
議論内容の獲得と再利用に基づく知識活動支援に関する研究
概要
企業におけるプロジェクトや大学研究室の研究活動のように、ある特定のテーマに関するアイディアを継続的に創出し、具体化・理論化する知識活動が広く行われている。知識活動には、調査や実験、検証といったプロセスが存在し、それぞれのプロセスが相互に関係しながら繰り返し実行されることによって新しいアイディアや知識が創出される。このようなプロセスの一つである議論は知識活動の中で重要な役割を果たしている。日々の知識活動を通じて蓄積してきたアイディアや知識を他者に向けて発表し議論を行うことによって、意見やアドバイスなどのフィードバックを獲得することができるからである。
本研究では、議論内容を記録した会議コンテンツの効率的な再利用によって、知識活動の活性化を目指している。そのために、知識活動を、議論を中心とする4つのフェーズから構成されるサイクルとして捉え、これをDRIPサイクルと呼ぶことにする。そして、DRIPサイクルにおける会議コンテンツの作成と再利用の過程について考察を行った。さらに考察に基づき、知識活動サイクルの活性化を促すシステムの構築を行った。
まず、ディスカッションマイニングと呼ばれる技術を用いて会議コンテンツの作成を行う。ディスカッションマイニングでは、議論の様子を映像・音声に記録し、発言者IDや発言時間、発言内容のテキストなどのメタデータによって議論の意味構造化を行う。そして、作成された会議コンテンツを効率的に閲覧するため、発表者の解釈に基づき会議コンテンツに対してアノテーションの付与を行う。会議コンテンツに基づいて創出されるアイディアや知識は、複数の会議コンテンツにわたり系統立てて記録・蓄積され、議論以外の知識活動と会議コンテンツとを密接につなぐと同時に、それらの検索や閲覧を容易にすることで知識活動の効率を上げ、以降の議論のための資料作成などに活用される。知識活動支援システムを用いてDRIPサイクルを繰り返し行うことによって、システムを利用している人間の知識活動が、過去の議論を適切に反映した、より密度の濃い効率的なものになると考えている。
1 はじめに
近年、IT革命という言葉に代表されるようにコンピュータやインターネットなどの情報技術の急速な発達に伴い、労働集約的な生産活動よりも知識集約的な生産活動が重視されるようになってきた。このような社会では、個人の持つ知識を組織全体の知識として共有・再利用し、新たな知識を効率的に創造できる仕組みが必要になる。
ナレッジマネジメントでは、形式的言語では表現できない主観的・経験的な知識である暗黙知と、形式的言語で表現可能な客観的・理性的な知識である形式知が、個人・集団・組織の中で絶え間なく相互に作用しあうことによって知識が創出されるという考え方がある。野中らは、暗黙知と形式知の相互作用によって知識が創造される過程をSECIモデルと呼ばれるモデルによって説明している。SECIモデルでは、共体験などによって暗黙知を獲得・伝達する共同化(Socialization)、得られた暗黙知を共有できるように形式知に変換する表出化(Externalization)、形式知同士を組み合わせて新たな形式知を創造する連結化(Combination)、利用可能となった形式知を基に個人が実践を行い、その知識を体得する内面化(Internalization)という4つのプロセスが繰り返し行われることによって、個人、そして組織の知識はより高いレベルに昇華される。また、データマイニングやデータウェアハウスなどナレッジマネジメントを情報技術によって支援する研究も広く行われている。
形式知となった知識を材料にして体系化および総合的な知識を生み出す連結化を実現するための手法としてグループウェアがある。グループウェアは、CSCW (Computer Supported Cooperative Work)と呼ばれるコンピュータによる協同作業支援に関する学術分野に基づくシステムの総称であり、具体的なものとしてはサイボウズ†やアイポ†などが挙げられる。これらのシステムには、組織内部や外部とのコミュニケーションを円滑に行うためのWebメール機能、メンバーとスケジュールを共有するスケジューラ機能、メンバー間の打ち合わせや議論を行うための掲示板機能など組織内の知識創出を支援する様々な機能が存在する。グループウェアの有用性は徐々に認識されており、民間企業の約半分がグループウェアを導入しているという調査結果も報告されている†。
しかし、グループウェアが広く普及する一方、「うまく情報が集まらない」「情報を蓄積しても有効に活用できない」といった問題点も指摘され始めている。組織内のメンバーには情報を探したり配信する時間的な余裕がないため、ダベンポートは、業務に知識を埋め込んだシステムの必要性を説いている。また小林は、これまでのナレッジマネジメントシステムで蓄積される情報は設計書や提案書など業務に関する成果物だけであり、「どのようにしてその成果物が作成されたのか」という成果物に至るまでの背景情報が蓄積されていないために、組織内で培われた知識がメンバー間で効率的に継承されない点を指摘している。このことから筆者は、過去に行ってきた作業内容を管理し、SECIモデルにおける4つのフェーズにおいて効率的に活用できる仕組みを実現する必要があると考えた。
そのための導入として会議に着目した。会議は、組織内のメンバーが互いに意見交換を行うことによって個人の暗黙知を獲得・伝達する共同化にあたる作業である。近年、会議はクリエイティブな活動であるという認識が広まっている。そして、これまでに行われてきた形骸化された会議そのものを見直すことに注目が集まっている。これまでの会議には、その目的が不明瞭である、議論を先延ばしにする、立場の低いものが発言しにくい雰囲気があるなど様々な問題点があったが、これらの問題点を解消するためのノウハウを紹介する書籍などが多く出版されている。斎藤はこのようなノウハウを「十の法則」としてまとめ、これらの法則に基づき独自の会議スタイルである「三つの革命」を提案している。また、株式会社サルガッソーのeXtreme Meetingでは、「会議はそもそも議事録を共同で作成する作業である」という定義に基づき、会議参加者全員で議事録を共同で作成するWebツールを提供している。また、アイディアを出す会議において有効的な記録方法としてマインドマップがある。これは、中心となるトピックから線を引き、その線の上にそのトピックから派生するテキストや図を書き足すことで非線形・放射状のマップを作成し、人間の発想を支援する手法である。もとは紙とペンを用いてマップを作成する手法だったが、情報技術の発達に伴い、コンピュータ上でマップの作成を行うツールが提供されている。
会議を通じて獲得・伝達された暗黙知は、表出化を通じて議事録などの形式知として記録される。記録された形式知同士を組み合わせることで新たな形式知が創出され、さらに内面化によって個人の暗黙知として習得される。そして再び会議を行うことによって新たな暗黙知を創出していく。このように会議は繰り返し行われるため、過去にどのような議論が行われていたのかという背景情報をメンバー内で正確かつ効率的に共有することが重要である。
議論を繰り返し行う中で重要になることは、議論後に行った活動の内容が次の議論に活かされていることである。そのためには、議論の内容を自分の中で消化した上で新たなアイディアや知識を創出し、その内容を踏まえた発表をすることが望ましい。そして、議論内容を自分の中でしっかりと消化するためには、議事録をただ記録・閲覧するのではなく、議事録を一度分解し、自身にとって必要な箇所を抜き出して、再構築することが必要であると考えた。本研究では、議事録を分解・再構築し、そこから新たなアイディアや知識を創出したり、以降の発表に用いる資料に取り込むことを``再利用''と定義している。そして、議事録の再利用を実現するためには再利用可能な議事録の作成を行う必要がある。
議論内容を記録した議事録を作成する方法として、人間が手動で行うものとコンピュータによって自動的に行うものの2種類が考えられる。前者の例としては、速記のように議論内容を特別な符号を用いて書き取り、後から通常の文字に書き直す方法や、テープレコーダで録音して後から書き起こす方法があるが、これらの方法は人間の負担が大きいという問題がある。逆に映像・音声を用いて議論の様子を自動的に記録する方法は、人間の負担を軽減することができる。そして、映像・音声情報を後から検索する際に必要になるインデックス情報を、音声処理や画像処理といった機械処理を用いて作成する研究も数多く行われている。しかし、現在の機械処理による認識精度は決して高いものであるとは言えない。また、議事録を効率的に閲覧するためには、発言を単に羅列するのではなく、議論に含まれる話題や発言間の関係といった意味情報を抽出することが望ましいが、コンピュータに意味解釈を行わせることは困難である。
つまり、人間の負担を減らすために計算機が記録の補助を行い、コンピュータの精度を高めるために人間が補助を行うという人間と機械の共同作業が、再利用可能な議事録の作成にとって現実的な解決策と言える。筆者の所属する研究室では、ディスカッションマイニングと呼ばれる、人間同士の知識交換の場であるミーティング活動から実世界情報を獲得し、それらを半自動的に構造化することによって、再利用可能な知識を抽出する技術の研究・開発を行っている。ディスカッションマイニングでは、数台のカメラやマイクによってミーティングの様子を映像・音声情報として自動的に記録し、さらに発言を行うときには専用のデバイスを人間が操作することによって、発言時間などのインデックス情報や発言間の関連などの意味情報の付与を行うことによって再利用可能な議事録の作成を行っている。
しかし、どれほど再利用に適した議事録を作成したとしても、その議事録が適切に再利用され、知識活動に反映されなければ、議論内容を踏まえた活動を行うことはできない。さらに議論内容を踏まえていない状態のまま、次の議論に臨んだとしても、冗長な議論や真に議論すべきことから逸脱した議論が多くなり、その後の知識活動が円滑に行われない可能性がある。
それでは知識活動を円滑に行うために必要な議論内容の再利用とはどのようなことだろうか。筆者は、ディスカッションマイニングシステムの現状の利用形態に着目した。ディスカッションマイニングシステムで作成された議事録は随時データベースに登録され、議事録集合を一覧し、選択的かつ容易に内容を閲覧することができる。また、閲覧した議事録をキーワードや発言者、発表日時などで検索する仕組みも提供されている。しかし、議論の回数を重ねれば重ねるほど当然ながら蓄積される議事録の数も増加し、閲覧したい議事録を探すことが困難になってくる。さらに時間の経過に伴い、過去の議論内容を忘れてしまい、閲覧したい議事録をピンポイントに特定可能な検索クエリを導き出すことが困難になる。また、検索結果を一つ一つ調べて、どれが該当する議事録なのかを確認する作業も必要になる。
作成された議事録には重要な議論もあればそうではない議論も混在している。効率的な議事録の閲覧を実現するためには、これらの議事録の中から真に必要となる議論だけを取り出す作業が必要であると考えた。しかし、これまで作成した議事録は主に参加者を含む一般向けのコンテンツであったため、自分にとって大事な発言はどれなのか、またその発言が自身の知識活動の中でどのような位置づけになるのかといった個人的な情報を付与することができなかった。そこで本研究では、ディスカッションマイニングシステムによって作成された議事録に対して、重要な議論に対して自分の解釈を付与することで、その後の活動において有効的に再利用できると考えた。発表者が、自身の発表について行われた議論の内容を反芻し自分なりの解釈を付与する行為は、必要とする議論を探し出す作業において、解釈の付与されていない議事録を探すことに比べ負担を軽くするはずである。
自分の解釈を付与した議事録を閲覧しながら創出されたアイディアや知識を発表し、議論することによってさらなるフィードバックを得ることができる。そして、より多くのフィードバックを得るためには、それらアイディアの検証や知識創出の経緯を含む自身の活動内容を過不足なく正確に他者に伝達する必要がある。つまり、知識活動には議論を行う段階や議事録に対して解釈を付与する段階の他にも、議事録を再利用しながら知識やアイディアを蓄積していく段階と、よりよい議論を行うための準備をする段階があることが考えられる。そして、それぞれの段階が相互に関係しながら繰り返し行われることで知識活動は発展していく。本研究では、この4つの段階から構成されるサイクルとして知識活動を捉え、そのサイクルの中で議事録がどのように関わりを持つのかを分析し、知識活動を支援するシステムの構築を目指す。
このようなシステムによって、自分が重要であると感じた議論に基づいて新たなアイディアや知識を創出し、蓄積することが可能になる。その結果、議論に関連づけられたアイディアや知識の量によって、自分がどの議論を集中的に扱っているのか、また逆にどの議論を疎かにしているのかを把握することが可能になる。当然ながら単純に関連づけられたアイディアや知識の量のみでは、議論と活動の密接度や活動の成熟度を測ることは不可能である。しかし、更新期間や更新頻度など様々な情報を組み合わせることによって、それらの評価を行うことが可能であると考えられる。また、議論に基づいて創出されたアイディアや知識を活用して次の議論を行うことによって、議論間に何らかの関係が見出すことができ、この関係を用いて議論に参加していなかった人間でも議論の背景を把握できる仕組みを実現することができる。
さらに本論文で提案する知識活動支援システムを繰り返し利用することによって、重要発言の発見や議事録間の関係の抽出といった知識発見にも貢献できると考えている。ディスカッションマイニングでは、これまで人手で入力した発言テキストや発言に含まれるキーワードの数、発言者のID、発言時間といったメタデータを用いた機械学習によって、重要発言の抽出などを目指してきたが、その精度はあまり高いものではなかった。しかし、知識活動支援システムを繰り返し利用することによって、発表者の知識活動に影響を及ぼした議論が容易に抽出できるようになる。さらに、解釈を付与した議論から新しいアイディアや知識を創出し、そのアイディアや知識を発表に活用することによって、議論間の関係を抽出しやすくなるだろう。これらのデータは、発表者が議論内容を意味的に解釈した上で付与したものであるため、正確な意味情報の抽出が期待できる。そして抽出された意味情報を用いて、複数議事録にまたがった要約や簡約、「誰がどの分野に詳しい」かが分かるKnowWhoといったより高度な応用を実現することができる。
本論文では、以上の考察に基づいて、議論内容に基づく知識活動の支援を実現するために必要となる、議論内容の獲得と再利用に関する研究成果について述べる。
本論文は本章を含めて8章から構成される。第2章では知識活動を議論中心のサイクルとして捉え、知識活動と議論内容の獲得・再利用との関わりについて述べる。第3章ではディスカッションマイニングによる会議コンテンツの作成とその利用法について述べる。第4章では作成された議事録を用いて知識活動サイクルを支援する仕組みについて述べる。次に第5章では、知識活動サイクルの特徴でもある再認(Rumination)フェーズと呼ばれるフェーズの必要性を確認するための実験に付いて述べる。そして、第6章では議論内容の獲得と閲覧に関する研究について述べる。第7章では本研究の今後の課題と展望について述べ、最後に第8章で本研究のまとめを行う。
2 知識活動サイクル
本研究は、議論内容に基づく知識創出の支援を目標としている。そのためには、本研究が対象とする活動がどのようなものであるかを明確にする必要がある。そして、その活動に内在する様々なプロセスにおいて、議論がどのように位置づけられるか、他のプロセスとどのような関係があるかを考察する必要がある。
本章では、まず知識活動と呼ばれる、本研究が対象とする活動の定義について述べた後に、知識活動における議論の重要性とその再利用性について解説する。そして、知識活動を議論中心の複数フェーズから構成されるサイクルとして捉え、それぞれのフェーズにおいて議論内容がどのように記録・利用されるかを考察する。
2.1 知識活動とは
知識創造企業やナレッジマネジメントなどの言葉に代表されるように、現代社会における知識の重要性が高まっている。今後、どのようにして質の高い知識をより多く創出・管理できるかが重要になると予想される。
野中らは、知識創造の枠組みには認識論的次元と存在論的次元の2つの次元があることを指摘している。認識論的な次元では、知識には形式的言語で表現可能な形式知と表現不可能な暗黙知の2つがあり、これらの知識が相互作用することによって知識が創造される。この形式知と暗黙知の相互作用はSECIモデルと呼ばれ、以下の4つのプロセスのスパイラルとして表現される(図)。
-
共同化(Socialization)
経験を共有することによって、個人の暗黙知からグループの暗黙知を創造するプロセス
-
表出化(Externalization)
暗黙知をメタファ、コンセプト、モデルなどの共有できる形式知に変換するプロセス
-
連結化(Combination)
共有された形式知を組み合わせて新たな知識体系を創り出すプロセス
-
内面化(Internalization)
行動による学習によって形式知を暗黙知として体得するプロセス
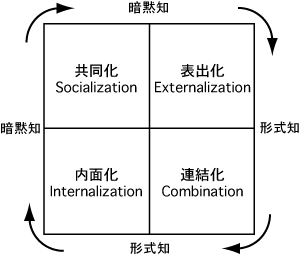
図2.1: SECIモデル
また、存在論的な次元では、個人が創造した知識が組織的に拡張され、グループや組織内、そして組織間にわたる知識として結晶化される。この過程は共同化に相当する暗黙知の共有から始まる。そして、共有された暗黙知は新しいコンセプトという形の形式知へ変換される。そして、変換されたコンセプトが追及する価値があるかを示すために正当化を行った後に、プロトタイプなどの原型の作成をする。このようなプロセスを通じて構築された知識はグループや組織、そして組織外へ移転される。このような1)暗黙知の共有、2)コンセプトの創造、3)コンセプトの正当化、4)原型の構築、5)知識の移転という5つのフェーズを経ることによって、スパイラルが生まれ、個人の知識が組織の知識として変換されていく。そして、2つの次元における知識スパイラルが複合的に実践されることによって、組織的な知識創造が行われる。
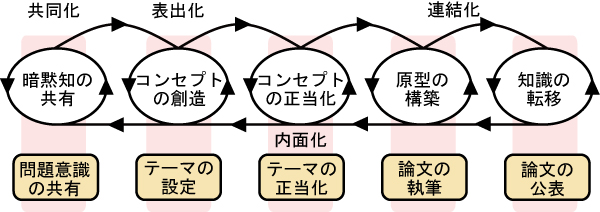
図2.2: 組織的知識創造プロセスと研究活動
野中らは、企業組織における知識創造を中心に述べていたが、視野を広げて捉えれば研究活動にもこの考え方を適用することができる(図)。研究活動では、新たな問題点や未解決の問題点に対するテーマを設定し、独自の視点から解決策を提案する。そして、実験・検証を通じて自身のテーマの妥当性を確認し、その成果を論文にまとめて公表する。論文を公表することによって、関連する分野の研究者の中で研究成果が共有され、新たな問題点が指摘されたり、新たなアプローチが提案される。そして、このプロセスが繰り返し行われることによって、社会に貢献するような技術が生み出される。このように企業組織における知識創造や研究活動には何らかの共通点が存在しており、その共通点を踏まえることによって、より広範囲な知識創出支援を実現できると考えられる。
本研究では、企業組織における知識創造や研究活動に共通する点は、テーマ(コンセプト)の一貫性だと考えている。例えば、企業で新たな商品コンセプトが生み出されれば、企業内のメンバーがそれぞれの視点からそのコンセプトを満たすためのアイディアを出し合い、まとめていくことによって新しい商品が生み出される。また、研究活動では、いまだに解決されていない問題点を研究のテーマとして扱う。その問題点を解決するために独自の視点からアプローチを行い、新たな知識や技術を生み出していく。本研究では、企業組織における知識創造や研究活動のように「あるテーマに対して継続的にアイディアを創出し、知識として理論化・具体化する活動」を知識活動と呼び、情報技術を用いることによって知識活動を支援することを目指す。
また知識活動は、個人で行うものと複数人のグループで行うものの2種類が存在する。グループの知識活動も突き詰めれば、個人の知識活動の組み合わせと捉えることができる。グループの知識活動には、テーマに対する認識の共有やメンバー間の進捗状況の把握など、個人の知識活動には存在しない要素が存在することは確かだが、グループを構成する個々人の知識活動を支援することで、結果としてグループの知識活動を支援することができると考えられる。そのため、本研究では個人の知識活動に着目し、その支援を目指す。
2.2 議論の重要性と再利用性
前節では、知識活動が形式知と暗黙知の相互作用によるスパイラルとして表されることを述べたが、そのスパイラルの中には調査や実験・検証、議論といった様々なプロセスが内在する。たとえばテーマを実現するために必要な情報をWebや書籍、論文といった文献を調査したり、アイディアの妥当性を確認するために実験を行う。そこで得られた実験の結果を検証することによって新たな問題点が見つかったり、新たなアイディアや知識が生まれる。こうして蓄積されたアイディアや知識を論文やスライドなどのドキュメントにまとめ、他者に向けて発表し、議論することで活動に対するフィードバックを獲得することができる。そして、フィードバックを活かして新たな調査や実験・検証などを行っていく。このように知識活動に内在するプロセスは、独立に行われるのではなく、相互に関係しながら繰り返し行われていく。
本研究では、知識活動に内在するプロセスの一つである議論に着目する。ここで述べる議論とは、自身がこれまでに行ってきた活動の内容を他者に向けて発表し、さらに自分だけでは解決できないような問題点等について意見を出し合う行為をさす。例としては大学研究室におけるゼミが挙げられる。議論は以下の2点の理由から知識活動の中で重要な役割を果たしていると考えられる。一つは自身がこれまでの知識活動を通じて培ってきたアイディアや知識を他者に向けて公表する点であり、もう一つは議論に参加している人間が様々な視点から意見の交換を行う点である。
知識活動を通じて創出されたアイディアや知識は、活動を行っている本人だけが所有するのではなく、社会に向けて提供することによって、さらなる価値を持つことになるだろう。そのため、複数の人間を集め、アイディアや知識を公表する場を提供するという点で議論を行うことは非常に意義のあることである。また、発表を行うための話し方や議論展開の方法、発表に用いるスライドの作成方法など、よりよい議論を行うためのノウハウを集めた書籍が数多く出版されている。そして、Microsoft PowerPointやOpenOffice.orgImpressに代表されるような、発表に使用するスライドの作成や発表そのものを支援するプレゼンテーションソフトも広く普及している。このようによりよい発表を行おうという試みも、知識活動において議論が非常に重要なものであるということを裏付けているだろう。
ゼミや学会発表のように、議論に参加している人間は類似するテーマに関心を持っていることが多く、それぞれ独自の考え方や方法に基づいて知識活動を行っているだろう。つまり、発表のテーマに関して様々なアイディアや知識を持った人間が、議論の中で様々な質問やアドバイスを行うことによって、発表者はその後の知識活動をよりよくするためのフィードバックを獲得することができる。例えば、「あなたのやっていることに関係のあるものとして、こういうものがあるので参考にして欲しい」と、自身の知識活動に関連のあることを指摘されれば、その内容を調査することによって、新しい知識の獲得や自身の知識活動の社会的な位置づけの把握をすることができる。このように議論で行われた内容は、その後のプロセスに様々な影響を及ぼす。
しかし、議論に関する経験的な問題点として、過去に行った議論と同じ内容の議論を繰り返してしまったり、過去に指摘された点がその後の活動に反映されないといったものが挙げられる。その原因として考えられるのは、時間の経過と共に過去に行った議論の内容を忘失してしまうことである。その時は先の話として保留しておいた議論が次第に忘れ去られてしまい、結果として真にその議論が必要な時に同じ内容について冗長な議論を行ってしまう可能性がある。また、当時はあまり本質ではないと思っていた議論が、後から視点を変えてみてみると思いがけない価値を持ったものであると気付くこともあるかもしれない。このように議論には再利用性があり、すべてを無駄にしないためには、議論内容を何らかの手段で記録することが必要になるだろう。
2.3 DRIPサイクル
前節では知識活動における議論の重要性と再利用性について述べた。しかし、ただ議論を行い、それを記録しているだけでは、よりよい知識活動を行うことはできない。活動を行っている人間自身が議論と知識活動との関わりを意識し、議論を有効的に活用するための実践が必要となる。そのため、本研究ではDRIPサイクルと呼ばれる、以下の4つのフェーズから構成される、知識活動に関する新しいサイクルを提案する。
-
議論(Discussion)フェーズ
アイディアや知識を他者に発表し、議論を通じて多角的な視点によるコメントやアドバイスを獲得する
-
再認(Rumination)フェーズ
議論フェーズで行われた議論の内容を整理し、その後の活動方針を見定める
-
探究(Investigation)フェーズ
過去の議論内容を踏まえつつ、調査や実験、検証といった様々な作業を行い、新たなアイディアや知識を創出する
-
創出したアイディアや知識を公表し、他者から新たなコメントやアドバイスを獲得したい事柄を明確にし、次の議論フェーズにつなげる
集約(Preparation)フェーズ
議論フェーズは、前述した議論そのものに相当するフェーズであり、これまでの知識活動から生まれたアイディアや知識を他者に向けて発表し、自分だけでは解決できなかった、もしくは他者の意見を参考にしたい点などについて、参加者が多角的な視点から質問や意見などの発言を行うことによって、フィードバックが獲得される。その際、議論内容を記録した議事録を作成することにより、議論から得られたフィードバックをその後の活動で利用することが可能になる。しかし、作成された議事録には、「自分にとって有益な議論は何なのか、そしてその議論がなぜ有益なのか」という人間の解釈が含まれていない。そのため、目的とする議論を探し当てることが困難になる。そこで再認フェーズでは、議事録の中から重要な議論を取り出し、再利用をしやすくするために自身の解釈を加える作業を行う。探究フェーズでは、議論中に指摘された情報不足を補うために調査を行い、重要なアドバイスに基づいて新たなアイディアを生み出し、実験を行うなど、状況に応じて議事録を適切に利用しながらプロセスを行う。プロセスを通じて生み出されたアイディア・知識とその時利用されていた議論を関連づけることによって、議論をどれだけ活用しているかを知ることができる。一つの議論に対するアイディアや知識の量や質によって自身の活動の成熟度を測ることができ、見落としている議論の存在を知ることで、より広い視野を持つことができる。探究フェーズで生み出されたアイディアや知識を、他者に向けて発表し、議論を行うことによって知識活動の内容が組織内で共有され、新たなフィードバックを得ることができる。このようなフィードバックを得るためには自身の知識活動の内容を他者に正確に伝達する必要がある。そのため集約フェーズでは、知識活動を行っている人間が自身の活動内容を把握し、発表資料としてまとめることが求められる。そして、作成された発表資料を用いることによって新たな議論が生まれ、さらなるフィードバックを獲得することができる。このように4つのフェーズが、図のように繰り返し行われることによって、多くのアイディアが創出され、知識として具体化・理論化される。
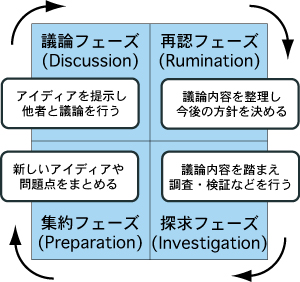
図2.3: DRIPサイクル
DRIPサイクルにおいて最も特徴的な点は再認フェーズである。これまでにも、発表に関するノウハウとして、発表中にメモを取るという行為が暗黙的に行われてきた。相手の発言を自分の頭の中で整理し、自分にとって重要な個所を書き残すことによって、それ以降の活動の中で再利用することが可能になる。そして、記録されたメモは「ディスカッションマイニング関連」や「個人研究関連」のように活動の内容に合わせて分類されることによって、必要に応じて探し出すことができる。
しかし、議論を行っている最中にメモを書くという作業は負担が大きいため、必要な議論内容をすべて記録することは困難である。そのため、書き残されたメモは、単語の羅列や不可解な文章があったりと必ずしも事後の利用に適した形式で残されるとは限らない。結果として見返したときにその内容が把握できない可能性がある。さらにメモの分類方法も、内容や記録された日付順など様々であり、状況に応じて適切に変更できることが望ましいが、紙でメモを行っている場合は蓄積されたメモの分類方法を変更することは容易ではない。
一方、議論内容を議事録として記録することが広く行われている。一般に、書記と呼ばれる人間が発言内容を逐一記録することによって議事録は作成されるが、その作業はメモを取るという行為以上に負担が大きい。そのため、情報技術を駆使して議事録の作成を行う研究が数多く存在する。このような手法は議論内容を網羅的に記録することができるという利点がある。しかし、もともと議事録は共有するという観点に基づいて作成されているため、そこにはメモのように発表を行った人間の解釈が含まれていない。そのため、過去に重要だと思った議論を再度閲覧したい時は、まず、その議論が含まれている議事録を検索する。さらに目的とする議論が議事録のどの位置にあるかを見つける必要がある。このように、議論に対して解釈が付与されていないと、同じ議論を閲覧する度に、冗長な作業を繰り返すことになる。
再認フェーズでは、議論フェーズで発表・議論が行われた後に、発表者が議事録に解釈を付与することによって、これまでは誰が閲覧しても同じ内容を提示するコンテンツであった議事録を、プライベートなものとして編集する。議論内容を網羅的に記録した議事録を、発表中に記録するメモのように個人化することで、必要とする議論を探し出すという作業を効率的に行うことが期待できる。
2.4 再認フェーズに関する考察
一般に、時間の経過と共に議論の内容を忘れてしまうため、再認フェーズは議論フェーズからできるだけ時間を空けずに行うことが必要であると思われる。それを検証するため予備実験を行った。この予備実験は、筆者と同じ研究室に所属している男性2名を被験者として行った。
まず、被験者らと同じプロジェクトに所属する別の男性1名に自身の研究活動に関する発表を行ってもらい、被験者らと議論を行ってもらった。次に、被験者らには、発表が終わった直後と発表が終わってから1週間後に、人手で議論内容を発言単位で記録した紙をもとに、以下の作業を行ってもらった。
-
議論の中で重要だと思われる発言はどれかを選択
-
その発言が重要であると判断した根拠を簡単なテキストで記入
その結果、発表直後に行った時に比べ、発表から1週間後に行った時のほうが重要であると判断した発言の数が少ないことが確認された。また、それぞれの作業が終わった時に感想を記述してもらった。その中には、「(1週間後に行ったときは内容を)ほとんど覚えていない」や「頭の中が真っ白だった」というように1週間後では議論の内容を忘れかけてしまっていると推測されるコメントがあった。このことから再認フェーズは議論フェーズの直後に行うことが望ましいことが確認された。
それに加えて、その他のコメントを分析することで、再認フェーズと直接関わりを持つ議論フェーズや探究フェーズに関する考察も行った。今回の予備実験では、発言単位に対して重要性の判定やその根拠をメモしてもらったが、その作業を行う対象は発言単位ではなく、意味的にまとまった話題単位のほうがよいというコメントがあった。これは、一つの発言だけではなく、その発言の派生元となる発言や、その発言から派生した発言まで含めて議論内容を見ることによって、より深い内容理解につながるからであると推測される。
この他にも、1週間後に作業を行った際、発表直後に行った時とは異なる視点で同じ議論を捉えることがあるというコメントがあった。これは、発表直後から1週間の間に同じテーマに関する別の発表が行われており、その時行われた議論の内容が1週間後の作業に影響を及ぼしたためだと考えられる。このような結果を踏まえると、知識活動の中で繰り返し議論を行うことによって、過去の議論に対する考え方は常に変化し続けるのではないかという仮説が考えられる。そのため、再認フェーズでは重要な議論に対して、アクセスしやすくするための情報の付与だけを行い、変化し続ける議論に対する考え方は探究フェーズで付与・変更することを考えた。
以上の考察を踏まえ、再認フェーズでは、話題単位でセグメントされた議事録に対して、重要なものであればアクセスしやすくするための情報を付与するという作業を行うものとした。アクセスしやすくするための情報の例としては、議論内容を端的に表すようなキーワードや、「調査するべきことを探す」「実装方法を考える」といった議論内容の利用目的が挙げられる。
2.5 まとめ
本章では、まず支援の対象となる知識活動を「あるテーマに対して継続的にアイディアを創出し、知識として理論化・具体化する活動」と定義した。そして、知識活動を構成する様々なプロセスの一つである議論の重要性や再利用性について触れた上で、知識活動をDRIPサイクルと呼ばれる議論中心のサイクルとして捉え、予備実験を通じて知識活動と議論との関係を明らかにした。以降の章からは、この定義に基づき、情報技術を用いた知識活動の支援手法について説明をする。そのための導入として、次章では議論内容を再利用可能な形式として獲得する手法であるディスカッションマイニングについて述べる。これはDRIPサイクルの議論フェーズを支援するための技術である。また、獲得した議論内容を会議コンテンツとして効率的に閲覧するためのインタフェースであるDiscussion Media Browserについても述べる。
3 議論内容の獲得と利用
議論内容に基づく知識活動の支援を行うためには、前章で説明した議論フェーズにおいて議論内容を何らかの形式で記録する必要がある。しかし、単純に議論の内容を記録すれば良いわけではなく、その後のプロセスで効率的に再利用できるように構造化を行う必要がある。
本章では、議論内容の効率的な再利用を実現するために必要となる議論の意味構造化について考察を行う。また、その考察に基づいて議論内容を獲得するディスカッションマイニングと呼ばれるシステムについて述べた後に、獲得した議論内容を再利用するためのシステムの詳細を説明する。
3.1 ディスカッションマイニング
様々なプロセスにおける議事録の効率的な再利用を実現するためには、議事録の記録方法を工夫する必要がある。これまでにも議事録を作成するシステムに関する研究は数多く行われている。議論の詳細情報の取得方法もテキストだけでなく、発表に用いられた資料や、議論の様子を記録した映像・音声を組み合わせるなど多岐に渡る。しかし、これらのシステムは議事録を作成することに重点を置いており、議事録を用いた応用は検索や要約など、実際にどのように使用されるかまで考慮されていない。
会議記録から話題を抽出する古田らや栗原らの研究に見られるように、一般に議事録は話題単位で閲覧することが多い。しかし機械による意味解釈は非常に困難であるため、テキストや音声を用いた話題抽出の精度は決して高いとは言えない。そこで我々は、議論内容をテキストやビデオを組み合わせたマルチメディア議事録として半自動的に記録し、そこから人間にとって再利用可能な知識を抽出するディスカッションマイニングと呼ばれる技術を研究・開発している。
ディスカッションマイニングは、人間同士の知識交換の場であるミーティングにおける活動から、映像・音声情報やテキスト情報、メタデータなどの実世界情報を獲得し、それらを統合して構造化し、議論コンテンツと呼ばれる再利用可能な知識を構築するための技術である。ディスカッションマイニングでは意思決定を目的とするのではなく、発表を主体とした議論を行う会議を対象としている。対象とする会議ではモデレータとなる発表者、その発表を聴き意見を述べる参加者、そして会議の記録を行う書記がいる。会議のモデレータは、発表資料としてスライドをプロジェクタで投影して発表を行うことを前提にしている。
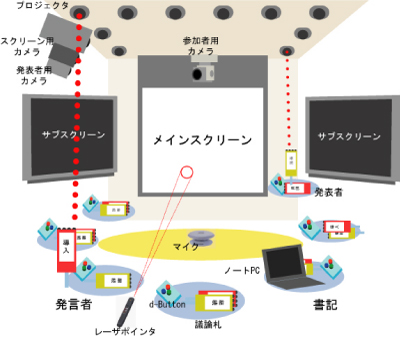
図3.1: ディスカッションルーム
会議を行うミーティングルームは図のような空間を想定している。ミーティングルームには音声を記録するためのマイクが設置されている。会議の詳細な文脈を記録するために、1台のパンチルトカメラが設置されている。また、スライドを投影するスクリーンを記録するために固定カメラが1台、そして発表者の様子を記録するために固定カメラが1台設置されている。 また、ディスカッションマイニングではミーティングルームの他に、議事録の作成・管理を行うための議事録サーバが用意されている。
会議中の発言に関する情報を記録するための設備として、後述する議論札およびd-Buttonという赤外線を送信するデバイスと、それを受信するIRセンサアレイが天井に設置されている。会議において発言する際に、発言者は議論札を天井のIRセンサアレイに向けて札を上げることで、発言時の情報を送信する仕組みになっている。発言に関する情報は随時システムに送信され、書記の発言内容入力の支援を行う。
パンチルトカメラは、会議中ディスカッションルーム内をスウィングしながら参加者の様子を記録している。また、発表者以外の任意の参加者が発言を始めた時、議論札と連動し、パンチルトカメラがその方向に固定され、発言者の様子を撮影する。発言終了後には再び会場内を記録するためにスウィングモードに切り替わる。 スクリーン用カメラは、スクリーンに投影されるプレゼンテーションに用いたスライドやデモ、参考資料の様子を記録する。
発表者は、図に示されるブラウザベースの専用ツールを使用してプレゼンテーションの操作を行う。まず、会議開始時に専用ツールから発表に用いるスライドファイルを議事録サーバにアップロードする。アップロード時には発表の内容を表すキーワードや、サーベイレポート、研究進捗といった発表のカテゴリーを選択する。アップロードが終了すると、会議が開始され開始時刻が議事録サーバに送信される。発表者は専用ツールを用いてスライド操作を行い、スライドの切り替えタイミングやスライドアニメーションの表示タイミングは随時サーバに送信され、記録される。また、スライド以外の資料(デモやWebの参照)を用いてプレゼンテーションを進める場合には、資料を追加することもできる。会議終了時には、終了時間が議事録サーバーに送信・記録される。
ディスカッションマイニングシステムを利用する参加者(発表者、書記を含む) は、議論札とd-Buttonという二つのデバイスを利用する。参加者は発言を行う際に、議論札を上げて発言を行う。その際に札のLEDから天井のIRセンサアレイに向かって赤外線信号が送信される。この信号には発言者が誰であるか、発言の種類(以降、発言タイプと呼ぶ)が何かという情報が含まれる。議事録サーバには、これらの情報に加えて受信した時刻が送信・記録される。また、発言の終了時刻は後述のd-Buttonによって入力される。
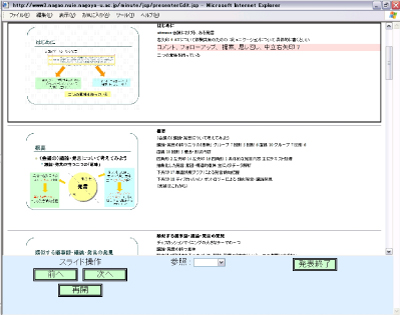
図3.2: 発表者用インタフェース
ディスカッションマイニングでは、発言者の発言タイプを議事録構造化の視点から「導入(Start-up)」と「継続(Follow-up)」の2つに大きく分類する。議論において、現在行っている発言が直前の発言(あるいはいくつか前の発言)を受けてなされるものなのか(継続)、それとも新しい話題の起点なのか(導入)が議論理解に大きな影響を与えているという考えに基づき、これを議論の構造化の主要な手がかりとしている。
会議中の発表者の発言や参加者の発言に対して随時自分のスタンスを入力できるデバイスがd-Button(discussion Button)である。 d-Buttonには3つのボタンが設置され、スタンスに応じたボタンを押下することで議事録サーバに自分のスタンスの情報を送信する。本システムでは参加者のスタンスを「同意(agree)」、「非同意(disagree)」、「中立(neutral)」としている。また、発言の終了時間を記録する際にも用いる。
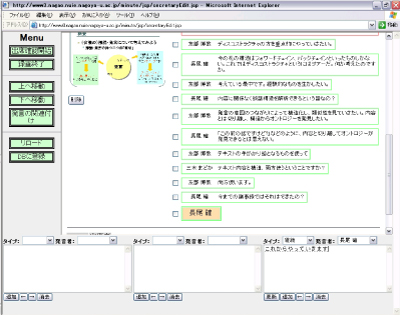
図3.3: 書記用インタフェース
書記は図に示されるWebブラウザベースの専用ツールを用いて議論の構造化と発言内容の記録を行う。また、参加者を撮影するカメラの制御や、データベースへの登録作業などもこの書記ツールから行うことができる。 書記ツールは前述の議論札と連動しており、参加者が入力した情報が随時追加されていく。参加者が議論札から情報を発信すると、書記ツールに発言者と発言タイプが付与されたノードが生成される。書記はこのノードを選択し、テキストを入力することで発言内容を記録することができ、議論のまとめや説明などのノードも専用ツールから追加を行うこともできる。また、発言がどの発言を親として持つか (つまり、どの発言を受けて発されたものか)を記録するために、発言間のリンクづけを行うこともできる。
カメラやマイクで会議の詳細な文脈を記録した音声・映像は MPEG-4形式で映像・音声データベースに保存される。発表者が入力したスライド情報、書記が入力したテキスト、参加者のデバイスを使って獲得したメタデータは、議事録XMLとしてXMLデータベースに記録される。
このようにして記録された議事録はXMLとMPEG-4によるマルチメディア議事録としてデータベースに記録される。記録された議事録は図のようにWebブラウザを用いて容易に閲覧することができる。
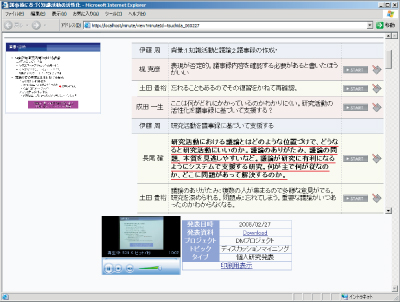
図3.4: ディスカッションマイニングシステムで作成した議事録
3.2 Discussion Media Browser
ディスカッションマイニングシステムによって、発言者や発言内容、発言時間など議論に関する様々なメタデータを取得できることを前節で述べた。そして、取得したメタデータを用いて効率的な議論内容の閲覧を実現することによって、議論内容のより深い理解につながり、知識活動の活性化を促すことが期待できる。
ディスカッションマイニングシステムで作成される議事録は、テキスト主体の閲覧に有効なデータ構造を持っているが、議論内容の正確な把握には、映像・音声を含むマルチメディア情報を用いた閲覧のほうが有効であると考えられる。筆者らはテキスト主体の議事録に、映像・音声情報やメタデータを組み合わせたものを会議コンテンツと呼んでいる。
マルチメディア情報には膨大な量の情報が含まれているため、閲覧目的に合わせた閲覧方法を提供する必要がある。会議コンテンツの閲覧目的は、重要な発言の再確認や自分が参加できなかった議論の内容把握など数多く存在する。このように様々な閲覧目的を包括できるような仕組みを実現するために筆者の所属する研究室ではDiscussion Media Browserと呼ばれる会議コンテンツを効率的に閲覧するためのシステムの研究・開発を行っている。
3.2.1 会議コンテンツの作成
ディスカッションマイニングで作成された議事録は、テキスト主体の閲覧に有効なデータ構造を持っている。しかし、ビデオ主体の閲覧を行うとき、ユーザが行う操作は時系列に基づいたものであることが推測される。つまり、ビデオによる議論内容の効率的な閲覧を行うためには、会議の構成要素ごとに構造化されたデータではなく、時系列ごとに構造化されたデータを作成することが望ましい。また、会議の内容を詳細に分析すると、発表者が資料を用いて自分の考えを述べている場面や議論が停滞してしまっている場面などいくつかの場面に分けられる。本研究では、ビデオ主体の閲覧を効率的に行う前処理としてインタフェースXMLと呼ばれるデータを生成することで会議コンテンツの作成を行う。
インタフェースXMLは図のような構造を持っており、ビデオや発言、参加者やスライドなど議論の構成要素に関する情報とビデオの再生に関する時間情報の2つに大きく分けられる。また、インタフェースXMLのルートノードには議論を特定するためのIDが記述されている。

図3.5: インタフェースXML
議論の構成要素に関する情報はルートノードの下にあるresource要素に記述されている。resource要素はvideoList要素、slide要素、personList要素、statements要素の4つから構成されている。videoList要素には発表者(presenter)やスクリーン(screen)といったビデオのタイプやURL、IDが記述されている。また、slide要素は議論に利用されたスライドの情報が記述されており、スライド内のページタイトルやページテキスト、アニメーション情報がこれに該当する。発表者や書記が誰であるのか、また誰がどのビデオに撮影されているのかといった参加者に関する情報はpersonList要素に記録される。また、議論中に行われた発言に関する情報はstatements要素に記述される。具体的には、発言者のID、発言のタイプ、発言テキスト、その発言に対するスタンス(賛成、反対、中立)の数がこれに含まれる。
関連する議論や発言等をまとめて視聴することで、議論内容の深い理解に繋がることが予想される。しかし、これらの情報を自動的に抽出することは困難である。本研究では議論札のタイプである導入・継続によって抽出される発言の集合に対応した時間区間を議論セグメント、それ以外の時間区間を発表セグメントと定義する。この2つのセグメントの時間情報はtimeline要素に記述される。timeline要素の下には、議論セグメントに関する情報を表すds要素と発表セグメントに関する情報を表すps要素があり、それぞれの要素にはセグメントのIDとセグメントの再生開始時間、終了時間が属性として記録されている。また、議論セグメントを表すds要素にはそのセグメントに含まれる発言の数や発言者の数も属性として記録されている。そして、それぞれのセグメントはアイテムと呼ばれる要素から構成されている。議論セグメントにおけるアイテム(議論アイテム)は発言の時間区間であり、発表セグメントにおけるアイテム(発表アイテム)はスライドのページの切り替えやアニメーション表示の切り替え、デモなど発表者の操作によって切り分けられる時間区間である。
ds要素の子要素であるdi要素は、議論アイテムの情報の発言を表している。議論アイテムに記述される情報を表に示す。各di要素には開始・終了時間や議論アイテムのID、発言タイプのほかに、対応する発言のIDやその発言時に表示されていたスライドのIDなどの情報が記録される。またprev・next属性には直前・直後の議論アイテムのIDが記述される。この情報を用いて閲覧時に議論アイテム間の移動を行うことによって、発表内容を閲覧せずに議論内容だけを閲覧することが可能になる。この議論アイテム間の関係は、「導入」「継続」という発言タイプから暗黙的に取得されるだけでなく、書記が専用ツールで付与したリンク情報も考慮されるため、prev・next属性に記述されるIDは複数指定が可能である。また、発表の内容を受けて議論を開始することが多いため、各ds要素内で先頭に現れるdi要素には、直前の発表アイテムのIDが記述されている。
発表セグメントを表すps要素の子要素には発表アイテムを表すpi要素がある。pi要素に記述される情報を表に示す。議論アイテムと同様に、発表アイテムにはアイテムのIDやビデオの再生開始時間・終了時間が記述される。また、先頭の議論アイテムに対応する発表アイテムのIDが記述されるのに対して、同じように発表セグメントの最終発表アイテムには、そこから派生した議論アイテムのIDがdi属性に記述される。発表者がスライド操作を行う前に異なる話題で議論を始めることがあるため、di属性に記述されるIDは複数指定が可能である。
3.2.2 システム構成
Discussion Media Browserで会議コンテンツを閲覧するときは、まず、システムのトップページに表示される会議コンテンツの一覧を見て、その中から閲覧したい会議コンテンツを選択する。システムは要求された会議コンテンツをデータベースから取得し、閲覧インタフェースを提示する。
様々な場面で起こる会議コンテンツの閲覧要求に対応するために、Discussion Media BrowserはWebサーバ・クライアント型のシステムとして構築されており、閲覧者は特別なアプリケーションをインストールする必要は無い。システム全体の構成を図に示す。
会議コンテンツ閲覧サーバ(以下閲覧サーバ)は、インタフェースXMLの生成・取得と、閲覧インタフェースの提示を担当する。会議終了後、議事録やリンク情報の変更があるたびに、議事録データベースとアノテーションデータベースのデータを統合してインタフェースXMLを自動的に生成し、インタフェースXMLデータベースに保存する。また、ユーザが会議コンテンツを選択すると、会議コンテンツの閲覧要求が閲覧サーバに送信される。閲覧サーバは要求されたコンテンツに該当するインタフェースXMLをデータベースから取得し、後述する5つのコンポーネントから構成される閲覧インタフェースをユーザに提示する。
ユーザは目的に応じて、インタフェース内のコンポーネントを操作することで会議コンテンツの閲覧を行う。会議の様子を撮影したビデオは、ストリーミングサーバを通じてアクセスされる。
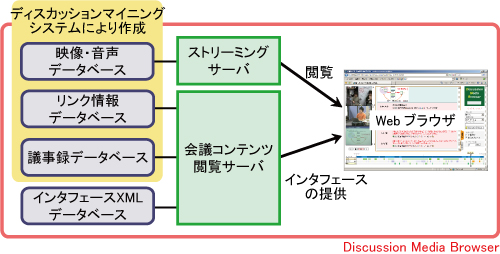
図3.6: Discussion Media Browserのシステム構成図
3.2.3 会議コンテンツの閲覧
Discussion Media Browserの全体を図に示す。
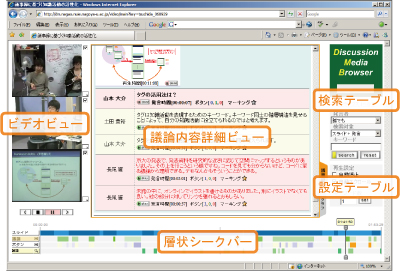
図3.7: Discussion Media Browser
Discussion Media Browserは以下に示すコンポーネントから構成されている。
-
ビデオビュー
-
層状シークバー
-
議論内容詳細ビュー
-
検索テーブル
-
設定テーブル
これらのコンポーネントがそれぞれ相互に連携しながら動作することによって議論内容の効率的な閲覧を実現している。以下で、それぞれのコンポーネントの詳細について述べる。
3.2.3.1 ビデオビュー
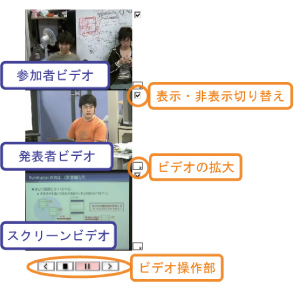
図3.8: ビデオビュー
議論中の様子を取得するためのビデオには、参加者ビデオ、発表者ビデオ、スクリーンビデオの3種類がある。ビデオビューはこれら3つのビデオの同時閲覧を実現している(図)。また、閲覧する環境や閲覧者の要求に合わせてビデオの表示・非表示を切り替えたり、縮小された映像では確認できないスクリーンの文字などを確認するためにビデオの拡大を容易に行うことができる。そして、再生や停止、スキップなどのビデオ操作を行うことも可能である。
このビデオビューは後述する層状シークバーや議論内容詳細ビュー上の操作と連動しており、発言単位やスライド操作単位でのスキップ再生を行うことができる。逆にビデオビューにおけるビデオの再生時間に応じて層状シークバー内のスライダーや議論内容詳細ビューの表示が変化することで、議論全体の中でどの時点を閲覧しているのかを確認することができる。
3.2.3.2 層状シークバー
ディスカッションマイニングシステムで取得したメタデータは、層状シークバーと呼ばれる図に示すコンポーネント内のタイムライン上に表現され、議論を俯瞰する機能を提供する。層状シークバーはスライダーと複数のバーによって構成される。
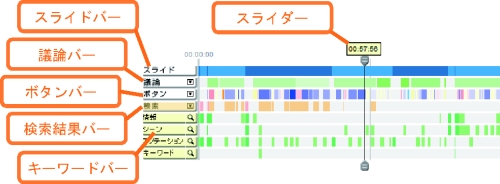
図3.9: 層状シークバー
スライダーの上部には現在再生されているビデオの時間が表示されており、再生時間に応じてタイムライン上を移動する。また、スライダーをドラッグすると、ビデオビューにそれぞれのビデオのサムネイル画像が表示され、議論中の任意の位置にアクセスすることができる。ドラッグが終了するとその時点からビデオの再生が開始される。
層状シークバーでは、ディスカッションマイニングシステムで取得したメタデータごとにタイムライン上にバーを作成することによって、様々な視点から議論全体を俯瞰することができる。スライドバーは発表者のスライド操作を表現している。色の変わり目がスライドの切り替えを表しており、それぞれの箇所にマウスカーソルを合わせるとその時に表示されていたスライドのタイトルを確認することができる。また、クリックをすることによって、該当するスライドの開始時間からビデオの再生が開始される。
発表中に行われた議論の情報は議論バーに表示される。議論バーは議論セグメントを単位とするアイテムから構成されており、それぞれの議論セグメントにおける単位時間当たりの発言数によって表示される色が異なる。アイテムをクリックすると、その議論セグメント内の導入発言からビデオの再生を開始する。また、それぞれのアイテムにマウスカーソルを合わせると図のように該当する議論セグメントの概要がポップアップウィンドウに表示される。議論セグメントの概要には、その議論セグメントにおける発言者のリスト、発言者数、発言数に加え、発言含まれるキーワードを表示している。これらの情報を手がかりに、その議論セグメントではどのような内容の議論が行われていたかを把握することができる。
ボタンバーは、発言に対して押されたd-Buttonの数を表している。バーをクリックすると該当する発言の再生を開始する。賛成ボタンを多く押された発言ほど青く、反対ボタンを多く押された発言ほど赤く表示しており、中立が多ければ緑色の表示になる。また、その発言に対して押された賛成・反対・中立ボタンの情報全てを確認することも可能である。また、第4章で後述するマーキング情報もこのバーで確認することができる。その際、ある発言に対して押された賛成・反対・中立の情報とマーキング情報が重なってしまう可能性がある。ボタンバーの情報は、どの発言を閲覧すればいいのかを判断するための手がかりであるという観点から捉えると、賛成・反対・中立の情報よりも個人が「重要である」「役に立つ」と判断した情報をより重視すべきである。そのため、賛成・反対・中立の情報とマーキング情報が重なったときはマーキング情報を優先的に表示する。
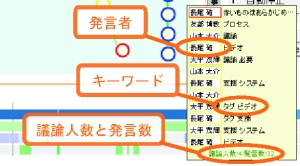
図3.10: 議論セグメントの概要表示
検索テーブル上で行われた検索の結果は検索結果バーに表示される。Discussion MediaBrowserにおける検索は、スライドや発言に対して行うことができ、スライドに関する検索結果はピンク色で、発言に関する検索結果はオレンジ色で表示される。結果をクリックすると、該当箇所がスライドの検索結果ならばそのスライドの開始時間から、発言の検索結果ならばその発言の開始時間からビデオの再生を開始する。
また、発表や議論の内容を巨視的に把握するために、層状シークバーにはキーワードバーが用意されている。キーワードバーは、発表・議論に現れたテキスト情報を形態素解析することによって得られたキーワードを表示するバーである。そのキーワードが現れている箇所がスライドならば濃い緑色、発言ならば薄い緑色によって表現される。検索結果バーと同様にクリックしたアイテムに該当する箇所がスライドか発言かによって再生を開始する時間が異なる。また、キーワードバーは設定テーブルによって、表示する数を変更することができる。
3.2.3.3 議論内容詳細ビュー
層状シークバーによって様々な視点から議論全体の俯瞰を行った後は議論内容詳細ビューによってその詳細を閲覧することができる。議論内容詳細ビューは、議事録ビュー(図)とグラフビュー(図)の2種類のビューから構成されており、右側のタブによってどちらかのビューを選択することで、閲覧したい内容に合わせた情報提示を実現する。

図3.11: 議事録ビュー
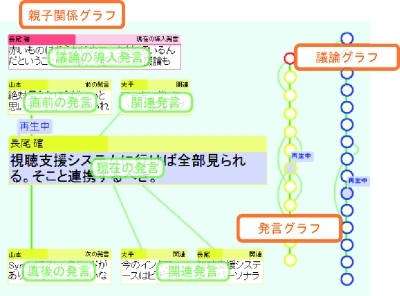
図3.12: グラフビュー
議論の内容をテキスト中心に閲覧するには議事録ビューを利用する。議事録ビューは、発表に用いられたスライドのサムネイル画像や個々の発言内容を表すテキスト情報、メタデータから構成されている。スライドのサムネイル画像をクリックすることによって、別ウィンドウに拡大表示され、より詳細な発表内容を確認することができる。そして、個々の発言内容には書記が入力したテキストに加え、発言者ID、発言時間、その発言に対して押されたd-Buttonの数、マーキングの情報が含まれる。ユーザは、これらの情報を元にビデオの閲覧を行う。また、ビデオの再生時間に対応するスライドや発言はハイライト表示され、現在閲覧している箇所を容易に把握することができる。さらに、設定テーブルで自動スクロール機能を有効にしておくことによって、再生しているスライドや発言が切り替わった時、議事録ビューは該当するスライドや発言に自動にスクロールし、フォーカスを当てる。
ディスカッションマイニングシステムで取得するメタデータには、導入・継続という発言タイプによって付けられる発言の親子関係の他に、書記によって付けられた発言間リンクがある。議事録ビューでは、個々の発言を時系列順に表示しているため、議論を順番に閲覧することには適しているが、書記が追加したリンク関係を把握することはできない。この関係を把握しやすいグラフ形式で提示するのがグラフビューである。グラフビューは、親子関係グラフ、発言グラフ、議論グラフという3つのグラフによって構成されている。
親子関係グラフは、ある発言を中心とする発言間の関係を表現したグラフである。グラフの中央にある発言の上下には、その発言の派生元である親発言、派生先である子発言が表示されている。最上部には中央の発言が含まれている議論セグメントの導入発言が表示されているが、もし中央の発言が導入発言であるときはひとつ前の議論セグメントの導入発言が表示される。中央の発言をクリックすることによって、その発言のビデオを閲覧することができる。また、親発言や子発言、導入発言をクリックすれば、その発言が中央に移動し、その発言の親子関係が新たに表れる。これにより、発言間の関係を容易に把握することができ、テキストだけでは理解することが困難な文脈情報の理解を促すことができる。
3.2.3.4 検索テーブル
検索テーブルは、あいまいな手がかりをもとに閲覧者とスライドや発言を結びつける役割を果たす。同時に、検索結果に対してインタラクティブな操作を行うことによって、閲覧目的を明確にし、より具体的な閲覧対象へと閲覧者を導く手助けを行う。
検索テーブルでは、検索を行う対象(スライドか発言、もしくは両方)、その対象が発言ならば発言者名、テキストを入力することによって検索を行う。検索例を図に示す。検索を行うと該当した件数が検索テーブルの下部に表示される。また、議事録ビューや層状シークバー内の検索結果バーの該当箇所がハイライトされる。検索テーブル下部に表示された4つのボタンによって、検索で該当した箇所を移動することができる。また、同期再生ボタンを押した状態で検索結果間の移動を行ったときは、移動した先のスライドや発言のビデオ再生を開始する。
閲覧者は、検索テーブルと層状シークバー・議事録ビューとの操作を繰り返すことによって会議コンテンツの鳥瞰的・局所的な閲覧を適切に行うことができる。従来の検索に比べ、よりインタラクティブな操作を行うことで効率的に閲覧目的を達成し、内容の理解を深めることが期待される。
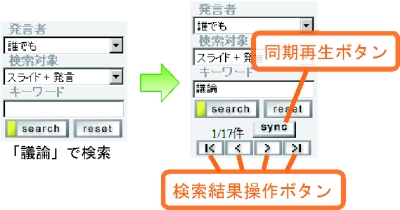
図3.13: 検索の例
3.2.3.5 設定テーブル
設定テーブルでは、ビデオの再生に関する設定と層状シークバー内のキーワードバーに関する設定を行うことができる。ある発言の再生が終了したときに「自動停止」が有効になっていれば、自動的にビデオの再生が停止される。また「自動スクロール」が有効になっているときは、再生している発言やスライドに合わせて議事録ビュー、もしくはグラフビューのハイライト箇所が自動的にスクロールされる。これらの設定をユーザが行うことによって、スムーズにビデオを閲覧するという目的と時間をかけて内容を閲覧するという目的の両方を満たすことができる。
「キーワード数」というテキストボックスに0から20までの数を入力することによって、層状シークバー内のキーワードバーの数を変更することができる。キーワードバーの数を増やすことによって発表・議論内容の概要の把握を、数を減らすことによって議事録ビューやグラフビューなどの表示領域が拡大され、詳細な議論内容の把握を促すことが期待される。
3.3 まとめ
本章では、DRIPサイクルにおける議論フェーズで行われた議論の内容を再利用可能な形式として記録するための技術であるディスカッションマイニングについて述べた。ディスカッションマイニングでは、様々なデバイスやツールを用いることによって、議論を話題単位にセグメンテーションした議事録を作成することが可能になる。そして、作成された議事録を映像・音声情報と組み合わせて会議コンテンツとして閲覧するためのシステムであるDiscussion Media Browserについて説明した。このシステムでは、ユーザが会議コンテンツのインタラクティブな視聴を行うことで、効率的な議論内容の閲覧を実現した。次章では、獲得された議論内容を、知識活動の中でいかに有効的に活用するかについて述べる。
4 議論内容に基づく知識活動支援
前章では、議論フェーズで行われた議論の内容を獲得するための手法であるディスカッションマイニングと、獲得した議論内容を会議コンテンツとして閲覧するためのシステムであるDiscussion Media Browserについて述べた。しかし、第2章で述べたように、知識活動を効率的に行うためには、議論内容を獲得・閲覧できるだけではなく、効率的に再利用できる仕組みが必要となる。
本章では、会議コンテンツを効率的に再利用するために必要となる要件について述べる。そして、その要件を満たすために本研究で研究・開発している知識活動支援システムの詳細について述べる。
4.1 議論内容の効率的な再利用
議論が繰り返し行われるたびに、会議コンテンツが蓄積されるため、知識活動を行う上で必要となる会議コンテンツを効率的に探し出す作業が必要になる。会議コンテンツを効率的に探し出すためには、利用目的を考慮することが有効だと考えられる。会議コンテンツを利用して確認するであろう事項を列挙すると、以下のようなものが挙げられる。
-
どんな事項について調査を行えばいいのか
-
テーマを扱うためにどのような考察が必要になるか
-
実装においてどのようなことをすれば、よりよい成果が上げられるのか
-
どのような発表をすれば、より自身の活動を他者にうまく伝えられるのか
これらの事項は調査や実装など知識活動におけるプロセスと密接に関係している。会議コンテンツの利用目的をコンピュータが理解し、ユーザの状況に合わせて適切な会議コンテンツを提供できることが望ましい。
4.1.1 会議コンテンツに対するアノテーション
コンピュータに意味内容の解釈を行わせることは困難であるため、何らかの手段によって文脈情報をコンピュータに理解可能な状態にする必要がある。それを解決する手段の一つとしてアノテーションと呼ばれる技術が近年盛んに研究・開発されている。アノテーションとは「注釈」という意味であり、文書や画像・ビデオ等に付与された注釈を意味する。辞書的な意味としては、人間が人間のために付与した注釈を意味することが多いが、本論文では、機械が人間のために、あるいは人間が機械のために、さらには機械が機械のために付与する注釈も含む。本論文でのアノテーションの意味は、コンテンツに対して意味内容や意味構造といった情報を記述し、コンテンツと関連づけることを意味する。コンテンツに対してアノテーションを付与すると、そのコンテンツの意味内容や構造を解析するための手助けとなり、機械的な処理だけでは十分な精度が得られないような処理が高精度で可能になることが期待できる。アノテーションの概念図を図に示す。
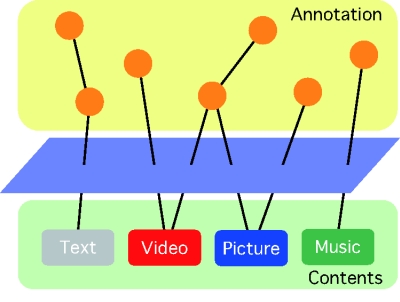
図4.1: アノテーションの概念図
アノテーションの問題点は、より詳細なアノテーションを付与するためには多くの人的コストが必要となるということである。そのため、本研究ではDRIPサイクルにおける再認フェーズに着目した。第2章で述べたように、再認フェーズでは、話題単位でセグメントされた議事録に対して、重要なものであればアクセスしやすくするための情報を付与するという作業を行う。この作業を通じて、会議コンテンツに対するアノテーションを暗黙的に付与するのである。
4.1.2 アノテーションの種類
本研究では、会議コンテンツに対して付与するアノテーションとして、以下の3種類を用意した。
-
マーキング
重要である発言を特定するために付与されるアノテーション
-
マーキングの付与された発言を含む議論セグメントの内容をキーワード列によって表現したアノテーション
キーワードタグ
-
プロセスタグ
マーキングの付与された発言を含む議論セグメントがどのようなプロセスで再利用可能かを表したアノテーション
以下ではそれぞれのアノテーションの詳細について述べる。
4.1.2.1 マーキング
知識活動において議論は繰り返し行われるものであり、作成される議事録の数は次第に増えていく。しかし、作成された議事録内のすべての発言は同等の重みで扱われるため、自分にとって知識活動を行う上で有益な発言がどの議事録に含まれているのかが分からなくなる可能性がある。つまり、自分が有益であると判断した発言に対して何らかの情報を付与することが望ましい。それを実現するのがマーキングである。
ある発言が自分にとって有益であるという判断は、議論中に行うものと議論後に行うものがあると考えられる。議論中に有益であると判断した発言は、ディスカッションマイニングシステムで利用しているd-Buttonによって付与することができる。また、議論後にマーキングアノテーションを付与する際にはDiscussion Media Browserを用いる。
4.1.2.2 キーワードタグ
キーワードタグは、はてなブックマーク†やdel.icio.us†に代表されるソーシャルブックマークのタグのように、議論内容を端的に表現するキーワードを付与するものである。これにより類似する議論同士をまとめることができ、新たなアイディアや知識を創出する際に必要とする議論内容を容易に検索することが可能となる。
4.1.2.3 プロセスタグ
議論からのフィードバックにはタイプがいくつかあり、それぞれのタイプに応じて利用されるプロセスが異なる。たとえば、発表者が知識として知らなかった点を指摘する発言は調査に、議論中に指摘された新たな問題点はアイディアの創出につながる。このように対象となる議論が、知識活動のどのプロセスにおいて再利用されるかをプロセスタグとして再認フェーズで付与する。具体的には以下の4つのタグを用意した。
4.2 知識コンテンツ
テーマに対する目標をどれだけ達成できたか、達成できていないならば何が原因なのかを知ることは、知識活動へのモチベーションにつながる。そのために知識活動システムでは、「どのようなプロセスを行い、どのようなアイディアや知識を生み出したか」という知識活動に関するログを記録し、保持することが望ましい。そこで知識活動支援システムでは、プロセスに用いたコンテンツ情報とそのコンテンツから派生したアイディアや知識の情報を記録できる機能を実現する。プロセスから創出されたアイディアや知識を次の議論フェーズで提示することで、より活発な議論が促進され、結果的に新たなフィードバックを得ることが期待できる。
本研究では、知識活動を通じて創出されたアイディアや知識を記録した知識活動のログを知識コンテンツと呼ぶ。後述する知識活動支援システムでは、会議コンテンツを参照しながら知識コンテンツの作成・編集を行うことができる。知識コンテンツを作成・編集することによって、テーマに関してどれだけ作業を行っているか、またどのようなことを疎かにしているかを確認することができる。また、知識コンテンツを議論フェーズで利用することによって、自身の知識活動に関する議論をより円滑に行うことが期待できる。
一般にコンテンツは、テレビ番組や映画、音楽のように多数の人間に対して公開され、何らかのメッセージ性を持つメディアという印象があるが、本研究における知識コンテンツは、コンテンツを作成・管理する人間だけのものであり、第三者に向けて公開することは想定していない。しかし、企業におけるプロジェクトのように複数の人間がグループとして、共通のテーマに関する知識活動を行っている場合は、知識活動コンテンツをグループ内で共有することによって、メンバー間で知識活動の進捗を知ることができる。
本研究で提案する知識活動支援システムにおける知識コンテンツは、以下の情報を含んでいる。
-
ドキュメント情報(テキストや図、表など)
-
キーワードタグ
-
プロセスタグ
システムが知識コンテンツを蓄積するためには、人間が頭の中に持っている暗黙知を、コンピュータに理解可能な形式知としてシステムに入力することが求められる。当然ながら、その表現形式は必ずしもテキストだけとは限らない。イメージを表現するために図式が、物事を対比するために表が利用されるように、図式や表といった非言語の表現方法も知識コンテンツに必要であると考えられる。
時間の経過と共に議論の内容が忘れ去られてしまうように、自身の活動内容も忘れ去られてしまうことが考えられる。そのため、過去に記録した知識コンテンツが忘れ去られ、同じ内容の知識コンテンツが新たに作成されてしまう可能性がある。そのため、会議コンテンツと同じように知識コンテンツにもキーワードタグやプロセスタグを付与することによって、蓄積されている知識コンテンツを整理し、冗長な知識コンテンツの作成を防ぐことができる。
また、知識活動支援システムでは会議コンテンツを利用しながら知識コンテンツの作成を行う。そのため、作成された知識コンテンツは、作成時に利用された会議コンテンツとは意味的な関連があると思われる。そのため、知識コンテンツを作成する際に会議コンテンツに付与されているキーワードタグやプロセスタグを自動的に引き継ぐことによって、ユーザの負担を軽減することができる。
4.3 知識活動支援システム
4.3.1 システム構成
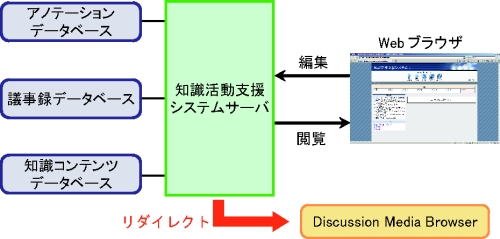
図4.2: 知識活動支援システムの構成図
図に、知識活動支援システムの構成図を示す。知識活動支援システムはWebサーバ・クライアント型のシステムとして実現されている。ユーザはWebブラウザを利用してサーバにアクセスすることによって、会議コンテンツの編集や閲覧などの操作を行うことができる。ユーザが会議コンテンツの編集を行うときはディスカッションマイニングシステムで利用していた議事録データベースから議事録XMLを取得し、編集インタフェースを提示する。編集インタフェースによって付与されたアノテーションはアノテーションデータベースに保存される。また、会議コンテンツの詳細な閲覧要求が発生すれば、Discussion Media Browserへリダイレクトすることで、該当する会議コンテンツを閲覧させる。また、サーバは会議コンテンツを閲覧して創出されたアイディアや知識を記録するインタフェースの提示も担当している。ユーザが入力したアイディアや知識は知識コンテンツとしてデータベースに保存される。また、サーバは蓄積された知識コンテンツを用いた発表資料作成の機能も備えている。
4.3.2 会議コンテンツの編集
再認フェーズでは、議論フェーズで作成された会議コンテンツに対して後から再利用しやすいように編集を行う。ここでいう会議コンテンツの編集とは、会議コンテンツに対して前述したアノテーションを付与することを表す。以下ではその詳細について述べる。
知識活動支援システムにログインするとユーザごとにカスタマイズされたトップページが表示される。このトップページには会議コンテンツの編集や知識コンテンツの記録、発表資料作成などのメニューがあり、それぞれのメニューを選択することによって、必要に応じた機能を利用することができる。
図4.3: 会議コンテンツの一覧ページ
会議コンテンツの編集を選択すると、図のような会議コンテンツの一覧が表示される。ディスカッションマイニングシステムを用いた発表が終了するとこの一覧は自動的に更新される。この一覧は、ユーザが過去に行った発表に関するものとユーザ以外の人間が発表したものの2種類があり、ラジオボックスを選択することによって表示を切り替えることができる。
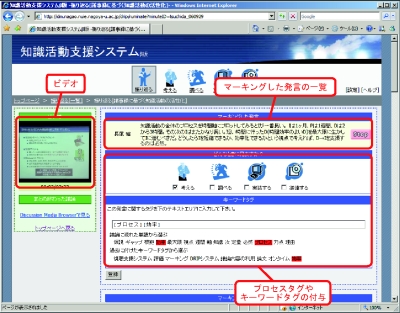
図4.4: 会議コンテンツ編集インタフェース
編集を行いたい会議コンテンツを選択すると、図のような会議コンテンツの編集を行うインタフェースが表示される。左側には発言内容を詳細に閲覧するためのビデオとタグの付与が終了した議論を表示するためのリストが表示されており、右側には発表中、もしくはDiscussion Media Browser上でマーキングを付与した発言の一覧が表示されている。図のようにそれぞれの発言の一覧の下にはキーワードタグとプロセスタグを付与するためのインタフェースが用意されている。以下では会議コンテンツの編集における操作の手順を説明する。
まず、ユーザは自身がマーキングを付与した発言の一覧を見て、その内容を確認する。次にチェックボックスを用いてプロセスタグの付与を行う。また、テキストボックスの中にその発言を表すキーワードタグを入力する。その際、その発言を含む議論セグメントの発言内容から抽出した単語や過去に付与したキーワードタグの一覧にある単語をクリックするとそのタグが自動的にテキストフィールドに入力される。議論セグメントからのキーワードタグ候補の抽出には、Sen†と呼ばれる形態素解析エンジンを用いた。候補は、品詞が固有名詞、一般名詞、未知語のものを採用した。
このようにしてプロセスタグとキーワードタグを入力し終えたら、登録ボタンをクリックする。ユーザが入力した情報はサーバに送信され、アノテーションサーバに登録される。そして、登録が完了した発言の一覧は非表示になり、左側の完了リストに移動する。これをマーキングした発言がすべてなくなるまで繰り返し行うことによって会議コンテンツの編集は行われる。
4.3.3 知識コンテンツの作成・編集
探究フェーズでは、過去の議論内容を効率的に閲覧しつつ、調査や開発、検証といったプロセスを通じて新たなアイディアや知識を創出する。創出されたアイディアや知識は以降の発表に用いる資料の作成や、論文などのドキュメントの作成に再利用することが可能なため、知識コンテンツとして記録を行う必要がある。本節では、知識活動支援システムにおける1)過去の議論内容の効率的な閲覧、2)知識コンテンツの作成・編集という2つの機能について詳しく述べる。
4.3.3.1 過去に行われた議論の効率的な閲覧
過去の議論を振り返ることは、探究フェーズにおけるプロセスの方針を決定する上で有効である。そのため、知識活動支援システムではWebブラウザを用いて過去の議論を容易に閲覧できるインタフェースを備えている。すべての会議コンテンツにはキーワードタグとプロセスタグが付与されており、閲覧したい議論の意味内容や利用したい状況に応じて容易にアクセスすることが可能である。
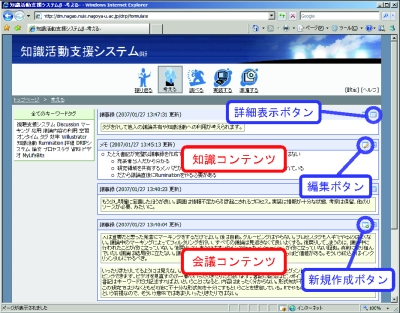
図4.5: コンテンツの一覧表示
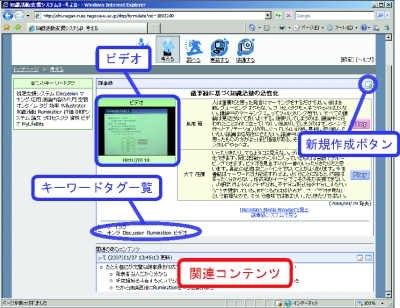
図4.6: コンテンツの詳細表示
トップページには、プロセスタグの内容に合わせたメニューが用意されており、それぞれのメニューをクリックすることによって、それぞれのプロセスタグが付与されたコンテンツの一覧が図のように表示される。この一覧では、同じプロセスタグが付与された会議コンテンツや知識コンテンツの概要が日付順に並べられている。それぞれのコンテンツ表示部分の右上にある詳細表示ボタンをクリックすると、そのコンテンツの詳細が図のように表示される。
コンテンツ詳細のページに表示される情報には、そのコンテンツに付与されているキーワードタグの一覧とそのコンテンツに関連のあるコンテンツの一覧がある。また、会議コンテンツの詳細表示ではその会議コンテンツのタイトルや発表日、発言者名、議論の様子を記録したビデオが表示される。コンテンツ間の関係は会議コンテンツに対して知識コンテンツの作成、知識コンテンツを引用した発表資料の作成というユーザの操作から暗黙的に取得したものである。関連のあるコンテンツを選択すると、そのコンテンツの詳細表示へ移動する。これを繰り返し行うことによって、ユーザがこれまで行ってきた知識活動の過程を把握することが期待できる。
4.3.3.2 知識コンテンツの作成・編集
現在閲覧している会議コンテンツに対して知識コンテンツを作成したいときは、対象となる会議コンテンツ内にある新規作成ボタンをクリックする。すると図のようなインタフェースが現れる。このインタフェースの左側には、対象となった会議コンテンツの内容を引用するためのGUIが用意されており、右側には新しく作成する知識コンテンツに対するプロセスタグ、キーワードタグ、ドキュメント情報を入力するためのGUIが用意されている。プロセスタグやキーワードタグは、対象となっている会議コンテンツに付与されているものがそのまま継承されて表示されており、必要に応じて変更することができる。
テキストはWiki記法により箇条書きや表など多彩な表現を容易に記述することができる。また、左側にあるインポートボタンをクリックすると該当する発言の内容がテキストボックスに自動的に挿入される。これによりユーザのテキスト入力の負担を軽くすることができる。そして、プレビューボタンをクリックすると現在入力している内容がどのように表示されるかを確認することができる。
登録ボタンをクリックすると入力された知識コンテンツに関する情報がシステムに送信され、プロセスタグやキーワードタグはアノテーションデータベースに、知識コンテンツのドキュメント情報は知識コンテンツサーバに保存される。同時に登録された知識コンテンツには、その時閲覧していた会議コンテンツから派生したというリンク情報も登録される。一度登録された知識コンテンツは何度でも内容を編集することができる。
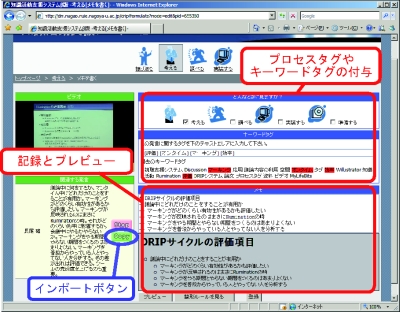
図4.7: 知識コンテンツの記録インタフェース
4.3.4 知識コンテンツを利用した発表資料の作成
様々なプロセスを通じて蓄積されたアイディアや知識を発表資料に過不足なく盛り込むことは、その議論を活性化させ、知識活動へのフィードバックを高めるという点で有効であると考えられる。そのため、本研究で提案するシステムでは探究フェーズで蓄積した知識コンテンツを利用して発表資料の作成を支援する。ここでは以下のような流れで発表資料を作成することを想定している(図)。
-
どのように発表を行うかという構成を決定する(発表テンプレートの作成)
-
蓄積した知識コンテンツを発表構成の適切な箇所にインポートして発表内容を作成する(発表テンプレートへの記述)
-
作成された発表内容に基づいて発表資料を生成する(発表資料への変換)

図4.8: 発表資料作成までの流れ
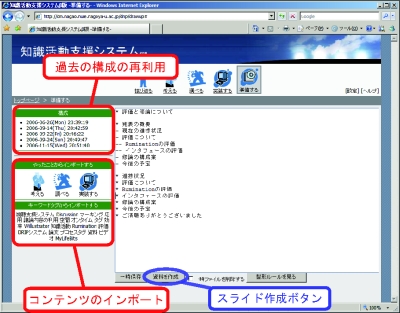
図4.9: 発表資料の作成インタフェース
トップページのメニューから発表資料の作成を選択すると図のようなインタフェースが表示される。左側には資料作成を支援するための機能であるインポートを行うためのメニューと過去の発表資料作成に利用された構成を選択するメニューが用意されており、右側には発表資料のタイトルやテキストを入力するためのテキストボックスがある。発表資料の内容はWiki記法を用いて記述を行う。
ユーザは最初に、発表をどのような流れに基づいて行うかという構成を作成する。研究活動を例とすれば、「背景・目的→アプローチ→実験結果→考察→まとめ→今後の課題」という構成が考えられる。また、左側にあるメニューから日付を選択するとその時に利用した発表資料の構成を利用するかどうかを尋ねるダイアログで表示され、「OK」ボタンをクリックするとその構成が右側のテキストボックスに自動的に挿入される。
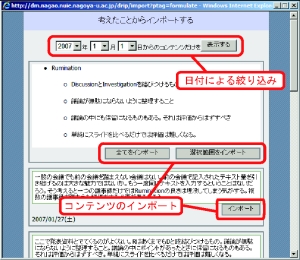
図4.10: コンテンツのインポート画面
これまで蓄積したコンテンツを発表資料に取り込むために、本システムではインポートと呼ばれる機能を備えている。インポートにはプロセスタグを用いて行うものとキーワードタグを用いて行うものの2種類がある。左側のメニューからプロセスタグ、もしくはキーワードタグをクリックすると図のような画面が現れる。この画面には選択したタグが付与されているコンテンツの一覧が表示されている。このリストは日付による絞込みを行うことができ、過去に行った発表からの差分を表示することで、進捗報告のための資料を作成する場合に適している。発表資料に必要となる知識コンテンツや会議コンテンツを選択し、インポートを行うと発表構成を記述するテキストエリアにその内容が挿入される。ユーザはこの作業を繰り返し行うことで発表内容を完成させていく。作業を途中で中断するときは「一時的に保存」ボタンをクリックすると現在の作業内容がサーバに送信され、再び資料作成インタフェースを開くとその内容が復元される。
作成された発表内容を送信すると、システムはXMLベースの中間言語を生成し、その中間言語から生成されたMicrosoft PowerPoint文書をブラウザベースでダウンロードすることができる。中間言語を生成することで論文や報告書といったPowerPoint以外の資料を作成することができると考えられる。この中間言語にはアイディア・知識や発言のインポートに関する情報が保存されている。つまり、この中間言語から生成される資料には作成に用いられた情報に対するリンクを持つことができる。
4.4 まとめ
本章では、議論フェーズで獲得された議論内容をDRIPサイクルの中で再利用するための仕組みについて考察し、その考察に基づき知識活動支援システムを構築した。まず、議論内容の効率的な閲覧を行うために再認フェーズでは、会議コンテンツに対するアノテーションの付与を行う。そして、探究フェーズでは、会議コンテンツを閲覧しながら、新たなアイディアや知識を創出する。創出されたアイディアや知識は知識コンテンツとして記録される。そして、集約フェーズでは蓄積された知識コンテンツを引用することで以降の発表に利用する発表資料の作成を行う。このような作業を繰り返し行うことによって、システムを利用している人間の知識活動が、過去の議論を適切に反映した、より密度の濃い効率的なものになると考えている。
5 実験
本研究で提案したDRIPサイクルにおいて最も特徴的な点は、これまで暗黙的に行われていた議論内容に対する解釈の付与を、再認フェーズとして意識的に行う点である。そこで本章では、知識活動における再認フェーズの必要性を検証するための実験を行った。
5.1 実験方法
本実験における被験者は男性7名であり、被験者らには2006年4月14日から2007年1月19日までの約10ヶ月間、ディスカッションマイニングシステムを用いて自身の研究活動に関する発表・議論を数回行ってもらった。
その後、それぞれの被験者に対して、自身の発表で行われた議論の一覧を配布した。この一覧はディスカッションマイニングシステムで取得した議論セグメントの一覧である。そして、日付の古い順に全ての議論セグメントを見直してもらい、それぞれの議論セグメントが、以下の表に示す5つのカテゴリのどれに該当するかを判定・回答してもらった。
|
A |
現在その議論の内容を覚えており、なおかつすでにその内容に基づいた活動を行った(議論後に「その内容については作業を行わない」と判断したものも含める) |
|
B |
現在その議論の内容を覚えているが、いまだにその内容に基づいた活動を行っていない |
|
C |
その議論の直後で、意識的に保留(今すぐ取り組まなければならないものではないと判断した)にしたため、現在はその内容を忘れてしまっている |
|
D |
議論の直後でも全く意識せず、現在もその内容を忘れてしまっている |
|
その他 |
質疑応答で終始していたり、その議論の中で問題が解決している(書記の入力ミスといった議事録の不具合も含める) |
5.2 実験結果と考察
被験者の回答から得られた結果を表に示す。この表では、実験期間を1ヶ月ごとに分け、それぞれの月で行われた議論に対する判定結果をカテゴリごとに分類したものである。たとえば表の緑色の箇所は、2006年4月に行われた全ての議論セグメント31個のうち、12個がカテゴリDに分類されたことを表している。そして右側に、その月に行われた議論セグメント全体に対する割合を示す。さらに、実験期間を前期(2006年4月から2006年8月まで)と後期(2006年9月から2007年1月まで)の2つに分けた時の結果を表の下部に示す。2006年8月と2007年1月の議論セグメント数が少ないのは夏期休暇と冬期休暇が重なったためである。また、被験者一人当たりの平均発表回数は9.57回であり、1回の発表における議論セグメントの平均数は9.84であった。
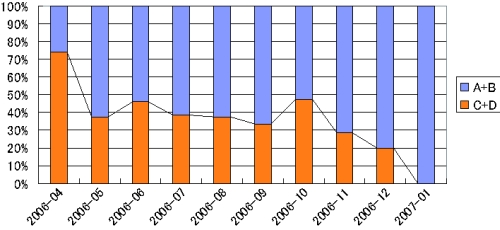
図5.1: 内容を覚えている議論セグメント数の推移
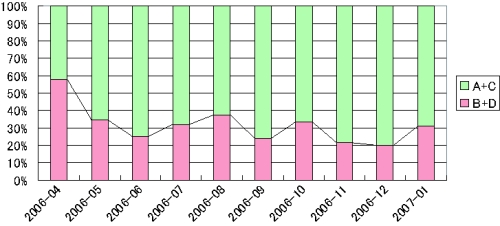
図5.2: 有効的に利用された議論セグメント数の推移
まず、被験者全体における傾向について分析した。なお、説明のため、時点i(2006年4月から2007年1月まで順にとする)において、カテゴリA、カテゴリB、カテゴリC、カテゴリDに分類された議論セグメントの割合をそれぞれ
、
、
、
とおく。たとえば、2006年8月(i=4)においてカテゴリAに分類された議論セグメント数の割合は43.8%であるため、
%である。
図に各月におけると
の割合の推移を示す。カテゴリA、もしくはカテゴリBに分類された議論セグメントは、実験を行った時点でその内容を覚えているものであり、カテゴリC、もしくはカテゴリDに分類されたものはその内容を忘れていることを表している。つまり、図は時間の経過と共に議論内容がどれだけ忘失されていくかを表している。このグラフにおいて、より以前に行われた議論ほど、内容を忘れてしまっている議論セグメントの数が多いという傾向が分かる。つまり、議論が終わってから時間が経過すればするほど議論内容を忘れてしまうことが確認できる。
また、図に各月におけると
の割合の推移を示す。カテゴリBは議論内容を覚えていながらいまだに着手していない議論を表しており、カテゴリDはこれまで全く注目されていない議論を表している。そのため、いずれかのカテゴリに含まれる議論は、知識活動において有効的に利用されていない議論とみなすことができ、図の
は、知識活動を行う上で有効に利用されている議論セグメント数の推移を表していると考えられる。2006年4月だけ
の数が他の月に比べ大きな値をとっているが、全体的に見ればその値に変化はないとみなすことができる。つまり、知識活動において有効に利用される議論の数は時間の経過には依存しない傾向がある。
続けて被験者ごとの傾向について分析を行った。まず被験者ごとに内容を覚えている議論セグメント数の推移を調べたが、共通点を見出すことはできなかった。次に被験者7名のうち5名に対して、カテゴリA、もしくはカテゴリCに含まれる議論セグメント数を前期・後期の順に並べたグラフを図に示す。被験者7名のうち、1名は「その他」に含まれる議論セグメントの数が多く、前期に対して後期の有意セグメント数が非常に少ないためノイズとして除外した。そして、もう1名は前期と後期の間で研究テーマの大きな変更があったため除外した。また、被験者によって発表を全く行っていない月が存在するため、各月ではなく前期・後期という分け方を採用している。前期に対して、後期は議論が終了してから経過した時間が短いにも関わらず、有効的に利用されている議論セグメント数はあまり改善していないことがこのグラフから分かる。
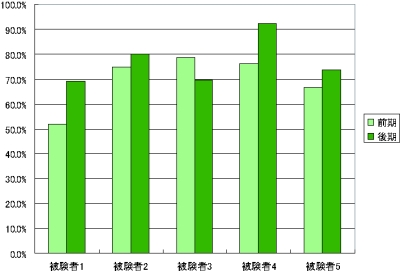
図5.3: 被験者ごとの有効に利用された議論セグメント数の推移
実験の結果から得られた傾向をまとめると以下のようになる。
-
被験者全体の傾向として、時間が経過するほど内容を忘れてしまった議論セグメントの数は増える
-
時間の経過に関わらず知識活動の中で有効的に利用される議論セグメントの数は変わらない
前者の傾向から、再認フェーズにおいてアノテーションを付与する作業は、議論が終了した直後に行うことが望ましいことが分かる。また、後者の傾向について、被験者全体、被験者ごとに考察を行った。表\ref{result1}において、カテゴリDに含まれる議論セグメントの割合を、前期と後期で比べてみると大きく変化していないことが分かる。つまり、被験者全体において有効的に利用された議論セグメント数が改善されない原因は、カテゴリDに分類されるような議論の存在であると考えられる。また、被験者ごとにカテゴリB、カテゴリDの割合を分析したところ、被験者ごとにその割合はばらつきがあり、傾向を見出すことはできなかった。これは発表テーマの内容や発表回数など様々な要因が被験者ごとによって異なるためだと考えられる。カテゴリBに含まれる議論を改善するためには、被験者のモチベーション自体を改善する必要があるため、システムによって支援することは困難である。しかし、カテゴリDに含まれる議論に関しては、再認フェーズにおいてアノテーションを付与することによって少なからず改善できる可能性がある。
5.3 まとめ
今回の実験結果から、時間が経過するほど議論内容が忘失されていくことが確認された。また、時間の経過に関わらず有効的に活用されていない議論が存在することも分かった。再認フェーズを行うことによって、このような議論を減らすことができると思われる。
しかし、今回の実験はDRIPサイクルにおいて再認フェーズが必要であることを示すための予備的な実験だった。本来ならば、一人の被験者に対して再認フェーズを行わない期間と行う期間を設け、今回の実験で用いた指標が再認フェーズの開始前後でどのように変化するかを調べる必要があった。だが、有意な実験結果を得るためには長い時間が必要であるため、本論文ではそこまでの実験を行うことができなかった。今後は本研究を発展させると共に、知識活動システムに関する評価と合わせて引き続き、評価実験に取り組んでいく予定である。
6 関連研究
本章では、本研究に関連する研究をいくつか紹介する。ただし、筆者が調べた限りにおいて、記録された議論内容に対して、個人の解釈を加えることによって、知識活動の中で効率的に再利用する手法に関する研究はいまだ存在しない。そこで、知識活動支援システムの要素技術であるディスカッションマイニング、Discussion Media Browserに関連する研究をいくつか報告する。
6.1 議論内容の記録に関する研究
6.1.1 LiteMinutes
会議で行われた議論の様子を記録する研究は数多く行われている。ChiuらはLiteMinutesと呼ばれるWebブラウザ上でマルチメディア議事録を作成するシステムの研究を行っている。LiteMinutesは、カメラが設置された部屋の中でスライドを用いた議論を行い、議論の様子を映像・音声情報として記録する。また、書記が無線ラップトップPC上で専用のツールを用いることで、議論内容をテキストとして入力する。テキストの入力された時間は自動的に取得され、その時間情報を用いて関連するスライドや映像・音声情報と入力されたテキストとの間にリンク情報を付与する。
時間情報を用いて、関連するスライドや映像・音声情報とリンクする点ではディスカッションマイニングに類似する点が多い。しかし、これだけでは発言時間による正確な映像・音声情報のセグメンテーションを行うことができないという問題点がある。LiteMinutesでは、メールによってセグメンテーション情報の修正を行っているが、ディスカッションマイニングでは、デバイスを用いることで正確なセグメンテーション情報を暗黙的に取得することができる。また、書記が入力したテキスト間には意味構造が付与されていないため、効率的な閲覧を行うことができないという問題点もある。
6.1.2 Portable Meeting Recorder
議論の様子を映像・音声情報として記録することによって、発言内容だけでは補えないノンバーバルな情報も合わせて閲覧できるため、より深い理解につながることが期待できる。しかし、一般に映像・音声情報は情報量が多いため、効率的に閲覧するためにはインデックス情報が必要となる。
映像・音声情報を用いて議論の様子を記録する研究例としてPortable MeetingRecorderがある。この研究では全方位カメラと4つのマイクを用いて記録を行う。4つのマイクによって発言者の方向の特定し、その方向の映像情報から人物抽出をする。このように音声処理や映像処理を組み合わせて、映像・音声情報を効率的に閲覧するためのインデックス情報を自動的に付与する。同時にマイクによって取得された発言内容は、音声処理によってテキスト化され、先ほどのインデックス情報と共にメタデータとしてXML形式で記述される。
このようにして取得された映像・音声情報とメタデータは、MuVIEと呼ばれるインタフェースで閲覧することができる。メタデータを利用することによって、特定の人物が行っている発言だけを閲覧したり、スライドやホワイトボードのビデオを閲覧するなど、ユーザの様々な目的に合わせた閲覧方法を提供することができる。
このシステムで作成されるインデックス情報は参加者の動作や音声のパワーなどを利用して自動的に取得されるため、作成のコストはディスカッションマイニングより低い。しかし、これらの情報は意味内容を解釈した結果得られる情報ではないため、必ずしも閲覧者の目的に合致した閲覧方法を提供できるとは限らない。それに対してDiscussion Media Browserでは、コストはPortable Meeting Recorderよりも大きくなるが、導入・継続という発言タイプによる議論のセグメンテーション情報、d-Buttonによる発言に対する賛成や反対の数のように議論の文脈情報を考慮した閲覧インタフェースを提供することが可能である。
6.1.3 MinuteAid
議論の参加者がインタラクティブに議論の内容を編集する研究例としてLeeらのMinuteAidがある。MinuteAidは、Webサーバ・クライアント型のシステムであり、参加者はIntelligent Meeting Roomと呼ばれる専用の環境の中で会議を行う。会議に使用されるスライド情報をPresentation Recorderと呼ばれるデバイスによって、議論の様子をMeeting Recorderと呼ばれるデバイスによって取得する。また、参加者はクライアントPC内のMicrosoft Wordを用いて、議事録の編集を行う。その際、ユーザは必要に応じてリクエストを発行する。リクエストが発行されると、サーバはリクエストが発行された時間に対応するスライドの画像や音声情報が自動的にWordファイルに挿入される。ユーザはそのファイルを自由に編集することで個人用の議事録の作成を行う。
個人用にカスタマイズされた議事録を作成するという点では、本研究と似た思想を持っている。しかし、知識活動において会議は繰り返し行われるものであり、議事録は会議後の活動において利用されるものである。この研究では、カスタマイズされた議事録を用いた活動の支援や次の発表に向けた発表資料の作成支援など知識活動への応用にまでは至っていない。
6.2 議論の構造化・可視化に関する研究
6.2.1 gIBIS
議論の内容を構造化・可視化することによって閲覧者の議論内容に対する理解を深めることが期待できる。その代表的な研究例として挙げられるのが、議論支援グループウェアのIBIS(Issue Based Information Systems)である。IBISでは、共同作業時の問題解決において、発言をIssue(問題)、Position(立場)、Argument(賛否)の3種類に分類し、それらの関係をリンクとするグラフ構造によって議論を構造化する。そして、IBISをベースとしてGUIによる議論支援を行うシステムがgIBISである。gIBISは議論構造を表すグラフを表示するブラウザ、グラフを構成するノードに関する情報を表示するノードインデックスウィンドウといったコンポーネントから構成されており、ユーザはこれらのコンポーネントを利用して直観的な操作で議論構造の編集を行う。
IBISやgIBISは議論を構造化し、それを可視化することにより、議論の進行の流れを把握しやすくしたという点で意義がある。しかし、議論で発生する発言すべてをこれらのモデルで提案している発言のタイプのいずれかに分類することが難しいという問題点がある。そのため、ディスカッションマイニングでは、議論の構造化を議論のセグメンテーションと捉え、ユーザが発言時に議論札を用いて導入・継続のどちらかのタイプを選択するという手法を選択している。これにより、ユーザは、自分の発言によって話題が切り替わるかを判断するだけでよくなり、ユーザ側の負担を軽減することができる。
また、作成されたグラフをインタラクティブに操作することによって、より深い議論内容の理解を行うことができると考えられるが、これらのシステムではそこまでの考察は行われていない。Disucssion Media Browserでは「導入」「継続」という発言タイプによるリンク情報の他に、書記が入力したリンク情報を組み合わせてグラフビューを提供している。そしてユーザは、検索バーやシークバーを併用しながら、グラフビューをインタラクティブに操作することによって、議論内容をより深く理解できるだろう。
6.2.2 Discussion Structure Visualizer
議事録に含まれる言語情報を用いて自動的に議論の構造化・可視化する研究としてDSV(Discussion Structure Visualizer)が挙げられる。DSVでは、従来のテキスト処理による話題構造の抽出に関する研究のような話題の切れ目の同定だけを行うのではなく、話題と話題との関係まで考慮した構造化を目指している。
この研究では、話題の境界を決定するために、類義語の使用(言い換え)や同じ単語の繰り返しといった語彙的結束性を用いている。そして、結束度の低いところから順に話題の境界とみなす。その後、それぞれの話題の特徴ベクトルを求め、特徴ベクトル間の類似度を計算し、その値が閾値以上のものに関してはリンク情報を付与する。分割される話題の数やリンクの数はパラメータによって自由に変更することが可能になっている。
話題や話題間の関係の抽出をテキスト処理で行っているため、必ずしもその精度は高いものであるとは限らない。ディスカッションマイニングでは、人間が様々なデバイスを用いて暗黙的にメタデータを入力するため、その精度はより高いものになる。また、ユーザがDiscussion Media Browser上で会議コンテンツを閲覧しながらアノテーションを行うことによって、より詳細な議論間の関係を抽出することも可能である。
7 今後の課題と展望
本論文では、知識活動に内在するプロセスの一つである議論に着目し、議論内容を獲得し、効率的に再利用するための仕組みについて述べた。本章では、本論文で提案した知識活動支援システムをより有益なものにするための今後の課題と展望について述べる。
7.1 知識活動グラフの作成・利用
近年、ライフログのように人間の行動をデジタルデータとして保存し、それに基づいて追体験したり、記憶の想起を促すようなシステムに関する研究が広く行われている。代表的な例としてはFertigらのLifestreamsやGemmellらのMyLifeBitsが挙げられる。特にMyLifeBitsでは、読んだ本や聞いたCDだけでなく電話やメールの内容に至るまで様々なデジタルコンテンツの記録を目指している。
ライフログのように人間の活動を記録するという考え方は、知識活動支援システムにも応用することができる。知識活動を行う過程の中には、成功しているものだけではなく、失敗したことも数多く存在するだろう。しかし、失敗や失敗の積み重ね自体が非常に重要な意味を持つことも考えられる。別の見方をすれば、それらの失敗は当時扱っていたテーマにおいて「失敗」要因となっているだけであり、別のテーマから捉えなおしてみれば「成功」要因となる可能性もある。本研究では、このように別の視点から見れば価値のある失敗例も再利用できる仕組みの実現を視野に入れている。そのためには、知識活動に関するすべての行動を記録することが必要になるだろう。そして、その記録もただ利用されたコンテンツをかき集めたものではなく、その利用に関する文脈情報も含めた記録が有効であると考えられる。
知識活動支援システムでは、会議コンテンツを引用して知識コンテンツを作成したり、知識コンテンツを用いて発表に利用するスライドを作成する機能を有している。ユーザがこれらの機能を繰り返し利用することで、会議コンテンツや知識コンテンツ間には図のような関連性を見出すことができる。自然言語処理や画像処理などの機械処理によって、コンテンツ間の関連性を自動的に取得する研究はこれまでに数多く行われている。しかし、機械処理による意味内容の解釈は困難であるため、その精度は高いものではない。一方、知識活動支援システムでは、ユーザの操作からコンテンツ間の関連性を暗黙的に獲得することができる。
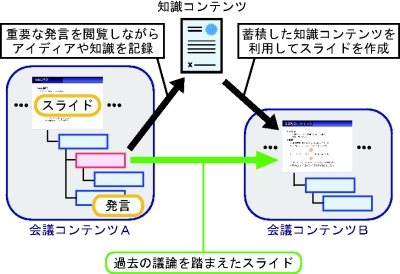
図7.1: 会議コンテンツ・知識コンテンツ間の関係
また、知識活動の中で利用されるコンテンツは、会議コンテンツや知識コンテンツだけにとどまらず、Webページや論文、画像やビデオなど数多く存在する。つまり、様々なプロセスにおけるコンテンツの利用情報を知識活動支援システム上で統合的に扱うことによって、コンテンツをノード、コンテンツの利用・被利用という関係をリンクとするグラフ構造を取得することが可能になる。このグラフ構造が時間の経過と共にどのように変化するかを追跡することによって、ある知識コンテンツがいつ、どのようなコンテンツを利用して作成されたのかを把握することができる。このように編集履歴を含めたコンテンツのグラフ構造を作成することによって、ユーザの知識活動の過程を知ることができると考えられる。本研究では、このようなグラフ構造を知識活動グラフと呼んでいる。
7.1.1 引用情報を用いた知識活動グラフの作成
本研究では、知識活動グラフの作成を行うためにコンテンツの引用情報に着目した。多種多様なコンテンツを引用可能にするためには、任意のコンテンツの内部構造を記述できる柔軟な表現形式が必要となる。そこで梶らが研究・開発を行っているElementPointerと呼ばれる表現形式を利用する。ElementPointerは、コンテンツのURIの後にコンテンツのどの部分を指し示しているかをURI形式で表現する。以下にElementPointerの具体例を示す。
http://domain1/picture.jpg#epointer (http://domain2/dim.rdfs#dim(10px,20px,30px,40px))
ElementPointerでは、#epointerより前がコンテンツのURIを、#epointerより後ろのスキーマURIによってそのコンテンツ内のどの部分を指し示しているかを表現している。スキーマURIに続く引数の順番と意味はRDFS(RDF Schema)により自由に定義することができる。この例ではイメージ上における、(10px,20px)を始点として幅30px、高さ40pxの矩形範囲を表している。
図7.2: 論文コンテンツの引用
ElementPointerを利用して論文コンテンツを引用する例を図に示す。論文の閲覧インタフェースを提供するサービス側でElementPointerを定義することによって、ユーザは論文の任意の部分要素を選択することができる。この例では論文コンテンツ中の2つの段落を選択した場面を表している。そして、引用されたコンテンツを用いて新たな知識コンテンツやスライドを作成する。
その他にも筆者の所属する研究室では、ホワイトボードを用いたミーティング情報を獲得するシステムや、論文の閲覧時に付与されたメタデータを利用して論文の作成支援を行うシステムなど知識活動を支援するシステムの研究・開発が行われている。これらのシステムで作成・利用されるコンテンツのそれぞれに対してElementPointerを定義し、コンテンツの引用情報を管理することによって、多様なコンテンツが引用という関係で関連づけられた知識活動グラフを作成することが可能となる。
7.1.2 知識活動グラフの利用
以上のようにコンテンツの引用情報を用いて、知識活動グラフを作成する仕組みを実現することができる。この知識活動グラフを用いることによって、様々な応用が可能になる。
まず、知識活動グラフを可視化することによって実現できる応用について述べる。知識活動グラフには「そのコンテンツがどのような考えに基づいて作成されているのか」という背景情報が引用情報という形で記録されている。この背景情報を効果的に閲覧できるインタフェースを提供することによって、そのユーザの知識活動に関する背景知識の獲得を支援することができる。活動を行っている本人が閲覧することで、現在行っていることの位置づけを確認したり、疎かにしていることを確認することができるため、よりよい活動を行うことが期待できる。また、第三者が知識活動グラフを閲覧することによって、知識の伝承を効果的に行うことができる。特に後者の応用は、人材の流動化が進む現代社会にとって非常に重要な貢献をもたらすことが予想される。この応用例として、前述したDiscussion Media Browserの拡張が挙げられる。これまでのDiscussion Media Browserは単一の会議コンテンツしか閲覧することができなかったが、知識活動グラフを利用することによって、複数の会議コンテンツにまたがった閲覧を行うことができ、より深い議論内容の理解を実現することができるだろう。
また、知識活動グラフを可視化するだけでなく、演算を行うことで、さらなる知識活動支援を実現することができる。たとえば、知識活動グラフの構造の類似性を計算することで、自分と似た知識活動を行っている別の人間を発見することができ、新たなコミュニケーションを生み出すきっかけを与えることができる。また、グラフ間の差分を計算することによって、より優れた成果を上げるためにはどのようなことを行えばいいのかを推測することが可能になるかもしれない。このように知識活動支援システムによって作成された知識活動グラフは様々な可能性を秘めていると考えている。
7.2 グループの知識活動サイクルの支援
本論文で述べた知識活動支援システムの対象となる知識活動は、個人によって行われるものに限定されている。しかし、実際には個人だけでなく、複数の人間がグループを形成して知識活動を行うことも多い。今後はグループによる知識活動の支援にも取り組んでいく予定である。
グループで知識活動を行うためには、グループのメンバー全員がテーマに対する取り組み方やお互いの進捗状況を把握していることが必要になる。そのため、これまでのグループウェアという研究分野の考え方も取り入れながら知識活動支援システムの拡張を行う。その際、重要な点の一つとして、グループ内におけるコンテンツの共有が挙げられる。たとえば、参考になる文献を他のメンバーにも提示することでグループ全体で同じ知識を共有することができる。また、グループのメンバーが作成した図的情報もWillustratorのような仕組みを用いて、Web上で(編集履歴を含めた)イラスト情報を共有することによって、新たなコンテンツを作成する際に再利用することができる。
そして、知識活動支援システムを繰り返し利用することで、個人の知識活動グラフが作成されるように、グループの知識活動グラフを作成することが考えられる。その際考慮しなければならない点は、メンバーの多様性である。同じグループ内でも担当している作業が異なれば、保有している知識の量や内容も異なる。そのため、ユーザごとに知識活動グラフの閲覧方法や知識活動グラフを用いた知識活動の支援方法を適合させる必要がある。
7.3 知識活動支援システムの運用と評価
本研究で提案した知識活動支援システムの有効性を検証するためには、作成した知識活動支援システムを公開・運用し、会議コンテンツに対するアノテーションの付与、知識コンテンツの作成・編集を実際に行ってもらう必要がある。そして、第5章で課題としていた再認フェーズの有効性の評価と合わせて知識活動支援システムの性能に関する評価を行っていきたいと考えている。そこから得られた知見に基づいて、知識活動支援システムの改良を行っていく予定である。
8 おわりに
本研究では、アイディアや知識を創出する知識活動に内在する様々なプロセスの中でも特に議論に着目し、議論内容を記録した会議コンテンツを効率的に再利用することで個人の知識活動の支援を行う仕組みを提案し、それを具体的に実現した。
まず、知識活動を議論中心の複数フェーズからなるサイクルとしてモデル化した。DRIPサイクルと呼ばれるこのサイクルは、議論を行うことで参加者から様々な意見やアドバイスを獲得する議論フェーズ、獲得した議論内容を後から効率的に再利用するために整理する再認フェーズ、整理された議論内容に基づいて新たなアイディアや知識を創出する探究フェーズ、蓄積されたアイディアや知識を再利用して次の発表で用いる発表資料の作成を行う集約フェーズから構成される。本研究で議論の重要性を指摘する以前から、議論中におけるメモの記録などを通じて、議論内容を後から再利用しようという試みは様々なところで行われてきた。しかし、そのための明確な方法論やその支援ツールなどが開発され、運用されている例はほとんどない。本研究では、知識活動の中でも特に重要な役割を果たしている議論の内容を知識活動の中で有効に再利用するために、このような行為を再認フェーズという知識活動の重要な一つのフェーズとして実行することをこのサイクルの中で提案した。
そして、次にこのサイクルに基づいて実際に知識活動を支援するシステムを構築した。まず、議論内容を会議コンテンツとして記録するためにディスカッションマイニングと呼ばれる技術を実現・拡張した。ディスカッションマイニングは、様々なデバイスやツールを用いて発言者IDや発言内容、発言テキストなどのメタデータと議論の様子を記録した映像・音声情報を組み合わせたマルチメディア議事録の作成を行うことができる技術である。Discussion Media Browserと呼ばれる会議コンテンツ閲覧システムを用いることで、ディスカッションマイニングによって作成された議事録を会議コンテンツとして効率的に閲覧することができる。
このようにして獲得された議論内容を効率的に再利用するために、再認フェーズにおいてユーザは、会議コンテンツに対してマーキングやキーワードタグ、プロセスタグという3つのアノテーションの付与を行う。ユーザが重要であると判断した発言に対してマーキングを付与し、その発言を含む議論セグメントに対してキーワードタグやプロセスタグを付与する。
探究フェーズでは、会議コンテンツに付与されたタグとDiscussion Media Browserを利用して効率的に過去の議論内容を反芻し、新たなアイディアや知識を創出する。このアイディアや知識は、知識コンテンツとしてシステムに記録される。その際に閲覧していた会議コンテンツを引用して知識コンテンツを作成することによって、会議コンテンツと知識コンテンツとの間には意味的なリンク情報が暗黙的に付与される。
活動の成果をより正確に他者に伝達し、より多くのフィードバックを獲得するために集約フェーズでは、これまでに蓄積された会議コンテンツや知識コンテンツを引用することによって、発表資料の半自動的な作成を行う。そして、再び議論フェーズで議論を行うことによって、新たなフィードバックを獲得することができる。そのフィードバックを繰り返し取り入れていくことによって、知識活動は発展していく。
本研究では、議論を中心とする知識活動の支援を目指してきたが、その他の調査や実装といった様々なプロセスも統合することによって、ユーザの知識活動全般を効率的に再利用できる仕組みを提供することができると考えている。また、システム上で行われた知識コンテンツの編集履歴や、知識コンテンツの作成・編集に利用したコンテンツに関する情報を処理することによって、次に行うべきことを教えてくれるシステムや、自分と関連する知識活動を行っているコミュニティを発見できるシステムといった応用システムの構築も可能になるだろう。
謝辞
本研究を進めるにあたり、指導教員の長尾確教授には、研究に対する心構えや研究テーマに関する全般的なアドバイス、論文の添削など、様々な場面で助けていただきました。心より御礼申し上げます。ありがとうございました。
また、大平茂輝助手には、プロジェクトゼミや研究室全体のゼミにおいて貴重なご意見を頂きました。そして、自分が所属するプロジェクトのリーダーである友部博教さんには、研究的な面やプライベートな面において、様々なバックアップをして頂きました。深く感謝いたします。
同じ博士課程における先輩である梶克彦さん、山本大介さんにはプログラミングに関するアドバイスや、これからの研究活動におけるアドバイスを頂きました。本当にありがとうございました。
伊藤周君、成田一生君、林亮介君、石戸谷顕太朗君にはプロジェクトの仕事や自分の研究に関するサポートをして頂きました。本当にありがとうございました。
また、学部生の増田智樹君や金田哲広君には、修士論文の執筆にあたって、非常によい刺激を与えてくれました。ありがとうございました。
そして、長尾研究室秘書の金子幸子さんには研究室生活全般に関するサポートをしていただきました。この場を借りて御礼申し上げます。
最後に、自分の我侭に文句も言わず、ひたすら自分を見守り続けてくれた両親に心から感謝の気持ちを伝えたいと思います。本当にありがとうございました。