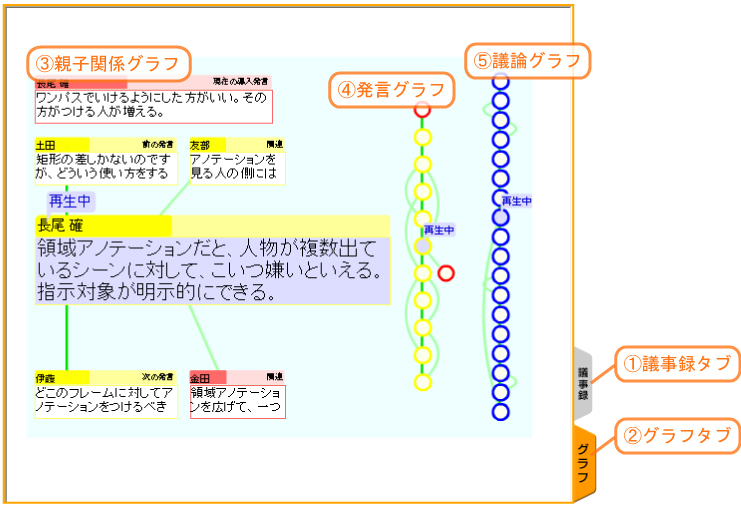
図13: グラフ表示
なお、メインウィンドウの内容は、ビデオの再生時間とシンクロして自動的にスクロール・ハイライトされる。
検索サイドバーには、その名の通り、検索要求を入力するフォームや、検索結果からビデオを見るためのボタン等が用意されている。また、参加者一覧がプルダウンメニューで示されており、特定の人の発言のみを簡単な操作で見ることができる。キーワード検索は、書記の記録した発言内容以外に、スライド内のテキストも同様に対象とすることができる。
4 知識活動における会議
会議をコンテンツとすることの利点は何だろうか。それは、繰り返し閲覧(視聴)して、内容をよく理解することができる点、検索や要約等のコンテンツ技術を適用できる点、さらに、テキストマイニング等の技術を使ってコンテンツから何らかの知識を発見できるかも知れない点である。
われわれは、オフラインの(つまり対面式の)会議風景を記録するだけではなくて、できるだけ多くのメタデータを会議中に作成する仕組みを開発し実践している。この場合のメタデータには、発表者の用いたスライドの内容とそれをスクリーンに表示した時間、発言者のIDとその発言時間、発言間の関係(前の発言を受けているかどうか。受けている場合は、肯定的か否定的か、など)、発言内容に含まれるキーワード、などが含まれる。
このうち、発言内容のキーワードは書記が入力するのだが、それ以外は自動的に取得している。
このメタデータと会議風景の映像と音声によって、かなり効率よく会議内容と状況を再現することができる。また、議論が活発でうまく会議が進行しているかどうかはメタデータを調べるだけで、だいたい知ることができる。定量的な評価はまだ困難であるが、メタデータのさまざまな特性を調べることで、その会議のうまくいっている部分とそうでない部分を、ある程度自動的に抽出することができるようになるだろう。
これをうまく使うと、会議からさまざまな知識が獲得できるだろう。たとえば、ある提案に関する参加者の意見の違いから、その提案の持つ多様な側面が推論されたり、異なる会議で似たような質問が繰り返されたときに、その回答と合わせたFAQが作成されたり、議論が発散した場合は、その元になった発言が何か新しいアイディアを含んでいるかも知れないので、ブレインストーミングのネタとして利用されたりする。会議は人間活動の中でも特に頭脳労働的側面が強いので、その内容を機械によって利用可能にすることで、人間の創造性を強化できることはほぼ間違いがないだろう。
4.1 会議間をつなぐ仕組み
ディスカッションマイニングによって作成された議論コンテンツを分類・要約する機能、そして新たに生まれた知識を議論コンテンツと関連付けながら記録する機能、そして蓄積された情報を用いた発表資料の作成支援機能を有するシステムがDRIP (Discussion,Reflection, Investigation, Preparation) Systemである。DRIP Systemはネットワークアプリケーションとして構築されており、常にサーバーと通信をしながら,ユーザーから入力された情報の登録や、ユーザーに対するメッセージの提示を行うことができる。
DRIP Systemでは、図に示すように、分類・要約された議論コンテンツに基づいて新たに生まれた知識をノートとして記録することができる。議論コンテンツビューの下にあるボタンをクリックすると、ノートを記述するためのエディタウィンドウが開く。その際,議論コンテンツビューとノートを記述するためのエディタウィンドウの間には、関連があることを示す矢印が表示されており、どのノートがどの議論に基づいて記述されたかを確認することができる。また、すでにあるノートのウィンドウに別の議論コンテンツビューをドラッグすることによって関連付けを行うこともできる。
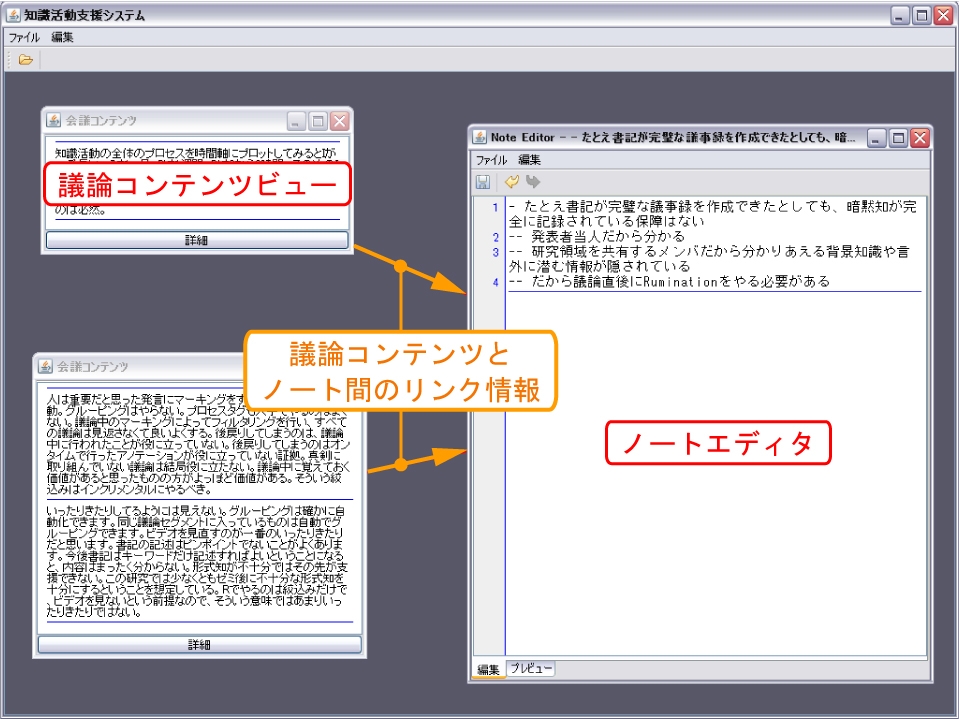
図14: ノート編集ツール
議論コンテンツに基づいて新たに生み出された知識を次回の発表資料に過不足なく盛り込むことは、次に行われる議論を活性化させ、知識活動へのフィードバックを高めるという点で有効なことであると考えられる。そのため、DRIP Systemでは蓄積したコンテンツを利用して発表資料の作成を支援する機能も備えている。ユーザーは図のようなインタフェースを用いて発表資料の作成を行う。このインタフェースでは以下の操作を行うことができる。
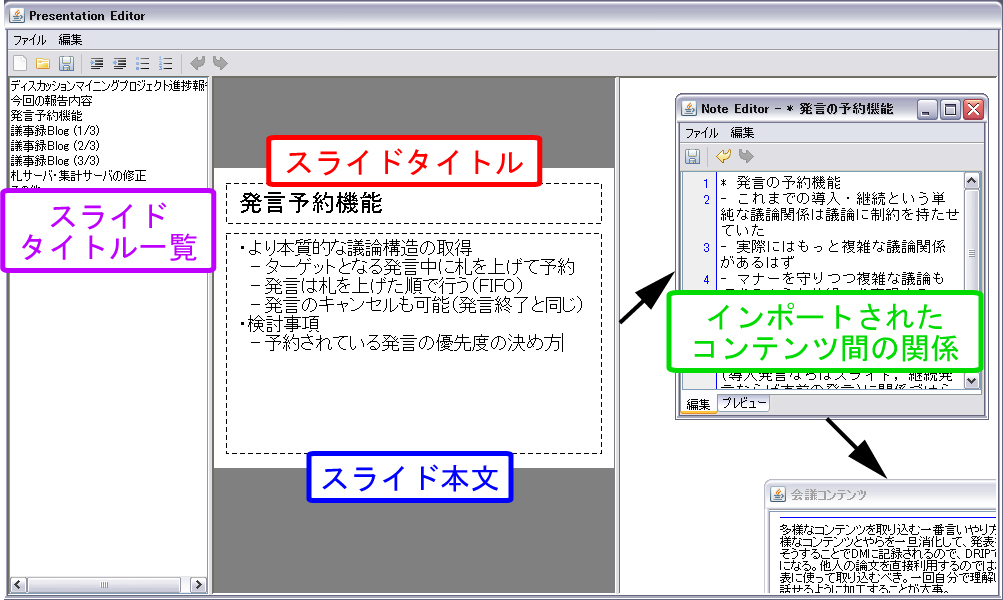
図15: スライド作成ツール
-
ページの作成,削除,入れ替え
-
蓄積したノートのページへのインポート
-
PowerPointスライドへの変換
ユーザーは、ページの作成・削除・入れ替えを行うことで発表の構成を編集する。ページとは、PowerPointのスライドのようにタイトルと本文を持ったまとまりであり、これまでに蓄積したノートの派生物である。過去の発表資料に使っていた構成を再利用することも可能である。
ユーザーは、これまで蓄積した知識を発表資料に取り込むために、インポート作業を行う。キーワードや日付をクエリとして、ページに取り込むノートの検索をする。日付をクエリとしてノートを検索した場合、検索結果としてその日からの編集履歴が表示される。これにより、過去の発表からの差分だけをページに取り込むことが可能となる。検索の結果、見つかったコンテンツをページ本文の編集エリアにドラッグすることによって、コンテンツの内容が自動的に挿入される。ユーザーは、この作業を繰り返し行うことで発表内容を完成させていく。
DRIP Systemは作成された発表内容を自動的にPowerPointスライドへ変換することができる。その際、生成されたスライドファイルと、作成時にインポートされたコンテンツに関する情報はサーバーへ送信・登録される。再びディスカッションマイニングを用いて発表を行うときは、発表資料だけでなくインポートに関する情報を利用することができる。
議論コンテンツとノートとを関連付けたり、ノートや議論コンテンツを用いてスライドを作成する機能を有している。ユーザーがこれらの機能を繰り返し利用することで、議論コンテンツやノートとの間には図のような関連性を見出すことができる。これは知識活動における文脈情報であると考えることができる。
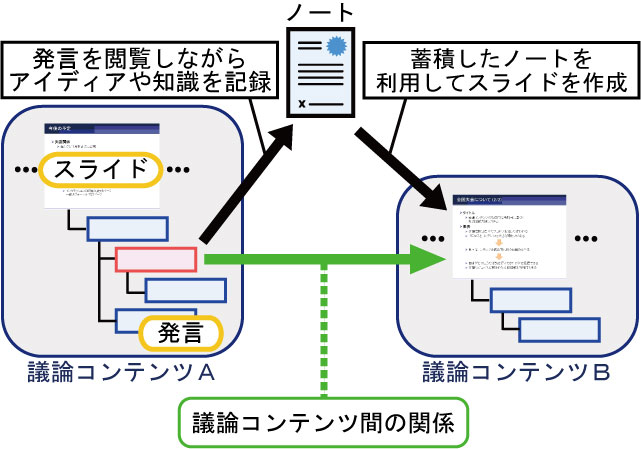
図16: ノートを介した議論コンテンツ間の関係
この文脈情報を効果的に閲覧できるインタフェースをディスカッションメディアブラウザ上で提供することによって、そのユーザーの知識活動に関する背景知識の獲得を支援することができる。知識活動を行っている本人が閲覧することで、現在までの活動の経緯やテーマにおける現在の活動の位置づけを確認したり、疎かにしていることを確認することができるため、より意義のある知識活動を行うことが期待できる。
また文脈情報を共有することによって、グループ内における知識の共有を支援することができる。たとえば、プロジェクトに新しく配属された人間は、そのプロジェクト内におけるこれまでの取り組みに関する知識はほとんどない。そのとき、他のメンバーたちの知識活動に関する文脈情報を閲覧することでより深い理解を促すことができるだろう。
FertigらのLifestreamsやGemmellらのMyLifeBitsのように人間の行動に関わるコンテンツをすべて記録し、それに基づいて追体験したり、記憶の想起を促すシステムに関する研究が行われている。しかし、これらのシステムでは,コンテンツ間の関連情報までは記録することは行われていない。われわれは追体験や記憶の想起を効率的に行うには、コンテンツ間の依存関係が必要であると考えている。
自然言語処理や画像処理などの機械処理によって、コンテンツ間の関連情報を自動的に取得する方法も考えられるが、機械処理による意味内容の解釈は困難であるため、その精度はあまり高いものではない。一方、われわれの仕組みでは、ユーザーの操作からコンテンツ間の関連性を暗黙的に獲得することができる。
5 おわりに
この仕組みの前提となるのは、われわれの作る議論コンテンツは多用途での再利用を考慮して作成されているということである。つまり、作成時に特定の応用のみを念頭に置いて行うことはない。当然、できるだけ詳細に内容を記述することが重要である。ただし、同時に会議時間内に作成作業がほぼ完了することを目指している。会議中の作業を参加者全員が協力して集中的に行うため、会議後の「人間の手による」作業を必要最小限にしている。そして、あたりまえのことだが、会議をするたびに議論コンテンツが増えていく。その使い道はいろいろである。ある者は、議論コンテンツをベースに論文を書くだろうし、他の者は、議論コンテンツ内で指摘された点を吟味してシステムを実装・拡張するだろう。
論文やプログラムは、本論文で述べた知識活動の副産物(あるいは派生物)である。あくまでメインの作業は、議論から次の議論へつないでいくことである。この作業を繰り返していくことで、過去の議論は未来に活かされ、自然にアイディアが熟成され、人々の知恵が集約されていくのである。
ちなみに、この議論コンテンツは筆者のライフログの一部になっている。一週間ごとの自分の様子が映像で見れるので、自分の顔や話し方を見て、議論と関係ないこと(髪を切った、いらいらしている、など)も思い出したりしている。
また、自分の発言の履歴を詳しく見て、一貫性に欠けていたりすると、反省したりしている。やはり、自分の発言には責任を持つべきだろうが、文章として残っていないものには、一般に注意が及ばず無視されがちである。だから、われわれは検索可能な状態で記録を残すことを重要視しており、記録を取っていることでこれまで以上に自分の発言に責任を感じるようになるとよいと思っている。