
対面式会議コンテンツの作成と議論中におけるメタデータの可視化
概要
我々は,ディスカッションマイニングと呼ばれる,人間同士の知識交換の場である対面式会議から,映像・音声情報やテキスト情報,議論構造などの実世界活動に関するメタデータを獲得・記録することで,再利用可能な会議コンテンツを作成する技術に関する研究・開発を行っている.本研究では,ディスカッションマイニングによって獲得されたメタデータの妥当性を検証するための評価を行った.また,獲得されたメタデータを議論中に可視化することにより,議論の活性化を促す仕組みの開発を行った.
1 はじめに
我々は日常の活動として会議に携わる機会が多い.何らかの問題事項に関する意思決定を目的とするものもあれば,お互いのアイディアを出し合いブラッシュアップするブレインストーミングを目的としたものまで,我々は多種多様な会議に囲まれている.人間同士のコミュニケーションを中心とする社会の形成には,他者との意見交換の場となる会議は不可欠なものである.会議には,参加者が一堂に会して顔をつき合わせて行う対面・同期型のほかに,遠隔会議システムやチャットシステムを用いて行われる非対面・同期型や,掲示板やEメールに代表される非対面・非同期型といった様々なタイプが存在する.我々は,議論の発言内容だけでなく,発言者や参加者の様子,あるいは会議資料など多くの重要な情報が含まれている対面・同期型の会議に着目している(対面・非同期型の会議は存在しないため,以下では対面式会議と呼ぶ).
対面式会議には,一堂に会するという高いコストを掛けるだけのメリットがある.最大のメリットは,発言テキストや音声など,会議中にやりとりされるメディア形式やアクセス方法が制限されないということである.たとえば,開発中のロボットやWeb アプリケーションについて会議を行う場合,写真や動画で見るよりも,実際にロボットに触れたり,デモをしたりしながら説明する方が,意見を引き出すうえではるかに重要だろう.対面式会議は,会議中に起こる様々な事象,同席した参加者の行為や雰囲気までをもありのままに共有することに意義があると考えている.
我々は,ディスカッションマイニングと呼ばれる,人間同士の知識交換の場である対面式会議から,映像・音声情報やテキスト情報,議論構造などの実世界活動に関するメタデータを獲得・記録することで,再利用可能な会議コンテンツを作成する技術に関する研究・開発を行っている.ディスカッションマイニングでは,発言テキストや議論構造のように,自動認識技術では取得が困難な,議論に関するメタデータの入力を人間が行っている.そのため,取得されたメタデータは,ヒューマンエラーによって発生したノイズを含んでいる,もしくはユーザの意図を一部しか反映していない可能性がある.本稿では,長期にわたる運用によって得られた会議コンテンツを詳細に分析することで,メタデータの評価を行った.
また我々は,獲得したメタデータを議論中に可視化することによって,議論の活性化を促す仕組みを開発している.具体的には,議論中に取得しているメタデータをリアルタイムに可視化することで現在行われている議論の流れを把握するための仕組みと,過去に行われた議論を効率的に検索・閲覧することで参加者の発表・議論に対する理解を促す仕組みについて述べる.
2 ディスカッションマイニング
我々は,大学研究室におけるゼミを対象にディスカッションマイニングと呼ばれる技術に関する研究・開発を行っている.ディスカッションマイニングには,2つの目的がある.1つは映像・音声情報や,テキスト情報,議論構造といった実世界活動に関するメタデータの獲得による会議コンテンツの作成であり,もう1つは作成された会議コンテンツの再利用に基づく会議後の知識活動の支援である.本章では,ディスカッションマイニングにおけるメタデータの取得方法に関する立場や,メタデータの取得を行うために開発したシステムについて述べる.
2.1 メタデータの取得
従来,会議コンテンツはテキストで記録することが中心だったが,近年では計算機技術の発達によって様々なコンテンツを組み合わせることが可能になっている.平島らは,発表資料や静止画などのコンテンツを,参加者が協調的に会議コンテンツに取り込むシステムを提案している.その中でも特に映像・音声を組み合わせる研究が数多く行われている.これらのシステムが生成する会議コンテンツでは,会議参加者の話す様子や会議場全体の雰囲気などテキストでは表現することが困難であった情報も提供することができる.
しかし,動画像に含まれる情報量は膨大なものであり,そこから議論理解・意味解釈を行うには閲覧者自身による情報処理が必要となる.閲覧者自身による情報処理を容易にするためには,会議に関するメタデータが有効である.具体的なメタデータとしては,映像・音声や発言テキストだけでなく,古田らや栗原らの研究に見られるような話題セグメントがあげられる.様々なメタデータを組み合わせた会議コンテンツを作成することで,検索や閲覧,要約といった応用を実現することができる.
会議に関するメタデータを取得する方法には,ミーティングブラウザのように自動認識技術を用いる方法と,会話量子化器のように人間がデバイスやツールを用いて入力する方法がある.前者の方法は,メタデータの取得時における人間の労力は非常に少ないが,必要な情報を計算機ですべて自動的に記録することは現状では困難である.たとえば,発言テキストの取得に音声認識技術を利用する場合,雑音や部屋の残響が存在する実環境において運用に耐えうる十分な精度を持っているとはいい難い.また,それ以上に困難な問題が計算機による意味関係の抽出である.そのため本研究では,これらのメタデータを人間が入力する方法を採用している.
Geyer らは,TeamSpaceと呼ばれる,チームにおける協調作業を支援するためのシステムを開発している.TeamSpace では,協調作業において重要な要素(議題やアクション・アイテム)の,会議中における作成・編集時間を用いて,会議風景を記録した動画像のインデキシングを行っている.しかし,我々はアクション・アイテムのような結果が生まれるまでに行われる発言そのものを記録する必要があると考えている.たとえば,その場では技術的な問題などによって保留にされたアイディアが,かなり後になってから再び話題にのぼることがある.しかし,作成されたアクション・アイテムには,そのアイディアに関する記録はないため,参照することができない.このように,長期間にわたる会議コンテンツの利用を実現するためには,議論に関する詳細なメタデータを取得する必要がある.
そして,より詳細なメタデータを効率的に取得するためには,メタデータの取得方法を考察する必要がある.例として会議が終わった後に会議コンテンツを閲覧する場面を考えてみよう.ユーザはまず,閲覧したい内容に関する議論が行われている会議コンテンツを検索するだろう.キーワード検索を行うためには,発言内容を書き起こしたテキストが必要となる.しかし,発言内容の書き起こしは非常に負担のかかる作業であるうえ,ビデオを閲覧すれば詳細な内容を確認できるため,発言内容を一言一句書き起こす必要はなく,書記が会議中にできる範囲内で行うのが妥当だと考えられる.つまり,メタデータによって得られる利益とのバランスを考慮しながら人間の作業量を最小限にすることが必要である.また,発言単位でビデオを閲覧するためには,発言の開始・終了時間が必要となるが,会議後にセグメンテーション作業を行うことは望ましくない.なぜなら,会議後に行われる入力作業は,その後の知識活動に密接に関わる会議コンテンツの一部分を,閲覧行為を通じて整理・抽出することに注力されるべきであり,明確な目標が見えにくい独立した入力作業は,そのモチベーションを維持することが著しく困難であるからである.つまり,会議中にできるだけ自然に取得できる方法を考える必要がある.そのため,ディスカッションマイニングでは,会議中の作業を参加者全員が協力して集中的に行う仕組みを実現することによって,会議後に行う作業量を最小限にすることを目指している.
2.2 会議コンテンツの作成
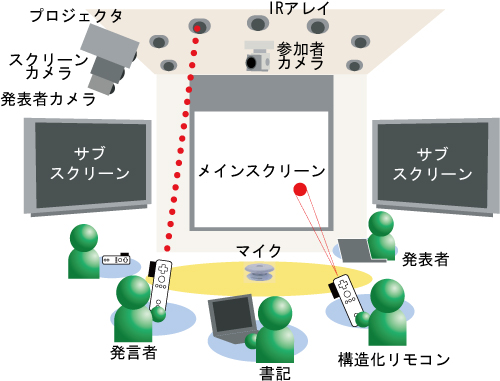
図1: ディスカッションルーム
我々は前述した立場に基づいて,ディスカッションレコーダと呼ばれる会議コンテンツの作成を行うシステムを開発した.ディスカッションレコーダでは,図のようなディスカッションルームに設置された複数のカメラとマイクロフォン,Web ブラウザベースの発表者・書記用ツールを用いることで議論内容を記録することができる.また,ディスカッションルーム中央には発表資料やデモの様子を映し出すメインスクリーンが設置されており,その両側には現在発言している参加者の情報やカメラ映像を表示するためのサブスクリーンがある.

図2: 構造化リモコン
発表者は専用ツールを用いてスライドファイルのアップロードやスライドショーの操作を行うことができ,スライドショーの切替えタイミングは自動的にサーバに伝達・記録される.また参加者は,構造化リモコンと呼ばれるデバイスを用いる(図).発言開始時に構造化リモコンを上げることによって,発言者IDや発言者の座席位置に加え,発言の開始時間や発言タイプが記録される.また,発言の終了時間は構造化リモコンのボタンによって入力することができる.発言の開始・終了時間を取得することにより,発言ごとに映像・音声情報をセグメンテーションすることができる.また,構造化リモコンのボタンによって,発言に対する賛同を表明したり,自身にとって重要な意味を持つ発言に対してマーキングを付与することができる.
ディスカッションレコーダで取得する発言セグメントには,「導入」と「継続」の2 つのタイプがある.新しい話題の起点として発言する際には「導入」を,直前までの発言の内容を受けて発言をする際には「継続」を,発言開始時の構造化リモコンの向きによって入力する.ディスカッションレコーダは,継続発言と派生元の発言との間にリンク情報を生成し,記録する.これを繰り返し行うことによって,図のように導入発言に継続発言が連なる形式の発言集合が複数生成される.本研究ではこの発言集合を議論セグメントと呼ぶ.1 つの会議コンテンツ内に複数の議論セグメントが作成されることによって,会議で行われた議論を話題単位で閲覧することが可能になる.
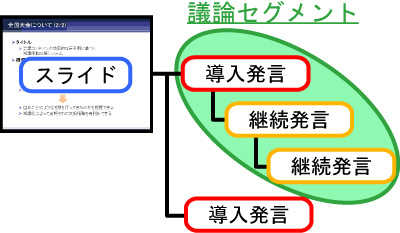
図3: 議論セグメント
ディスカッションレコーダでは,クロストークがないように参加者の発言の順番を制御するための仕組みとして,発言予約機能を備えている.誰かの発言中に構造化リモコンを上げた場合は発言予約リストに加えられ,直前の発言が終了すると自動的に発言権が移る.複数の発言予約が存在する場合,発言の順番は以下のルールに基づき変動する.
-
発表者の入力した予約は他の予約より優先される.
-
導入と継続の予約が両方存在するときは,現在の話題を継続して行えるように継続の予約が優先される.
この発言予約機能は,発言の順番を制御するだけでなく,より人間の意図を反映した議論構造を作成するためにも利用される.発言予約機能を利用せずに,発言タイプ(「導入」「継続」)だけを利用した場合,作成される議論構造は導入発言を起点とするリスト構造となる.しかし,1つの発言の内容に対して複数人が様々な視点から意見を述べた場合の議論構造は,単純なリスト構造ではなくツリー構造であると考えられる.そのため,誰かが発言を行っている最中に「継続」の予約が追加された場合,その継続発言と現在行われている発言との間にリンク情報を生成する.つまり,発言中に複数の「継続」の予約が追加された場合,1つの発言に複数の継続発言が連なるツリー構造が自動的に作成される.
書記は図のようなWeb ブラウザベースの専用ツールを用いて発言内容の記録を行う.このツールは構造化リモコンと連動しており,参加者(発言者)の発言に関する情報が随時追加されていく.参加者による構造化リモコンの上げ下げが行われると,書記ツールに発言者と発言タイプの付与されたノードが自動生成される.書記はこのノードを選択することで会議コンテンツの発言内容を効率的に記録することができる.
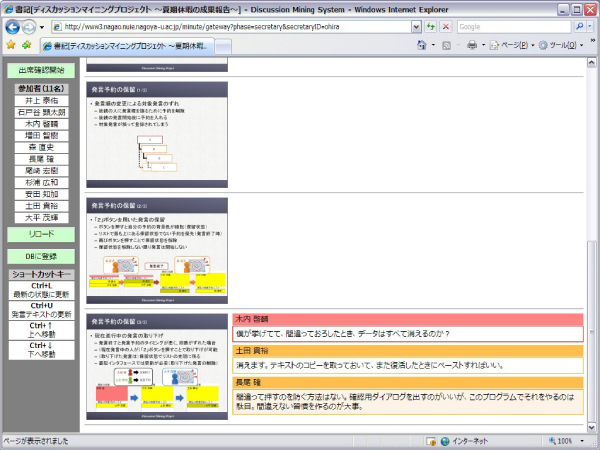
図4: 書記用インタフェース
2.3 運用実績とユーザビリティに関する考察
我々の研究室では,2003年度から約6年間にわたり,ディスカッションレコーダを運用してきた.作成された会議コンテンツは年間約100件(録画された映像・音声は約150時間)にのぼる.継続的な運用の中で,ディスカッションレコーダを利用したために,議論にかかる時間が極端に長引いてしまうことや,書記以外の特定の参加者に特別な負担がかかるようなことは,経験的になかったため,今後も運用を継続していくことは可能だと考えている.
ディスカッションレコーダでは,会議に関するメタデータの取得をシステム化しやすくするため,構造化リモコンを用いた発言のタイムコードの入力や発言予約機能によって,参加者同士の発言のクロストークを排除する方法を採用している.この方法は議論の進行方法に対して制約を加えるものであり,自然な議論を妨げてしまう可能性がある.たとえば,ブレインストーミング形式の会議では,参加者同士の発言のクロストークを排除することによって,アイディアの創出を妨げてしまう可能性がある.我々の研究室では,ゼミを対象として会議コンテンツの作成を行っているため,参加者に対して「発表者である学生の研究活動にとって少しでも有益だと考える発言は記録し,雑談のように関係のない発言は記録しない」という基準を設けることで,できるだけ自然な議論が行えるようにしている.また,ちょっとしたあいづちや同意発言を行いたい場合は,あえて発言を行わず,構造化リモコンのボタンを利用して発言に対する賛同を表明するなど,より簡易な操作を行うことができる.
また,発言を開始する際には手を挙げるように構造化リモコンを上げるなど,参加者ができるだけ自然にシステムを利用できるようにしている.しかし,システムの不具合や参加者のデバイス利用の不慣れなどによって,円滑に発言を開始できずに議論が一時的に停滞してしまうこともある.ただし,会議後に会議コンテンツを閲覧する際には,発言の開始・終了時間が記録されているため,このような停滞している時間をスキップして閲覧することができる点がディスカッションマイニングの特長である.
3 取得したメタデータの評価と考察
ディスカッションレコーダでは半自動的に会議コンテンツの作成を行う.しかし,人間が情報の入力を行うため,情報の欠落や誤った情報の入力などのヒューマンエラーが混在する可能性がある.また,議論をできるだけ妨げないような入力方法を採用しているため,取得されたメタデータにユーザの意図が一部しか反映されていない可能性もある.ディスカッションレコーダで取得しているメタデータの中でも,構造化リモコンの上げ下げによって取得される議論構造,および書記によって入力される発言テキストは,特に人間による解釈に大きく影響されるものである.そこで本研究では,ディスカッションレコーダで獲得した議論構造および発言テキストの妥当性の評価を行った.
3.1 議論構造の妥当性の評価
ディスカッションレコーダでは,発言開始時に取得される発言タイプ(「導入」・「継続」)や発言予約機能によって議論構造を生成している.しかし,自分がこれから行う発言のタイプが導入なのか継続なのかを迷ったり,予約を入れるタイミングを逸して意図したリンク情報が付与されないなど,生成される議論構造には誤りが混在する,もしくはユーザの意図が一部しか反映されていない可能性があるため,議論構造の妥当性の評価を行った.
3.1.1 評価に用いたデータセットと評価方法
2007年度以降に作成された会議コンテンツにおける議論セグメントの中から,発言数が多い上位18個の議論セグメントを対象とした.なお,18個の議論セグメントに含まれる全発言数は199発言(うち継続発言は181発言)であり,議論セグメントごとの発言数の平均は11.1発言,議論セグメント内の発言者数の平均は4.6名であった.そして以下の項目に関して正解データを作成し,比較することで評価を行った.
3.1.1.1 新たな話題を提示している継続発言
経験的な問題として,議論が長くなるにつれ話題が次第にずれていくということがしばしば発生する.そのため,発言数の多い議論セグメントに含まれる個々の発言内容を吟味していくと,その議論セグメントの親である導入発言の内容や意図とは関連の弱い継続発言が含まれると考えられる.そのため,議論セグメントの中で新たな話題を提示している継続発言の数を調べることによって,継続発言の妥当性を検証する.
3.1.1.2 親発言が適切でない継続発言
発言予約機能は,対象となる発言が行われている時点で発言予約を入れることによって発言間のリンク情報を付与する.そのため,対象となる発言が終了した後に発言予約を入れても,すでに別の発言が行われていた場合,正しいリンク情報が付与されない可能性がある.そのため,親発言が適切でない継続発言の数によって発言予約機能の妥当性を評価する.
3.1.1.3 複数リンクを持つ継続発言
現在の発言予約機能では,親発言となる発言は1 つに限定されているが,これまで行われた議論をまとめるような発言を行う際には1発言だけでなく,複数の発言を参照することが考えられる.そのため,複数リンクを持つ継続発言の数を調べることで,ユーザの意図が正しく反映されているかどうかを調べる.
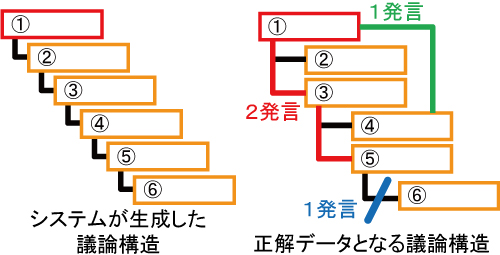
図5: システムが生成した議論構造と正解データとの比較
図はシステムが生成した議論構造と正解データとの比較の例である.この例において,(1)に該当する発言は?であり,(2)に該当する発言は?と?の2発言,(3)に該当する発言は?と?との間にリンクを持つ?の1発言となる.
正解データは以下の手順によって作成した.まず,議論セグメントの親となる導入発言の内容や意図がその後の継続発言に正しく反映されているかを確認するため,対象の議論セグメントの導入発言者に自身の発言の内容・意図と関連のない継続発言を選択してもらった.次に,同研究室の大学生・大学院生3名に導入発言者の意図をふまえたうえで,ビデオを視聴しながら(1)から(3)の項目について正解データを作成してもらった.最後に,個々に作成された議論構造を照合しながら合議によって最終的な正解データとした.
3.1.2 評価結果と考察
ディスカッションレコーダによって生成された議論構造と正解データとの比較を行った結果を表に示す.
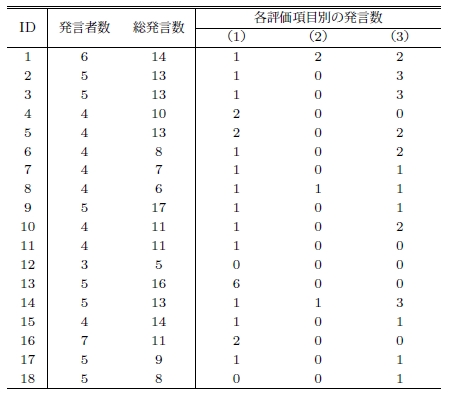
図6: システムが生成した議論構造と正解データとの比較結果
3.1.2.4 新たな話題を提示している継続発言の傾向
表から,ほぼすべての議論セグメントに新たな話題を提示している継続発言が存在する,つまり複数の話題が存在することが分かる.新たな話題を提示する継続発言として最も多かったのが,直前までの議論から派生した話題を提示する発言である.たとえば,直前までは「意味単位を分割できるか」という議論を行っていたが,「逆に意味単位を統合できるか」と別の視点から話題を切り出す発言がこれに該当する.「意味単位」という大きな視点からとらえると一貫した議論を行っているが,より詳細な視点からとらえると別の話題について議論を行っている,という特徴がある.
現在使用している発言タイプだけでは柔軟な視点で議論を分割することはできない.1つの議論セグメントが長いほど閲覧に必要な時間が長くなるため,効率的な議論内容の閲覧を実現するためには,より細かいセグメント情報を,発言タイプと別の手法と組み合わせて取得することが望ましい.
そこで我々は,議論セグメントの親である導入発言と,それに続く継続発言の内容・意図の関連性に着目した.もし導入発言者が,自分の発言の内容・意図と関連のない継続発言が行われたという判断ができ,その情報を取得することができれば,より細かいセグメント情報を取得することができると考えられる.そこで,新たな話題を提示する継続発言が行われる前後で,導入発言と関連の弱い発言が含まれる割合を比較した.その結果,新たな話題が提示される前では平均27.9%(標準偏差は34.8%)存在し,新たな話題が提示された後では平均81.8%(標準偏差31.0%)存在することが分かった.話題が変化する前に比べて変化した後の割合のほうが大きいことをふまえると,導入発言者が自身の発言と関連が弱いと判断した発言が集中している箇所は別の話題について議論していると推測される.導入発言者が自身の発言と関連があるのかどうかを判断することによって,自動的にセグメント情報を抽出することは困難かもしれないが,人間が後付けでセグメント情報を入力する際の手がかりとして十分な情報を得ることができるだろう.
3.1.2.5 親発言が適切でない継続発言の傾向
表から,親発言が適切でない継続発言はすべての継続発言(181発言)内の2.2%に相当する4発言であることが分かる.このことから発言予約機能によって取得した発言のリンク情報は妥当であると考えることができる.また,該当する発言を詳細に調べると,発言予約を入力するタイミングが遅くなったことが原因であることが分かった.発言予約機能は,発言予約を入れた時点で行われていた発言に対してリンク情報を付与するものであるが,発言予約を入れた時点で発言が行われていない場合は直前の発言に対してリンク情報を付与するようになっている(導入発言はこれに該当しない).そのため,直前の発言よりも前に行われた発言に対して,リンク情報を付与することができない.この問題点の解決法としては,発言者が発言を行う際に対象となる発言を指定する手法が考えられるが,詳細な方法については4.1節において述べる.
3.1.2.6 複数リンクを持つ継続発言の傾向
表から分かるように複数のリンクを持つ継続発言は数多く存在する.個々の発言内容を見ていくと「錯綜してきたので整理するけど」「○○君も言っていたけど」といったように,それまでの発言や議論を受けた意見やまとめを述べる発言が多かった.なお,複数のリンクを持つ継続発言が存在しない議論セグメントは質疑応答の繰返しやシステムに対する要望を出し合うものが多かった.このことから「リンクの多い発言ほどその議論セグメントにおいて重要」「複数リンクを持つ継続発言が多いほどその議論セグメントは活発」といったように発言や議論セグメントの重要度や活性度を求めるうえで,複数のリンク情報を記録することは有効だと考えられる.
現状の発言タイプや発言予約機能だけでは,複数のリンク情報を取得することはできないが,上述の親発言の修正と同様にサブスクリーンと構造化リモコンを用いて参照したい発言を追加することで対処することができるだろう.また,会議中に取得する手法だけでなく,会議後に入力する手法も考えられる.たとえば,重要だと思われる発言を複数引用して,自分の意見やアイディアを記述する仕組みを実現することで,同時に引用されている発言間にリンク情報を付与することができるだろう.
3.2 発言テキストの情報量に関する評価
会議コンテンツの閲覧や検索,要約などを実現するうえで重要な情報となるのが発言テキストである.発言テキストを取得する方法として音声認識があげられるが,実環境における認識精度は高いとはいえず,仮に完全な書き起こしを作成することができたとしても,文法的に正しくない発言がそのまま書き起こされてしまうといった問題点がある.
ディスカッションレコーダでは上記の理由により,書記が発言を要約しながら入力するという方法を採用しているが,すべての内容を入力することが困難であるため,取得される発言テキストの情報量は減損していると考えられる.また,発言内容を忠実に書き起こそうとする書記もいれば,必要だと思われる内容だけ入力し,冗長と判断した内容は入力しない書記もいるように,入力されるテキストの量や内容は書記に依存すると考えられる.そこで書記が入力した発言テキストに関して次の項目について評価を行った.
-
書記による記述量の個人差
-
議論内容と記述量の関係
3.2.1 評価に用いたデータセットと評価方法
書記が入力した発言テキスト(以下,書記テキスト)と,ビデオを閲覧しながら書き起こした発言テキスト(以下,書き起こしテキスト)に含まれるキーワードの割合の比較を行った.
評価に用いるデータセットは,書記による記述量の個人差を考慮するため,筆者らの所属する研究室の大学生・大学院生6名が2007年度以降に書記を行った会議コンテンツの集合から12個を選出した.そのためにまず,6名の書記を1発言あたりの平均文字数によって3つのグループ(各2名ずつ)に分類した.ここで,各書記グループを平均文字数の多い順番にグループA,グループB,グループCと呼ぶことにする.そして,それぞれの書記の平均文字数に近い文字数を持つ会議コンテンツを2個ずつ(各書記グループにつき計4個)を選出した.ちなみにすべての会議コンテンツに含まれる発言の総数は661発言(1会議コンテンツあたり55.1発言)であり,議論セグメントの総数は137個(1会議コンテンツあたり11.4個)であった.
評価を行うために,まず正解データとなる書き起こしテキストの作成を行った.なお,この後の評価においてノイズになるため,間投詞やいい間違いの書き起こしは行わなかった.次に発言テキストにおけるキーワードの割合を求めるため,書記テキスト,書き起こしテキストのそれぞれに対して形態素解析ライブラリSenを用いて形態素解析を行った.最後に形態素解析によって得られたキーワード候補の中からキーワードとなるものを選択した.キーワードの選択は,「記述されている順番に見るだけでその発言のすべての内容が把握できる」という定義に基づいて行った.なお,発言テキストの書き起こしやキーワードの選択は,前述の6名の書記とは異なる大学生・大学院生3名に行ってもらった.この3名は事前に書き起こしやキーワード選択に関する注意事項を周知されているため,作成された書き起こしテキストや選択されたキーワードにはばらつきはないと見なす.
3.2.2 評価結果と考察
選出された会議コンテンツにおける発言テキストの総文字数は,書記テキストで41,946文字(1会議コンテンツあたり3,495文字),書き起こしテキストで188,816文字(1会議コンテンツあたり15,734 文字)であった.また,形態素解析によって得られたすべての形態素数(重複を含む)は書記テキストで23,950個(1会議コンテンツあたり1,995個),書き起こしテキストで105,843個(1会議コンテンツあたり8,820個)であった.文字数や形態素数の観点から見ると,すべての発言内容を書き起こすために必要な記述量は,リアルタイムに書記が入力する記述量の約4 倍であることが分かった.このことから発言内容をすべて書き起こすためには,かなりの時間を必要とするため,会議中に行うことは困難であることが分かる.
書記テキスト,書き起こしテキストにおける自立語,キーワード,そして書記テキスト,書き起こしテキストのどちらにも出現するキーワード(以下,共通キーワード)の数の集計結果を表に示す.左から書記のグループ,対象の会議コンテンツのID,書記テキストにおける1 発言あたりの自立語の数(?),キーワードの数(?),書き起こしテキストにおける1 発言あたりの自立語の数(?),キーワードの数(?),共通キーワードの数(?),それぞれの値を用いた割合を表している(表中の丸番号は図と対応).また,表中の?から?までの値は発言数で正規化している.
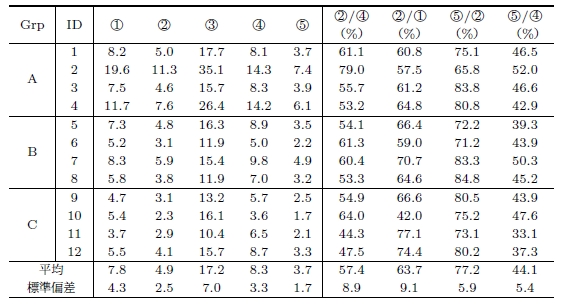
図7: 書記テキスト,書き起こしテキストにおける自立語,キーワード,共通キーワードの数
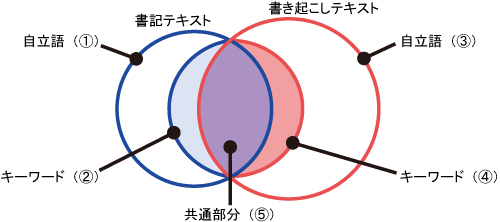
図8: 書記テキスト,書き起こしテキストにおける自立語,キーワード,共通キーワードの包含関係
なお,説明のため,書記テキスト内のキーワード数と書き起こしテキスト内のキーワード数の比率を示す?/?を,書記によってキーワードがどれだけ書き起こされたかを測る指標ととらえ,書き起こし率と呼ぶことにする.また,書き起こしテキスト内のキーワードに対する共通キーワードの含有率を示す?/?を,書記がいかに発言内容を忠実に記述したかを測る指標ととらえ再現率と呼ぶことにする.
再現率の平均が44.1%であることから,発言内容のキーワードの半分以上が入力時に欠落していることが分かる.今回の実験では,キーワードを選択する基準を「記述されている順番に見るだけでその発言のすべての内容が把握できる」としたが,たとえば発表者が会議コンテンツを閲覧する際には,自身の研究を進めるうえで必要な発言の,必要な部分さえ記述されていれば十分だと考えられる.そのため実際に,発表者に対して自分が発表した会議コンテンツの書き起こしテキストの中で必要な発言,さらにはその中でも最低限記述されていてほしい内容に対してチェックをしてもらい,書記テキストと比較したところ,書記テキストだけで十分な内容が記述されていたことが確認された.これに対して,会議コンテンツや議論セグメント,発言の検索にはより多くのキーワードが含まれていることが望ましいだろう.このように利用目的によってキーワードの重要度は異なると考えられるため,書記の入力時に欠落した情報の中に,重要な情報がどれだけ含まれていたかを評価するためには,利用目的に応じてどのようなキーワードが必要であるかをふまえたうえで個別に検討する必要がある.
また,我々は会議後にブラウザ上で会議コンテンツを閲覧するためのインタフェースの開発も行っており,ユーザが閲覧中に発言テキストを編集する仕組みを実現することによって,再現率そのものを上げることができると考えている.
3.2.2.1 書記による記述量の個人差の検証
書記グループごとに書き起こし率(?/?),再現率(?/?),書記テキストにおける共通キーワードの割合(?/?),書記テキストにおけるキーワードの割合(?/?)の平均,標準偏差を比較した結果を図に示す.
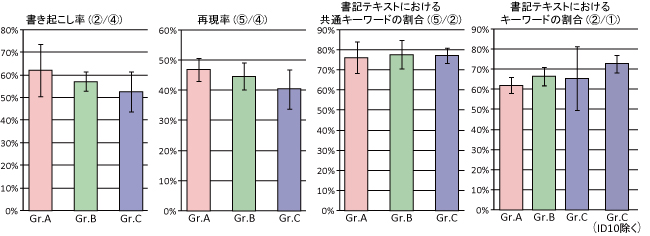
図9: 書記による発言テキストの記述量の個人差
1発言あたりの平均文字数によってグループ分けを行ったため,書き起こし率もグループごとに差が存在することが分かる.また,再現率のグラフから,書き起こし率が高くなるにつれて発言中のキーワードがより多く書き起こされていることが分かる.その一方で,書記テキストにおける共通キーワードの割合を示すグラフを見ると,それほど個人差は見られないことが分かる.つまり,書記によって入力されるテキストの量とは関係なく,書記テキストにおけるキーワードの割合はほぼ一定であると推定される.このことから入力されるテキストの量は書記によって個人差があるが,その質自体に個人差はほとんど存在しないことが推測できる.また,書記テキストにおけるキーワードの割合のグラフ(?/?)では,グループCの標準偏差が大きいが,これはID10の書き起こしテキストにおけるキーワードの割合(?/?)が他の会議コンテンツに比べて非常に小さい,つまり書記が入力するべき発言内容に含まれるキーワードそのものの数が少ないため,結果として書記テキストに含まれるキーワードの割合も小さくなったと考えられる.このグラフの一番右側の値はID10 を除いた書記テキストにおけるキーワードの割合を表したものである.このグラフから平均文字数が少ない書記は多い書記に比べ,より簡潔に書記テキストを入力している可能性があることが分かる.つまり,平均文字数の多い書記は発言者の発言内容を逐一詳細に記述しようとしているのに対し,平均文字数の少ない書記は発言内容を要約しながら入力を行っていると考えられる.
3.2.2.2 議論内容と書記テキストの記述量の関係
1つの発表の中には質疑応答だけの議論やテーマに関する意見の出し合いのように様々なタイプの議論が存在する.そして,質疑応答は意味が理解しやすく書記テキストが書きやすい,概念的な議論は理解しにくく書記テキストが記述しにくいといったように議論のタイプと書記テキストの記述量には関係があると考えられる.そのため,各会議コンテンツ内の議論セグメントに対して書き起こし率と再現率を求め,それぞれの値Xi に対して以下の式によって基準値SSiを算出し,グラフにプロットした(例を図に示す).なお,E[X]はXの平均,SD[X]は標準偏差を表している.
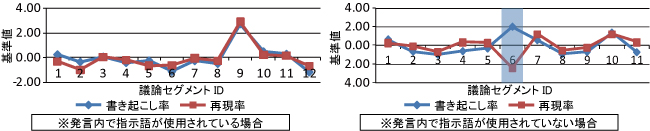
図10: 書き起こし率(?/?)と再現率(?/?)の相関関係
ほとんどの会議コンテンツでは,図の左側のように書き起こし率と再現率はほぼ同じような曲線を描いており,書き起こし率と再現率には相関関係があると考えられる.しかし,右側のグラフにおけるID6の議論セグメントのように書き起こし率と再現率が大きく異なる議論セグメントが存在することが分かった.このような議論セグメントを詳細に調べてみたところ,スライド内の図について言及している議論であることが分かった.このような議論では図を指し示しながら発言を行っているため,指示語を多用する傾向があった.そのため,書記が指示語の内容を補う単語を入力しているが,発言内容には直接含まれているわけではないため,再現率が低くなることが分かった.
3.2.2.3 発言に含まれる指示語の傾向
上記の結果のように発言内容に指示語が含まれている場合,その箇所だけを閲覧しても内容が把握できないうえに,発言におけるキーワードとして利用することが困難なため,何らかの処置が必要になる.今回対象とした会議コンテンツ内の書き起こしテキストには指示語が平均で28.0%含まれていることが分かった.発言に含まれる指示語の傾向は大きく分けて,(1)それまでの発言や議論を指し示すもの,(2)スライド中のテキストを指し示すもの,(3)スライド中の図形を指し示すもの,の3つとなることが分かった.(1)は,「その問題は…」といったようにそれまでの発言や議論を指し示す指示語であり,指示対象である発言は発言予約機能によってリンク付けすることが可能なため,リンク情報を用いた閲覧によって指示語の内容を確認することができる.また,(2)のようにスライド中のテキストを指し示す場合は,レーザポインタなどを用いてスライドを指示することが多い.ディスカッションレコーダでは構造化リモコンを用いたスライドの指示やポインタの座標情報の取得,指示されたスライド中のテキストを抽出する手法を実現しており,スライド中のテキストが指示された際には,書記インタフェース上で指示されたテキストを補完する機能を追加することで,(2)のような指示語の内容の入力を促すことができると考えられる.そして最後に,(3)のようなフローチャートなどスライド中の図形を示す指示語は,テキスト情報として記録することが困難な情報である.そのため,構造化リモコンによって取得されたポインタ情報をスライドのサムネイル上で再生する仕組みを実現することによって発言内容の理解を促進することができるだろう.
4 議論構造の可視化
前章では,ディスカッションレコーダによって取得されるメタデータの妥当性について検証を行い,発言間のリンク情報を用いた議論構造が妥当であることを確認することができた.そこで本研究では,会議で行われる議論を記録するだけでなく,取得した議論構造を用いて,議論そのものを活性化させるための枠組みについて検討を行った.では,そもそも議論を活性化するということはどういうことだろうか.本研究において議論の活性化とは様々な理由で停滞している議論を以下のように変えることであると考える.
-
参加者が議論の発散・収束を適切に行っている.
-
参加者全員が偏りなく,積極的に発言を行っている.
まず,1番目の項目については,システムが参加者に対して現在行われている議論の内容や進行状況を提示することが有効である.本稿では,ディスカッションレコーダで取得した議論構造に関する情報を効果的に可視化する仕組みを提案する.議論構造の可視化には以下のようなメリットがある.1つは,現在行われている議論内容を簡単に把握することができ,発言者が発言内容を整理することができる点である.もう1つは,誰が過去のどの発言を受けて発言しようとしているのかを理解することによって,その人に発言権を譲るなど,議論を効率的に進められるようなファシリテーションを参加者に促すことができる点である.また,重要な話題であるにもかかわらず発言数が少なければ議論をより深めようとしたり,すでに多くの発言が行われているときは論点を絞ろうとするなどの効果も期待できる.
2番目の項目は,会議の参加者全員が議論に参加し発言を行いやすくすることで,結果として議論の活性化につながると考えた.議論が停滞する原因の1つは,参加者全員が発表に関して同じ知識量を持ち合わせていないことに起因すると考えられる.発表に関する背景情報や過去の研究内容,あるいは過去に行われた議論内容といった知識を十分に持つ人は,発表内容を容易に理解できるため,議論参加へのモチベーションも高いと予測される.しかし,一方で発表に関して十分な知識を持ち合わせていない人は,説明されない研究の背景やその他の知識に関して差が生じてしまう.これにより発表内容を十分に理解できず,発言を行いにくい状況が発生すると予測される.図は,筆者らの研究室の学生の所属年数と1年間に行われたゼミ中における発言数との関係を示したグラフである.所属年数に比例して知識が増していくと考えるならば,知識の少ない人ほど発言数が少ないという傾向があることが分かる.また,図は,所属年数と1年間に行われたゼミにおいて他の参加者に賛同された発言(賛成発言),もしくは重要であると判断された発言(マーキング発言)の数の関係を示したグラフである.このグラフからも図と同様の傾向があることが分かる.これより,システムが発表内容を補足する情報を提示することによって,発表に関する知識が少ない人が議論に参加しやすい状況を作り出すことができると考えられる.
議論構造の可視化に関する研究はこれまでにも行われている.gIBISでは,参加者が発言を構造化しながら議論を行うことで,議論内容を整理し,内容把握や検索を支援している.しかしgIBIS は,議論構造を明確に決めることができず,本来行うべき議論から逸脱し,議論構造に関する議論を行ってしまうという問題点がある.また,松村らは,会議コンテンツ内の字面に基づいた表層的な解析により話題セグメントを同定し,セグメント間の関連を調べることで,議論構造を可視化する手法を提案している.この手法の問題点として,議論の論点を直感的にとらえられる適度な話題セグメントの分解能を決定できない点があげられる.
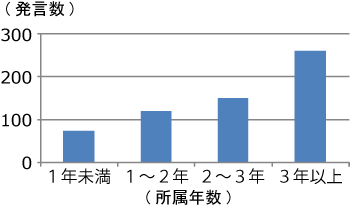
図11: 所属年数による発言数の変化
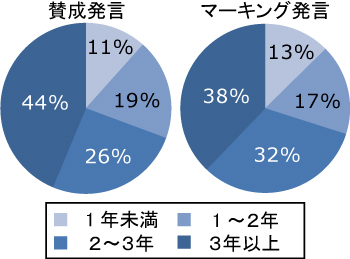
図12: 所属年数による賛成発言およびマーキング発言の数の変化
本研究では,ディスカッションレコーダによって取得した議論構造の可視化の応用として,現在行われている議論の内容をリアルタイムに可視化するためのツールであるディスカッションビジュアライザと,過去に行われた議論を可視化し,検索を行うためのツールであるディスカッションリマインダを提案する.
4.1 ディスカッションビジュアライザ
ディスカッションビジュアライザは,図のようなインタフェースであり,サブスクリーンに提示される.ディスカッションビジュアライザは,(1)発表情報ビュー,(2)スライドリスト,(3)議論セグメントビュー,(4)議論セグメントリストから構成されている.発表情報ビューでは,発言者を撮影しているカメラのプレビュー,参加者のリスト,発表の経過時間が表示される.スライドリストは,会議中に表示されたスライドページの一覧が表示されており,発言者が構造化リモコンで任意のスライドページを選択することで,メインスクリーンに表示されるスライドページを変更することができる.議論セグメントビューでは,現在行われている発言が含まれる議論セグメントに関する情報が表示される.このビューの上部には,現在行っている議論のきっかけとなる導入発言や,その発言が継続発言であれば親発言のテキストが表示されており,下部には議論セグメントの構造が表示される.議論セグメントリストは,この会議においてどのような議論が行われたかを確認するためのビューである.中央付近には議論セグメント内のサブトピックを表すノードが鎖状に表示されており,その右側には各サブトピックの内容を表現するキーワードが表示される.構造化リモコンによって入力された発言に対する賛成の数の多さによってノードの色が変化し,マーキングされた発言を含むノードの右側にはその旨を示すアイコンが表示され,重要な議論がどの時点で行われたのかを容易に確認することが可能である.スライドリストや議論セグメントリスト,および議論セグメントビューは相互に関連しており,議論セグメントビューで表示されている議論や,その議論に関連するスライドページが議論セグメントリストやスライドリストで強調表示されるようになっている.
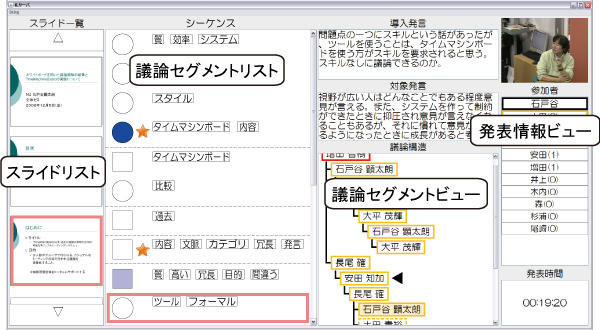
図13: ディスカッションビジュアライザ
前章の議論構造の妥当性に関する評価実験の結果から分かるように,議論セグメントの中には,導入発言で提起した話題から派生した内容の継続発言が含まれることがある(3.1.2 項の(1)を参照).つまり,議論セグメントにおいて導入発言をルートノードとして,複数のサブトピックが派生していると考えることができる.
そのため,ディスカッションビジュアライザでは,このような1 つの議論セグメントに含まれる複数のサブトピックを,図に示す手順によってシーケンスと呼ばれる単位の集合S として抽出している.なお,B は議論セグメント内の導入発言もしくは複数の子発言を持つ継続発言(ブランチと呼ぶ)の集合である.また,関数children(s) は発言s に含まれる子発言の集合(子発言が存在しないときはφ)を取得する関数であり,関数first child(s)は発言s に含まれる子発言の中で最も開始時間の早い発言(子発言が存在しないときはnull)を取得する関数である.
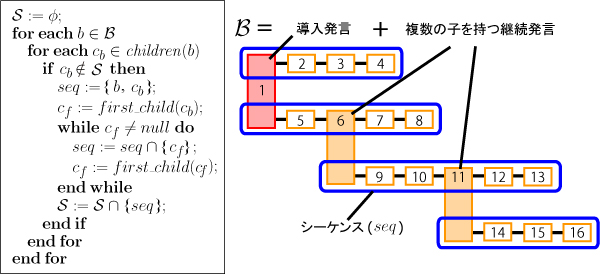
図14: 議論セグメント内のシーケンス
前章の実験結果では,親発言が適切でない継続発言が存在することが分かっている(3.1.2 項の(2)を参照).そこでディスカッションビジュアライザは,議論構造を可視化するだけでなく,議論構造を編集するための機能を備えている.発言を行っている際に,構造化リモコンを操作することにより,議論セグメントビューの,議論構造が表示される箇所にカーソル(図内の黒い三角形)が表示される.そして,カーソルを正しい親発言に移動させ,選択することによってリンク情報を修正することができる.
4.2 ディスカッションリマインダ
ディスカッションリマインダを実現するにあたり,我々は以下の2点を考慮した.1つは議論内容の正確な把握であり,もう1 つは現在の議論を妨げないような高速な議論の検索・閲覧である.曖昧で不十分な情報の共有は,誤解を生み議論の混乱につながる要因になるため,参加者が議論内容を正確に把握できる情報提示が必要である.そのため,ディスカッションリマインダでは,過去の議論の様子を記録したビデオの閲覧を行う.しかし,参加者全員が過去の議論を検索・閲覧するためには,現在行っている議論を中断する必要があるため,作業にかかる時間は短くなければならない.そのため,ビデオの中で必要とする箇所をピンポイントに探し出せる手段が必要となる.そこでディスカッションリマインダでは,クエリにマッチする会議コンテンツ,その会議中に表示されていたスライド,そしてスライドから生まれた発言というように段階的に閲覧したい情報を絞り込むインタフェースを提供する.また複数の参加者が協調的に議論の探索を行う仕組みを提供することによって,より効率的な回顧を可能にしている.
過去の議論の存在を指摘した参加者は書記にクエリを伝え,書記は書記インタフェース上でクエリの入力を行う.クエリには,発表者名,発表日時,キーワードなどディスカッションレコーダによって取得された様々なメタデータを指定することができる.入力されたクエリに基づいて行われた検索の結果は,図のようなインタフェースによってメインスクリーン上に表示され,参加者は構造化リモコンを用いて情報の絞り込みやビデオの再生を行う.
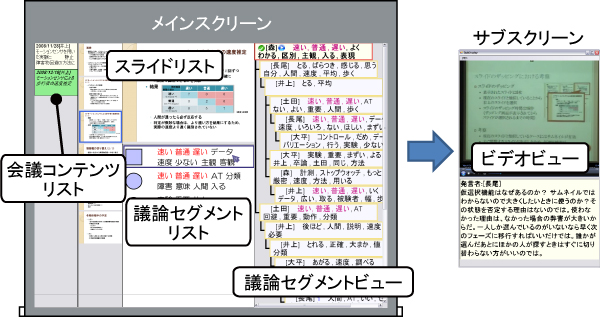
図15: ディスカッションリマインダ
このインタフェースは,(1)会議コンテンツリスト,(2)スライドリスト,(3)議論セグメントリスト,(4)議論セグメントビューの4 つで構成されている.会議コンテンツリストでは,クエリにマッチした議論を含む会議コンテンツのタイトル一覧が表示される.構造化リモコンによってタイトルを選択すると,選択された会議コンテンツに含まれるスライドページのサムネイル一覧がスライドリストに表示される.スライドリストでは,サイズの大きいサムネイルのプレビューを行うこともできる.そして,ディスカッションビジュアライザと同様に,スライドリストや議論セグメントリスト,議論セグメントビューは相互に関連しており,左側のコンポーネントで選択されたオブジェクトに同期して,右側のコンポーネントの表示が動的に変化する.そして参加者は,これらの情報を確認しながら,構造化リモコンによって閲覧したい発言を議論セグメントビュー上で選択する.発言を選択することで,サブスクリーン上に表示されているビデオビューで対応する時間からビデオを閲覧することができる.
ディスカッションリマインダでは,複数の参加者が協調的に議論の探索を行うことができる.具体的には,ビデオビューで再生をしている最中でも発言テキストやスライドページのプレビューを行うことができる.ある参加者が探しているものと異なる発言を再生したとしても,別の参加者がプレビューを行うことによってより適切な発言の存在を指摘することができる.また,必要に応じて対象とするスライドページを変更することもできる.
しかし,複数の参加者が競合する操作を同時に行うことによって混乱が生じる可能性がある.たとえば,ビデオビューで再生を行っている最中に,別の参加者が別の発言の再生を開始すると,それまでの再生は中断されてしまう.そのため,ディスカッションリマインダではビデオビュー操作をロックする機能が用意されている.ビデオビューで再生を始めると,再生を開始した参加者が停止させるか,その発言が終了するかまで他の参加者は発言テキストやスライドページサムネイルのプレビュー以外の操作を行うことができなくなる.これにより,複数の参加者が競合することなく,効率的に発言内容を確認することができる.
そして,過去の発言を参照しながら新たな議論セグメントが作成された場合は,参照した発言と作成された議論セグメント内の導入発言間のリンク情報が生成・記録される.これにより,複数の会議コンテンツにまたがる要約などの応用を実現することができると考えられる.
5 まとめと今後の課題
我々は,ディスカッションマイニングと呼ばれる対面式会議から実世界活動に関するメタデータを獲得・記録することで,会議コンテンツを作成し,それを再利用する技術に関する研究・開発を行ってきた.本研究では,ディスカッションマイニングによって取得されたメタデータの妥当性を検証するための評価を行った.また,取得したメタデータを議論中に可視化することで,議論の活性化を促す仕組みの提案を行った.今後の課題としては,本稿で提案した可視化を行う仕組みの評価に加え,作成された会議コンテンツを会議のより高度な効率化に利用する仕組みの実現があげられる.