
閲覧時アノテーションを利用したWebドキュメントの引用とその応用
1 はじめに
引用は人間が意味を考慮して情報間を関連付ける作業であり,引用行為から得られる情報の有用性は高い. しかし,現在は引用されている文章の文脈情報や引用者の引用意図といった引用に関する意味的な情報は考慮されていない. これは引用情報が文書中のみに記述されていることに起因している. 引用箇所に対して自然言語処理を行い,引用に関する意味的情報を抽出するアプローチも考えられるが,引用箇所の記述形式も様々であり抽出は困難である.
本研究では,Webドキュメントの新しい引用の仕組みを提案している. 提案する引用の仕組みは,引用・被引用文書の関係を内部要素レベル(セクションやパラグラフ)で扱うことが可能であり,引用者の意図を明確に記述できる仕組みである. また,引用情報を引用・被引用文書の両文書のアノテーション情報として定義することで,文書の内部要素間を引用意図に関する属性により双方向に関連付けることが可能である.
本稿では,一般に文書を閲覧してから自身の文書を作成するまでに長期間が経過することを考慮し,閲覧時アノテーションと呼ばれる人間が文書閲覧中に付与するメタデータを用いた引用支援システムを構築し,実験を行った結果を報告する. さらに,得られる引用情報を利用した応用例として類似文書検索手法を提案する.
2 閲覧時アノテーションを利用した引用支援
2.1 閲覧時アノテーションと引用文書検索
我々人間は,文書を閲覧する際に文書の部分要素に対してマーキングやコメント付与といった様々なアノテーションを行う. 本稿におけるアノテーションとは,原著作者を含むすべてのアノテーション行為を行う人間がデジタルコンテンツの階層化などを目的とし,人為的に作成する二次情報を指し,機械的に生成される類の二次情報とは区別して考える. 本稿では,これらのアノテーションを総称して閲覧時アノテーションと呼ぶ. 文書を閲覧する目的が明確な場合には,閲覧時アノテーションは人間の自然な行為である. また,閲覧時アノテーションは文書中の重要箇所を記録するという目的で行われ,引用する文章の記録に利用されることがある.
そこで本稿では,ユーザの閲覧時アノテーションを記録し,アノテーションをトリガーとした引用文書検索手法を提案する. 本手法では,従来のように引用する文書を発見した後,文書中の引用する箇所を検索するという流れではなく,まず閲覧時アノテーションを検索し,引用箇所を直接的に探すことが可能である. また,過去に付与した閲覧時アノテーションを文章と共に参照することで,過去の文脈が想起され,文書の内容を容易に再理解することができる.
2.2 引用支援システム
本システムは,Webアプリケーションとして構築されており,ユーザはWebブラウザ以外の特殊なクライアントソフトを必要としない.
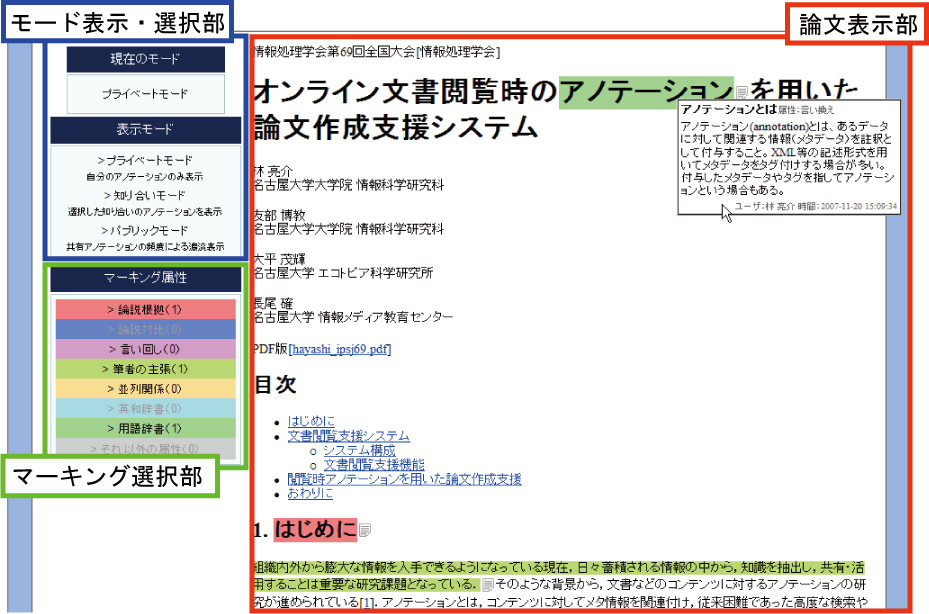
図1: 文書閲覧インタフェース
まず,本システムの文書閲覧インタフェース(図)について述べる. 本インタフェースでは,ユーザがWebドキュメントに対して閲覧時アノテーションを付与することができる. 可能な閲覧時アノテーションはマーキングとコメント付与である. まず,Webドキュメントをユーザに提示する前処理として形態素解析を行い,テキスト部分を形態素単位に分割し,言語構造に関するタグを付与する. 形態素単位にタグを付与することで,Webドキュメントの詳細な内部要素に対するアクセス手段を確保し,アノテーション範囲をXPointerにより指し示すことが可能になる. 本インタフェースではAjax技術を適用しており,ユーザは簡単なマウス操作によりアノテーションを付与することができる. また,閲覧時アノテーションには様々な属性情報を付与することが可能である.
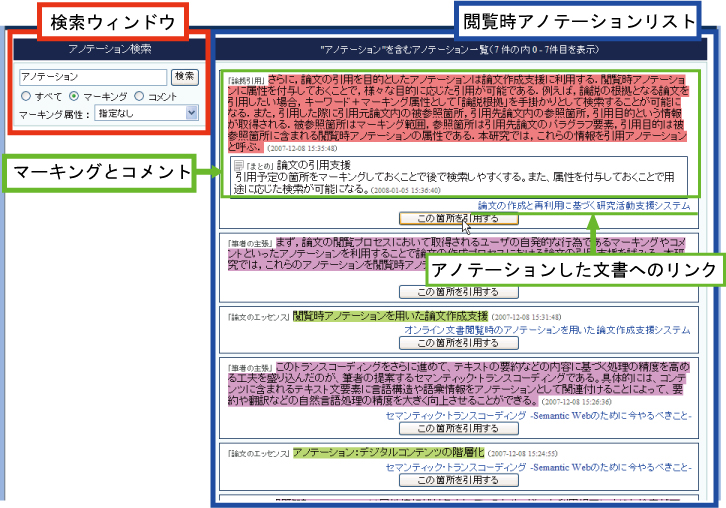
図2: 閲覧時アノテーションのリスト表示
次に,引用文書検索インタフェースについて述べる. 本インタフェースでは文書を作成する際に閲覧時アノテーションをトリガーとした引用文書検索が可能である. 図のように閲覧時アノテーションはリスト形式で表示され,キーワードと閲覧時アノテーションにおいて付与した属性情報を用いて検索することが可能である. 例えば,自己の主張の新規性を示すために,他者の主張と対比して書きたい場面がある. その場合,あらかじめ文書閲覧中に対比したい文書の該当箇所をマーキングし,自己の主張との差分をコメントとして記述し,問題点属性を付与しておく. その後,実際に文書を作成する際に,コメントの問題点属性を指定して検索することで,目的に合った箇所のみを収集することが可能である.つまり,アノテーション属性とキーワードを指定することにより,ユーザの文脈に適したアノテーションを検索することが可能である.
2.3 実験と考察
引用支援手法の有効性を示すために被験者実験を行った. 10名の被験者に2つのグループに分かれてもらい,本システムを用いて文書を作成してもらった. Aグループには文書閲覧時にアノテーションしてもらい,Bグループにはアノテーションしてもらわず,文書を作成時に適切な文書を引用してもらった. 引用対象としたWebドキュメントは,本研究室で公開している情報科学に関する日本語論文であり,その総数は57本であった.
本実験では,2つのグループにおける引用コストを比較した. 引用コストとして,引用1回あたりの引用文書検索に費やした時間を採用した.
実験結果を表に示す. ユーザが引用箇所を検索した平均回数はAグループが3.86回であり,Bグループは5.33回であった. 閲覧時アノテーションを記録・検索可能にすることで,引用1回あたり68.5秒の検索時間を短縮でき,有効性を示すことができた.
3 引用アノテーションに基づく類似文書検索
本システムを運用することで,引用アノテーションと呼ばれる情報がシステムに蓄積される. 通常,引用情報とは引用文書内にテキスト形式で含まれるものであるが,本研究では引用情報を引用文書と被引用文書の両文書のアノテーション情報であると捉え,文書に埋め込まれないXML形式で管理する. 引用アノテーションは,主に引用文書の引用箇所,被引用文書の被引用箇所,引用意図に関する属性の3つの情報を保持する. 従来の引用情報のように単純に文書間を関連付けるだけでなく,文書の部分要素間を引用意図で関連付けることから,文書間の関係をより意味的に表すことができる.
従来から共引用(Co-citation)と呼ばれる関係を利用した文書間の類似尺度が提案され,類似文書検索に利用されている. 共引用の関係とは,同一の文書によって引用された文書同士の関係を指し,この関係にある文書同士には類似性があるとされている. しかし,従来の共引用による類似度の算出では,共引用の関係にある被引用文書同士の類似度は全て同じとされており,引用に関する意味的な情報は考慮されていない.
そこで本研究では,引用アノテーションを利用して共引用の関係をより詳細に扱うことを試みる. 具体的には,引用文書の引用箇所間の関係と引用意図に関する属性情報の関係を利用した類似文書検索手法を提案する. 以下に,類似文書検索に利用する文書と
の類似度
の算出式を示す.
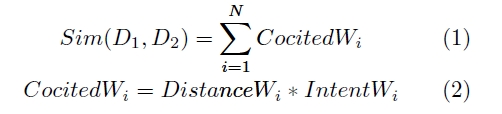
図3: 類似度の算出式
式(1)におけるは文書
と
の共引用回数であり,
は共引用の関係に基づく値で式(2)で示す.式(2)における
は,共引用の関係にある引用箇所を含む要素間のXPathのステップ数の逆数であり,引用箇所間の距離が近いほど大きくなる値である.XPathのステップ数とは,例えばXPathが"/papers[1]/docbody[1]/section[1]/para[1]"と"/papers[1]/docbody[1]/section[1]/para[2]"なら2となり,"/papers[1]/docbody[1]/section[1]/para[1]"と"/papers[1]/docbody[1]/section[2]/para[1]"なら4となる値である.また,
は共引用の関係にある引用同士の引用意図が同じか否かに応じて与えられる0以上1以下の定数であり,引用意図が同じ場合に大きくなる.つまり,類似度
は,引用箇所間の距離が近く,引用意図が同じ共引用の回数が多いほど大きくなる値である.本手法では,類似度
の大きい順に文書を提示する.
4 おわりに
本稿では,閲覧時アノテーションと呼ばれる情報を引用文書検索する際のトリガーに利用することを提案し,実験・評価した. また,本システムを運用することで得られる引用アノテーションの応用を類似文書検索を例に示した. 引用アノテーションに基づく文書間のネットワークは従来のハイパーリンクに基づくネットワークに比べて,より深い意味的関係を反映したものになることが予測され,類似文書検索以外にも様々な応用に適用できるであろう.
今後の課題としては,類似文書検索手法の評価などが挙げられる.