
デジタルコンテンツアノテーションとトランスコーディング
1 はじめに:情報の洪水の中で生き残るために
デジタルコンテンツがあたりまえのものとして世の中に溢れ出したのは20世紀の情報技術の進歩からすると必然的であっただろう。そして、それら膨大なコンテンツを活用するための技術もさまざまなものが発明され、進歩を遂げていくことは間違いがない。これまでは、ともかくコンテンツを制作して流通させることが主目的であったのに対し、これからは、それらのコンテンツをいかに賢く利用するか、あるいは、いかに多様に、多目的に利用するか、ということが最も重要な課題になると思われる。
一般に、「コンテンツ技術」とは、デジタルコンテンツを制作・保存・伝達する技術の他に、変換・加工・再利用する技術も含んでいる。コンテンツ技術に関する近年の最も重要な成果はXML (Extensible Markup Language)である。ここでは、デジタルコンテンツの変換・加工・再利用に力点を置く。デジタルコンテンツをどのように制作し、伝達するかということはもちろん重要であるが、制作されたコンテンツを変換・加工して、さまざまな用途のために再利用できれば、制作にかかったコストは相対的に下がっていき、人間の労力をどんどん減らしていけるようになるだろう。ゆえに、コンテンツ制作はその再利用を前提としたものになり、伝達は変換や加工を含むものになる。
デジタルコンテンツの変換・加工・再利用の形態には、たとえば、パーソナライゼーションとアダプテーションがある。デジタル放送の映像やWebページなどのデジタルコンテンツをユーザーの好みに応じて変換することをパーソナライゼーションと呼び、それらのコンテンツをPCやPDA (Personal Digital Assistant)や携帯電話などのデバイスの特性に合わせて変換することをアダプテーションと呼ぶ。
ここでは、パーソナライゼーションとアダプテーションを含むデジタルコンテンツの動的な変換を一般にトランスコーディングと呼ぶ。現状では、インターネットへのアクセスはPC経由で行われることが多い。しかし、この様相は近年、急激に変わりつつある。PCに加えて、携帯電話やPDA、テレビ、カーナビなどを使ってインターネットにアクセスする機会がますます増加するだろう。このとき重要となるものがトランスコーディングである。たとえば、PCで表示することを前提にして作成したWebページを携帯電話などで表示する場合、画像の縮小やテキスト部分の圧縮といった操作を自動的に行う必要がある。トランスコーディングには、少ない伝送容量を使ってサーバーからクライアントにコンテンツを配信できるという利点の他に、ユーザーの嗜好に応じた理解しやすいコンテンツを生成できるといった利点がある。
トランスコーディング技術を使えば、画面の表示機能やデータ伝送速度など、それぞれ違った仕様や制約をもつ多様な機器に対して、1つのコンテンツ・ソースから情報やサービスを提供できるようになる。コンテンツ・プロバイダやサービス・プロバイダは、それそれの機器に対応したコンテンツを個別に用意しなくても済む。具体的な応用例としては、PC向けWebコンテンツのトランスコーディングによって、携帯電話向けのコンテンツを生成するといった利用法がある。コンテンツ・プロバイダは、現状のようにPC向けと携帯電話向けのコンテンツを作り分ける必要がなくなる。
筆者は、インターネットにおいて最も重要な資源、すなわちデジタルコンテンツの今後のあり方について具体的な研究成果に基づいて提言しようと思う。それはWebを考案し、世界中に普及させるほどの偉大さはないかも知れないが、その意義は同じくらい大きなものであると思う。なぜなら、オンラインで共有された情報が「知識」となり、人間の知能を拡張するもののきっかけとなるものを作ろうとするものであるからである。多くの研究者が試みて得られなかったものが、情報技術の急速な発達とWebのような新しいインフラのおかげでようやく手に入れられるきざしが見え始めたのである。しかしながら、その前にやらなければならないことは多い。まず、現在直面している問題について考えてみよう。
1.1 オンラインコンテンツの問題
現在のオンラインコンテンツ(ネットワーク経由でアクセスできるデジタルコンテンツ)、具体的にはHTML文書などのWebコンテンツ、には主に以下の3つの問題が存在する。
-
HTMLではレイアウトなどの文書の表現については規定している。しかし、文書の意味などの内容に関してはほとんど何も規定していない。この点を改善するために後述するSemantic Webという構想が、World Wide Web Consortium (W3C)において議論されている。
発案者のTim Berners-Lee氏(彼はWorld Wide Webの発明者でもある)によると、Semantic Webとは「機械が処理できるWeb」という意味なのだそうである。彼にとってのコンテンツの意味とは自然言語の意味のことではなく、「機械がそのコンテンツを用いてできること」がそのコンテンツの意味なのであり、コンテンツが人間に直接もたらす効果は考慮していない。しかし、コンテンツは人間が直接利用できるものである限り、人間によってより適切なコンテンツを選択・提示するためには、コンテンツの意味をまともに扱わないわけにはいかない。
-
HTMLなどで記述したハイパーテキストは、各文書間のネットワーク構造を記述できる。ただしリンク情報が常に正しいとは限らず、その修正ができるのはもとの文書の著者だけである。リンク情報は、コンテンツの関連性を明示化する重要な手段であるが、複数のコンテンツを定義できるのがそれらコンテンツの著者とは限らないから、リンク情報はコンテンツそのものとは独立に記述できるようにするべきである。これは、W3CにおいてXLink (XML Linking Language)という名前で議論されている。
-
Web文書の著者は一般にその読者のことを考慮して著作してはいない。なおかつ著者と読者の間に立って吟味・調整する役割の人間も通常はいない。通常の出版物であれば著者と読者の間に編集者が介在するので、著者のみの判断によってメッセージが読者に届くわけではなく、第三者の手によって修正が加えられ、理解が容易になる可能性がある。これと同様な仕組みをオンラインコンテンツにそのまま導入するのは、一般のユーザーも巻き込んだ自由な出版の仕組みにとっては都合がよくないが、著者以外の人にコンテンツに対する評価や内容の修正を可能にする仕組みが必要である。これに関して、Annoteaと呼ばれる、Webページにコメントを付ける仕組みが存在する。しかし、コメントを作成したり、閲読するためには特別なブラウザ(クライアントソフト)が必要になる。
ここでは、これらの問題を解決するために、2つの技術を紹介し、それによってデジタルコンテンツがどのように進化していき、どのような新しい使い方が可能になるかについて議論していく。その2つの技術とは、トランスコーディングとアノテーションである。
1.2 デジタルコンテンツの拡張
従来のWebコンテンツは人間にとってわかりやすい点を重視して制作されてきたが、これは人間がそのコンテンツの主な利用者であるため至極当然のことである。しかし、コンテンツが爆発的に増加し、さらにマルチメディアデータも大量にオンライン化されていくと、それらをうまく処理するために、機械にとって都合のよいコンテンツ制作を考慮せずにはいられなくなるであろう。機械がコンテンツをよりよく「理解」できるようになれば、大量の情報の中から本当に必要なものだけを視聴することが可能になるため、コンテンツの利用法は大きく変わると思われる。われわれのグループでは、機械にとっての理解を容易にするためにコンテンツに補足情報を付与する仕組みを提案している。
「人にやさしい」だけでなく「機械にやさしい」コンテンツを作ることによって、そうでないコンテンツに比べて、かなり個別化することが容易になる。それは、コンテンツが個人の使用するデバイスなどの視聴環境に自動的に適合するということである。たとえば、テキスト文書に品詞や語義の情報が付与されていれば、プレインテキストに比べてはるかに容易に文法的に正しく、個人の読みやすさに適した要約が作成できるだろう。また、携帯電話のフォーマットに合わせたり、外国語に翻訳したりする場合にも有用である。さまざまなフォーマットごとにコンテンツを作り分けるのは、非常に多くの努力を必要とするが、アノテーションのような補足情報を早い段階でコンテンツに関連付けておけば、その後の処理はかなりの部分が改善され、その結果、従来よりずっと多くの視聴者を獲得することに成功するだろう。
アノテーションという考えは新しくはない。これまでにも多くのアプローチが、特にWebページに注釈を付けるという方向でなされてきた。その代表例は、ThirdVoiceである。これは、ページにポストイットのような付箋を貼ることができた。ここでのアノテーションとは、単なる注釈以上のものを指す。つまり、コンテンツに関するコンテンツ、すなわちメタコンテンツ一般である。アノテーションを用いることによって、コンテンツそのものを変更することなく、そのコンテンツを意味的に拡張することができる。具体的には、コンテンツに含まれるテキスト文要素に言語的なアノテーション(補足情報)を加えることによって、要約や翻訳などの自然言語処理の精度を大きく向上させることができる。
たとえば、アノテーションによってコンテンツに含まれるテキスト文の意味を明確にすると、正確な要約や翻訳が期待できる。コンテンツにアノテーションを付ける手間が増すが、重要な情報にはアノテーションを付けて正しく伝達し、共有すべきという考えに基づいている。このアノテーションはコンテンツの内容理解を促進するものと位置付けられる。現在、筆者らは原著者を含む多くの人々が文書の内容に関する補足的情報を付加できるような枠組み作りや、その情報を加味して文書を読者に適した形に加工する仕組み作りに取り組んでいる。特に、ここでは、3種類のアノテーション、つまり言語的アノテーション、コメントアノテーション、マルチメディアアノテーションと、それらを用いたコンテンツ加工、すなわちトランスコーディングについて詳しく述べる。言語的アノテーションは、主にテキスト文書の言語的構造や語彙の情報に関するもので、コメントアノテーションは、主にイメージ等の非言語的要素に説明文等の内容記述を加えるもので、マルチメディアアノテーションは、マルチメディアデータの構造や内容記述に関する補足情報である。
筆者のグループは、半自動的でインタラクティブなアノテーションツールを開発しており、これによってユーザーは任意のWebコンテンツの任意の要素に新たな情報を関連付けることができる。また、これらの関連付けられた情報を用いて、コンテンツをトランスコードするプロキシサーバーも開発している。アノテーションはすべてXML形式で記述されている。コンテンツとアノテーションの関連性は、URLおよびXPointerと呼ばれる仕組みによって実現されている。
われわれの仕組みの全体は、「セマンティック・トランスコーディング」という名称で呼ばれている。これは、コンテンツの意味情報を記述するアノテーションによって、高度なトランスコーディングを実現しているからである。セマンティック・トランスコーディングは、現在のところ、テキストとビデオの要約、翻訳、音声化、辞書に基づく詳細化、およびイメージのサイズ等の変換を扱っている。
アノテーションは、コンテンツからの知識発見においても有用である。われわれは複数のWebドキュメントから関連する部分を抽出して、一つの要約文書を作成するシステムを開発している。
図で示されるように、アノテーションは、現在のWebに上位構造を作る基盤になる。現在のWebコンテンツが最下層で、アノテーションはコンテンツに情報を付け加えるメタ(上位)コンテンツ、さらにメタコンテンツに対するメタコンテンツのように階層をなしている。
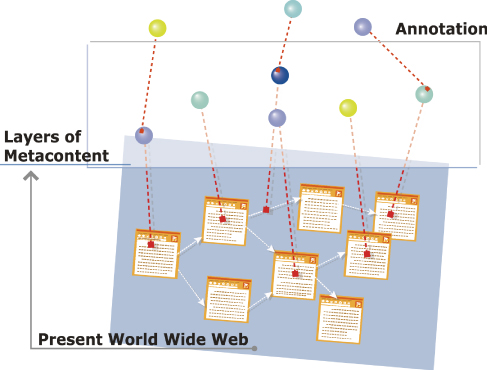
図1: アノテーションによるWebコンテンツの拡張
図にあるように、従来のWebコンテンツは一枚の平面上に存在する要素群として捉えることができる。セマンティック・トランスコーディングでは、Webコンテンツを平面から立体に拡張する手法を提案する。コンテンツの各要素に意味や文書構造を示すアノテーションを付加する。このことによってWebコンテンツに、コンテンツの各要素の意味や文書構造を記述した上位構造を築くことができる。
代表的なアノテーションの例としては、リンク元の文書に埋め込まれていないハイパーリンクであるXLinkや、コンテンツに対するコメントなどが挙げられる。アノテーションを作成して公開することが容易になれば、Webコンテンツの表現力は大幅に高まり、その利用価値が飛躍的に向上するだろう。
XLinkを使って、オンライン辞書のような従来からある資源とコンテンツを関連付けることができる。このリンクは、コンテンツに埋められておらず、外部に存在するので、辞書のアクセス手段が変更になった場合にも対応できる。この手法は、セマンティック・トランスコーディングにも取り入れられている。
Webには無数の情報があるため、ある特定の分野の背景知識を持たない人には、まったく理解できないコンテンツも存在する。たとえば、専門用語やジャーゴンのようなわからない言葉が使われている場合、読者はこの文書の正しい意味が理解できないだろう。
セマンティック・トランスコーディングは、この問題に対して、(1)文書に関連付けられた語義の情報、(2)語義とその定義を関連付けるオンライン辞書の利用、(3)辞書引きの結果をふまえて文書をわかりやすく書き換える機能によって対処する。
これまでにもWebブラウザ上である単語をマウスでクリックすると辞書引きの結果をポップアップウィンドウ上に表示するシステムは存在したが、このようなシステムには以下の3つの問題がある。
-
複数の語義を持つ単語の場合、辞書システムはすべての語義の説明を表示してしまい、ユーザーに正しい意味を選択するための負担を与えてしまう。
-
ポップアップウィンドウを表示するとクリックした単語の周辺が隠れてしまい、ユーザーは辞書の説明を読み終えてから、再び文脈を把握するのに困難になる。
-
辞書引きの結果と元の文書とは異なるレイヤーあるいはウィンドウに存在するため、要約、翻訳、音声化などの自然言語処理応用を続けて適用するのに不都合である。
以上の問題を考慮して、筆者のグループは語義を単語にアノテートするためのオーサリングツールを開発し、オンライン辞書にあるオントロジカルな記述と任意の文書内の単語をリンクする仕組みを構築した。
また、われわれのシステムは、図にあるように、中央にプロキシサーバーを配し、さまざまな情報リソースの統合や、ユーザーの要求を扱う。このプロキシサーバーはコンテンツのトランスコーディングを行うので、特別にトランスコーディングプロキシと呼ばれる。これに関しては、次の章で詳しく述べる。
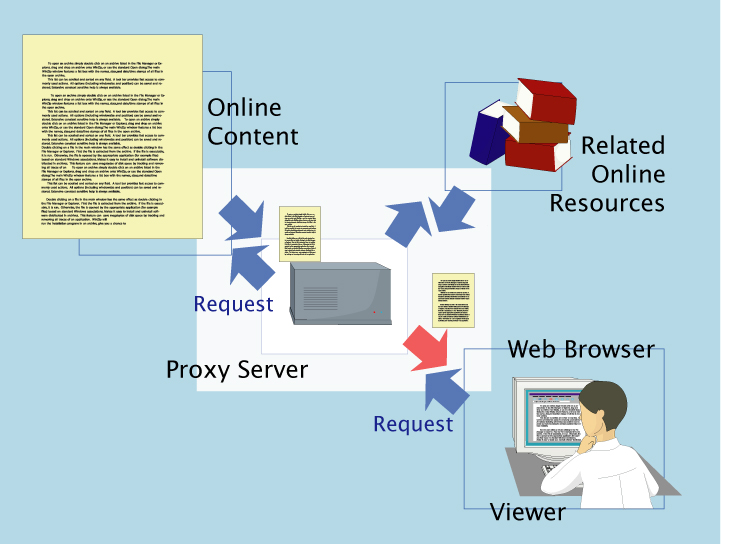
図2: 基本的なシステム構成
2 セマンティック・アノテーションとトランスコーディング:意味的に共有可能なデジタルコンテンツ
ここでは、人間と機械の間で意味的に共有可能なデジタルコンテンツを目指したアプローチについて述べる。そのようなコンテンツを作り出すためには、「情報のグラウンディング」つまり、機械が処理する情報の、人間の世界との明確な関連付けを行わなければならない。これは、人間と機械が情報の意味を共有するために不可欠なプロセスである。
近年、Web上でこのようなグラウンディングを扱うためのプロジェクトがW3Cにおいて提案されている。いわゆるSemantic Webがそれである。Semantic Webの最初の基本的な目標は、コンテンツに十分に定義された形式的記述を関連付けることである。この記述は、Webアプリケーションの開発者が、ある特定のコンテンツからそれに関するさまざまな属性を抽出し、その配信において考慮すべき問題を明確にするために利用される。
Semantic Webは現在のWebと切り離して設計されているのではなく、その情報の意味を明確に定義されたWebの拡張版として設計されている。近い将来に、機械は現在は表示のみに注意が向けられている情報の意味を処理でき、それによって、機械と人間はよりよく協調できるだろうということである。
Semantic Webは主に、コンテンツに含まれている概念の形式的な記述を要求するという意味でオントロジーに基づくアプローチを採用していると言える。これは、このような形式的な記述が一つのコンテンツに留まらず、より普遍的なものであるべきから、トップダウンなアプローチである。
もう一つのアプローチ、つまりアノテーションに基づくアプローチは、ここでの最も重要なトピックである。アノテーションは、ある特定のコンテンツに関わるものであり、この修正はインクリメンタルに行えることから、ボトムアップなアプローチと言える。当然、アノテーションを持つコンテンツは、機械的な理解や処理を促進し、高い精度で個人に適合したコンテンツに加工することができる。これは、やはり情報のグラウンディングを実現する一つの手段である。
オントロジーに基づくアプローチとアノテーションに基づくアプローチは、矛盾するわけではなく、お互いに補完的な関係にある。具体的なコンテンツがすでにある場合は、意味的な内容記述はコンテンツを密接に関連付けることができ、そのようなコンテンツがない場合は、より一般的な概念記述を詳細に定義し、具体的なコンテンツとの連結の仕方を定義しておく必要がある。前者は、アノテーションに基づくアプローチであり、後者はオントロジーに基づくアプローチである。これらをどのように統合するかは、さらなる研究が必要である。
以下では、Semantic Webにおけるコンテンツの意味とオントロジーに関してより詳しく議論する。
2.1 コンテンツのセマンティクスと情報グラウンディング
Semantic Webが機能するためには、機械は構造化された情報とその情報を使って推論をするための推論規則にアクセスする必要がある。人工知能の研究者は、Webが発明されるはるか以前から同様のシステムに関する研究を行ってきた。「知識表現」と呼ばれるこの技術は、まったく正しいアイディアであったにも関わらず、世界を変えるほどのことはまだ起こっていない。この技術によって実現可能な重要なアプリケーションは無数にあるが、そのすべての機能を実現するには、ある単一のグローバルなシステムにその技術を整合的に統合する必要があるのである。
Semantic Webの研究者は、それとは異なり、多用途性を達成するためには不整合さを許容し、すべての質問に答えることができないことを初めから認めるという立場をとっている。彼らは、Webにおいて十分な範囲で推論ができる程度の記述力を持つ推論規則用の言語を開発している。けっして全域的において整合である仕組みを作ろうとしているのではない。これは、初期のWebにおいて、中心的なデータベースや明確な構造を持たずに、組織化されたデジタルライブラリができるはずがなく、ゆえにすべての必要なものを発見することなど不可能である、という批判がなされたことに似ている。このような批判は正しかったが、システムの記述力は広範囲の情報を利用可能にすることに成功した。また、10年前には不可能だと思われていた、Webコンテンツの十分な規模のインデックスも作成可能になってきている。Semantic Webのチャレンジは、コンテンツと推論規則の両方を記述する言語を設計することにより、これまで知識表現のために構築されてきたさまざまな技術をWeb上で利用可能にすることである。
2.1.1 オントロジー
Semantic Webでは、情報の意味は情報資源の意味記述フレームワークであるRDFで表現される。RDFはXML形式による3つ組で構成され、その基本構文は主語、動詞、目的語に相当する。主語と目的語は情報資源の識別子であるURI (Uniform Resource Identifier) によるリンクで指示される対象であり、動詞は対象間の属性(AはBの一種とかAはBの一部とか)を表現する。ただし、動詞もWebで誰かが定義しているものを使う場合は、同様にURIで参照することができる。
もちろん、これで話は終わりではない。なぜなら、Web上に2つのデータベースがあってそれぞれが同一の概念に異なる名前をつけていたとしたら、機械はこれらが同じ意味であるかどうかを判別しなければならなくなるからである。理想的には、機械はどのようなデータベースに遭遇しようとも、共通の意味を持つ名前を自動的に発見できる仕組みを持つことが望まれる。
この問題に対処するために、Semantic Webでは、3つめの基本的コンポーネントである「オントロジー」と呼ばれる情報の集合を規定する。哲学では、オントロジーは存在論と呼ばれ、世界に存在する対象が持つ存在の本質に関わる体系のことを指す。人工知能研究者は、オントロジーを語彙の間の関係を形式的に記述するデータとして扱ってきた。オントロジーの最も典型的な例は、語彙間の階層構造や語彙間の推論規則の集合である。
語彙の階層構造は、記述対象のクラスやそれらの関係を定義する。たとえば、住所はある場所のタイプ、町コードなどで表現されるが、それらは同一の対象を指していると考えられる。複数の対象の間の関係をクラスやサブクラスによって記述することはWebにおいても重要なツールとなる。対象間の無数の関係は、クラスに属性を割り当て、サブクラスがクラスの持つ属性を継承することで表現される。もし町コードが町を表すあるクラスで規定されていて、町がそのWebサイトを持っているとき、町コードとそのWebサイトの間の直接的な関係がデータベースに定義されていなくても、一般的な町クラスの持つ町コードとWebサイトの関係を参照することで、容易に町コードからそのWebサイトのURIを調べることができる。
オントロジーにおける推論規則はさらなる力を提供する。たとえば、「ある町コードがある国コードに関連していて、ある住所がある町コードを使っていれば、その住所はその町コードに関連した国コードにも関連する」という規則が記述できる。それによって、あるプログラムは、名古屋大学は名古屋にあり、名古屋は日本にあるので、名古屋大学は日本にあり、日本の住所フォーマットに準拠して住所を記述すべき、ということが容易に推論できる。コンピュータがそのような情報を正しく「理解」しているとは言えないが、ある種の語彙操作を効果的に行い、人間にとって意味のあるものを自動的に生成することは可能になる。
Webにオントロジーを載せることで、語彙のミスマッチに関する問題に対処する明確な方法ができつつある。Webコンテンツに用いられる言葉の意味は、そのコンテンツからオントロジーの項目へのポインターによって定義される。このような問題はずっと以前から存在した。人の名前のことを、氏名や姓名などと表現して、異なるデータのように記述してもそれらの指す内容が同じであるといったことは頻繁に起こっている。これはオントロジーにおいて同値関係として定義することで解決できる。つまり、氏名と姓名と名前が同じ意味であるという関係を定義して、オントロジーに含めるのである。
クラス間の意味的な同値性が定義できれば、一方の形式から他方への自動的な変換が可能になるだろう。たとえば、あるサービスは、ユーザーの「名前」を要求しており、あるデータベースにはそのユーザーの「氏名」が記述されているとき、オントロジーの定義を参照することで、それらの同値性を認識し、自動変換によって「氏名」データを「名前」データに変換してサービスに渡すことができる。これによって、サービス間のミスマッチを解消して、より高度な相互運用性が実現できるだろう。
このようにオントロジーは、Webの機能を拡張することができると思われる。たとえば、Webの検索は、オントロジーを利用することで、曖昧なキーワードを用いる場合と異なり、特定の概念に関連のあるコンテンツのみを選択することができるため、ひじょうに精度の良いものになるだろう。より高度な応用は、Webコンテンツに含まれる情報をある知識の構造や推論規則に関連付けることであろう。
2.1.2 情報のグラウンディング
人間社会において情報技術を十分に有益なものにするためには、デジタルデータの日常世界に対する「情報グラウンディング」を行う必要があるだろう。それは、で述べられているように、機械と人間の間で情報の意味を共有することである。
いわゆるシンボルグラウンディング問題(記号接地問題とも呼ばれる)とは、もともと、デジタル情報は、人間の解釈によって外部から与えられるのではなく、それ自身が初めから持っているべき実世界での意味を、どうしたら持ちうるのだろうか、という問いであった。
もともとの議論におけるグラウンディングは、実世界というのは物理世界のこととして扱われる傾向が強く、それゆえ主にロボティックスの研究者の関心を集めていたが、現在の議論においては、実世界とは人間の日常世界のことであり、それは、物理的な側面のみならず、概念的、社会的、その他の側面を合わせ持っている。
このようなグラウンディングによって、われわれは「知的コンテンツ」と呼ばれるコンテンツの進化形を構築することができる。オリジナルのコンテンツは、自然言語による文書や映像・音声などさまざまなモダリティに関わり、それらの情報グラウンディングによって、より精度の高い検索、翻訳、要約、可視化などが可能になる。知的コンテンツを推進する活動には、前述のSemantic Webの他にGDA (Global Document Annotation)やMPEG-7などがある。
知的コンテンツを目指すアプローチには、主に以下の2つがある。
-
知識表現あるいは形式的オントロジーに基づくアプローチ Semantic Webで採用されているこの手法はコンテンツを部分的に置き換えた形式的表現とその要素の関係を明確に定義した形式的オントロジーを用いて、機械に実世界を反映した妥当な推論を行わせることによって、情報をグラウンドさせようとするものである。
-
アノテーションに基づくアプローチ 一方、GDAやMPEG-7で用いられている手法は、文書中の任意の文字列にタグをつけたり、ビデオの特定のシーンに属性を付与するなどして、原コンテンツに意味的な表現を細かい粒度で対応付けることによって、機械が意味的表現を経由して人間とコンテンツを共有し、グラウンディングを達成しようとするものである。
同様に、MPEG-7はマルチメディアデータにXMLに基づく記述を対応づける仕組みを含む。この場合、この記述そのものは原データとは切り離して管理することができる。
情報グラウンディングは、図に示されるように、自律的な機械の推論によってではなく、機械と人間のインタラクションによって実現され維持される。
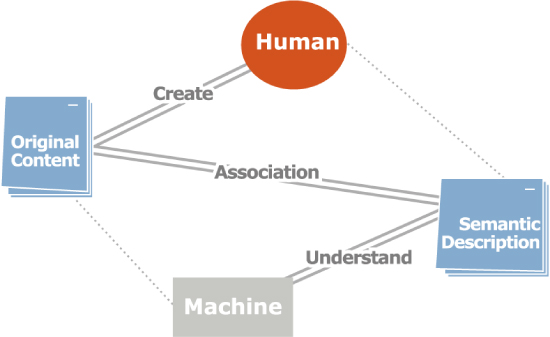
図3: コンテンツと意味記述の間の関連性と情報グラウンディング
この図において、線はさまざまな種類のインタラクションを表している。二重線は、より緊密なインタラクションである。たとえば、人間は原コンテンツの意味を理解し、それに対して適切な対応(他のコンテンツとの関連付けやコメントの付与など)が可能であるため、深いレベルでのインタラクションが期待できる。一方、機械は形式的な意味記述を適切に処理してそれに基づく検索や推論を行うことができる。つまり、機械は意味記述を原コンテンツに比べるとより深く理解した上でそれとインタラクションを行うことが期待される。これより、原コンテンツと意味記述を正しく結びつけることで、機械と人間の間のより深い情報共有が促進され、人間にとっての情報の意味と機械にとっての意味が整合性を持って関連付けされることになる。
このような意味で、情報グラウンディングが実現されることになるのであるが、これには以下のような利点がある。
-
まず、第一にこのような関連付けは、コンテンツの要約・翻訳・検索などにおいて明らかに有益である。まず、機械は意味記述に基づいて、要約や翻訳にとって手がかりとなる情報を抽出し、推論を試みるだろう。その後、関連付けに基づいて、原コンテンツの要素をユーザーの要求する形式に変換することができる。
-
次の大きな利点は、意味を記述するために不可欠なオントロジーの構築をある程度までさぼって、人間を楽にすることができることである。つまり、オントロジーを厳密に構成しないと実現できないような機械的な推論を、機械と人間とのインタラクションによって半自動的に行えるということである。これは人間が原コンテンツの意味を理解でき、その理解によって可能になる判断(たとえば、トピックの意味的な分類など)を、意味記述との関連付けによって、機械に伝達できるからである。たとえば、原コンテンツのトピックを分類するのに必要な情報を人間から引き出すことによって、その後の処理(たとえば、コンテンツの重要性の判断)を自動化することができるだろう。情報検索のような、一般にユーザーの要求とデータベースで検索可能な形式(質問文)の間に大きなギャップがあるような問題では、かなり深いレベルでの推論が必要になるだろう。しかし、そのために必要なオントロジーを事前に完成させておくことはきわめて困難であり、さらに、そのようなオントロジーは常に拡張され保守されていかなければならない。このような問題を現実的なレベルで解決するためにも、人間と機械のインタラクションを常に取り入れ、オントロジーの不備を補っていかなければならないのである。
-
3つめの利点としては、機械にとって有効な意味記述は自動生成できないため、常に人間が作っていかなければならないが、原コンテンツと意味記述の関連付けに基づいて、比較的楽に作成することができる点である。たとえば、任意の文脈で有効な意味記述を一から作成するのは、どのような専門知識を持った人にとっても非常に困難な仕事である。しかし、ある特定のコンテンツが与えられたときに、その意味を記述するという仕事ならば、似たようなコンテンツに関連付けられた意味記述を参考にしたり、自動的な解析結果を利用するなどして、比較的楽に行うことができるだろう。このように、原コンテンツと意味記述との関連付けの仕組みによって、人間と機械が共同で意味記述を作成していくことも可能になり、意味記述が関連付けられたコンテンツが十分に蓄積されていけば、将来的には、より広範囲に適用可能な意味記述(のテンプレート)なども作成できるようになるだろう。
以下では、主に、アノテーションに基づく、知的コンテンツへのアプローチに関して解説する。このアプローチは、コンテンツ主導のボトムアップなアプローチ、つまり、具体的なコンテンツを解析するところから始まり、より一般的な意味記述を作っていこうとするものである。われわれの構築したシステムは、特に専門知識を持たない一般の人にもWeb上のコンテンツにアノテーションを付与できるような、直感的なユーザーインタフェースを有している。これによって、現在のWebコンテンツから知的コンテンツへの移行を促進させることを意図している。
2.2 セマンティック・アノテーション
コンテンツを自動的に解析する技術はまだ不完全であるため、コンテンツの意味を機械に理解させるには人間によるサポートが不可欠である。人間と機械の共同作業によって作成された意味的アノテーションは、機械による理解の有益なヒントになる。このようなアノテーションは、コンテンツの記述力を増大させるだけでなく、コンテンツの再利用に重要な役割を果たす。たとえば、コンテンツをユーザーの好みに従って変換(トランスコーディング)する場合である。
コンテンツ適応は、ユーザーのコンテンツ視聴環境(たとえば、使用デバイス、ネットワークバンド幅、プロファイルなど)を考慮したトランスコーディングの一例である。このような適応は時に原コンテンツの理解を必要とする。もしコンテンツの意味構造の解析に失敗した場合、トランスコーディングの結果はユーザーにコンテンツを誤解させる原因となるかもしれない。
意味的アノテーションによってトランスコーディングの質を向上させることができる。このような意味的アノテーションに基づくトランスコーディングをセマンティック・トランスコーディングと呼ぶ。セマンティック・トランスコーディングの全体の構成は図のようになる。
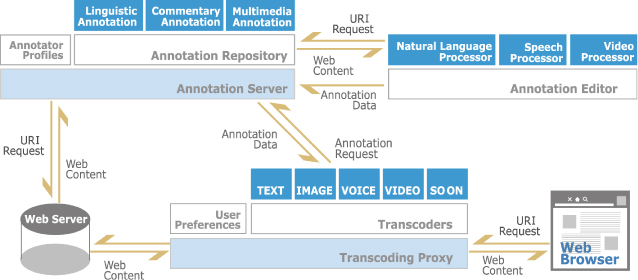
図4: セマンティック・トランスコーディングシステムの構成
われわれのグループでは、Web上の任意のドキュメントやマルチメディアデータの任意の構成要素に対して意味的アノテーションを関連付ける手法を開発してきた。ここで、「意味的」という言葉は、機械が原コンテンツの意味を理解するために有益なものということを表している。つまり、意味的アノテーションは、人間の理解を促進するためだけでなく、機械による理解を支援することを前提としている。
ここで、XMLやHTMLドキュメントの要素を指定するやり方として、URI(その実例としてのURL)とXPointerを用いる。また、URIが等しくてもドキュメントが異なる場合があるので、MD5に基づくハッシュコードも補助的に用いる。つまり、アノテーションを蓄積・管理するサーバー(アノテーションサーバー)は、アノテーション獲得時に、原コンテンツのハッシュコードを計算し、アプリケーションからのアノテーション要求時に、再び原コンテンツにアクセスし、URIとハッシュコードが共に一致した場合のみ、アノテーションが有効であると判断し、要求元のアプリケーションにアノテーションデータを送信する。
2.2.1 アノテーション作成・利用環境
ここでのアノテーション作成・利用環境は、図に示されるように、クライアントサイドでアノテーション作成を支援するエディタとアノテーションのデータベースを管理し、トランスコーディングシステムなどのアプリケーションからの要求に対応するサーバーによって構成される。
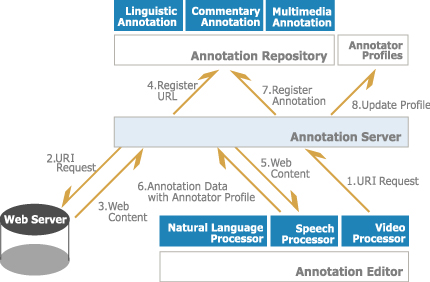
図5: アノテーション作成・利用環境
たとえば、原コンテンツがXMLあるいはHTMLドキュメントである場合、アノテーションの作成からアノテーションサーバーへの登録に至るプロセスは以下のようになる。
-
まず、アノテーションエディタ(ここでは、単にエディタと呼ぶ)を起動して、対象となるコンテンツのURIをアノテーションサーバーに送信する。
-
次に、アノテーションサーバー(ここでは、単にサーバーと呼ぶ)は、この要求を受け付け、URIリクエストをコンテンツサーバー(通常のWebサーバー)に送信する。
-
サーバーは、コンテンツを取得する。
-
このとき、サーバーはコンテンツのハッシュコードを計算し、URIと共にデータベースに登録する。
-
サーバーはコンテンツをエディタに返す。
-
ユーザーは、要求したコンテンツに対するアノテーションを作成し、そのアノテーションを記述したデータをサーバーに送信する。このとき、同時にユーザーの個人情報(名前や専門分野など)暗号化して電子署名を作成し、アノテーションデータと一緒にしてサーバーに送信する。
-
サーバーは、アノテーションデータを受け取り、先ほどのURIと関連付けて、データベースに格納する。
-
サーバーは、さらに、アノテーションデータに付随する電子署名を復号化して個人情報を取り出し、アノテータプロファイルとしてデータベースに格納する。
以下では、このサーバーとエディタについてより詳しく解説する。
2.2.2 アノテーションエディタ
コンテンツに効率良くアノテーション情報を付加するために、われわれはアノテーションエディタと呼ばれるオーサリングツールを開発している。これをアノテーションデータの自動生成や編集に用いる。アノテーションエディタはJavaアプリケーションとしてユーザー側のクライアント上で利用できる。生成したアノテーションデータは、アノテーションサーバーへ送信され、分類/格納される。このエディタを使って、ユーザーは言語構造(構文や意味に関する構造)に関するアノテーションをテキスト文に付加したり、コンテンツ内の画像や音声といった要素にコメントを付けたりすることができる。言語構造に関するアノテーションは自動生成できる。ただし、その構造に曖昧さが含まれる場合は、ユーザーがアノテーションエディタを操作して修正する。言語構造の表示は、グラフィカルに表示してその構造が把握しやすいように工夫した。
このアノテーションエディタは以下のような機能を持っている。
-
先に述べたようにURIを用いて、アノテーションサーバーにアノテーションの対象となるコンテンツを登録することができる。
-
コンテンツ(ただし、XMLあるいはHTMLドキュメントに限る)の任意の要素を、Webブラウザ上で選択できる。
-
コメント文や後述する言語的アノテーションを含むアノテーションデータの生成と、アノテーションサーバーへの送信ができる。
-
ターゲットの原コンテンツが更新された場合に、以前に作成したアノテーションを再利用することができる。
-
エディタのユーザーであるアノテータの電子署名を作成し、アノテーションデータと関連付けることができる。
図は、アノテーションエディタの画面例である。これは、テキストに含まれる言語構造を自動解析し、その結果を修正するツールである。言語構造を視覚的にわかりやすく表示し、簡単なマウス操作で修正できる。その他の機能として、HTML文書の任意のタグ要素にコメント文を付け加える機能がある。
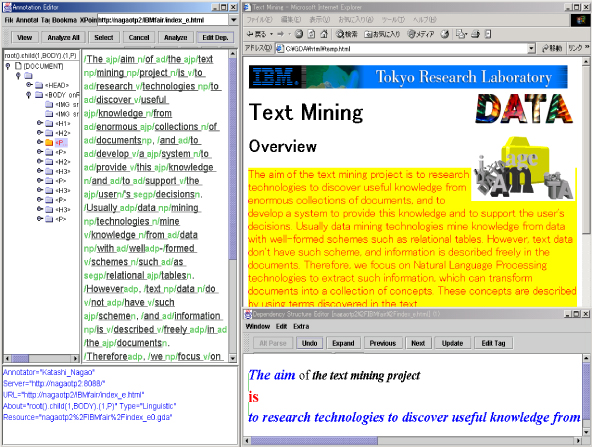
図6: アノテーションエディタの画面例
エディタ画面の左上には、コンテンツの内部構造、たとえばHTMLドキュメントのタグで構成される木構造(ドキュメントオブジェクトモデルと呼ばれる)を表示する。その右のウィンドウにはブラウザ上で選択されたテキストが表示される。この選択された部分にはXPointer(厳密にはXPath)が自動的に付随される。右下のウィンドウは選択されたテキストを構成する文の言語構造が表示される。この言語構造に関しては後で詳しく述べる。
2.2.3 アノテーションサーバー
アノテーションサーバーは、受け取ったデータをアノテータの名前で分類し、管理している。これはアプリケーションが特定のアノテータによって作成されたアノテーションのみを要求することができるようにするためである。サーバーは、アノテーションの対象であるコンテンツのURIからコンテンツを取得するごとに、そのハッシュコードを計算し、コンテンツが更新されているかを判断するが、このときコンテンツの内部構造(ドキュメント・オブジェクト・モデル)を考慮したハッシュコードを計算する(DOMハッシュと呼ばれる)ことによって、コンテンツのどの部分が更新されており、どの部分が更新されていないかを判断することができる。これによってアノテーションデータの有効性を判断し、無効となったアノテーションをエディタに伝達して、再編集を要求することができる。
アノテーションサーバーはアノテータ名、URI、XPointer、コンテンツのハッシュコード、アノテーションデータのデータベース上のアドレス、アノテーションのタイプ(コメント、言語的、マルチメディア)のテーブルを作り、トランスコーディングなどのアプリケーションシステムから特定のコンテンツに関するアノテーションの要求があった場合、ハッシュコードの整合性をチェックした後に、アノテータ、XPointer、タイプに関する情報をヘッダー部に持つアノテーションデータの集合を含めて応答する。リクエスト中に特定のアノテータの名前が指定されている場合は、そのアノテータによって作成されたアノテーションの集合のみを返す。
マルチメディアアノテーションの場合は、アノテーションの対象となるコンテンツのXPointerやハッシュコードを計算することは一般にできないため、任意の要素を指定する場合は時間間隔(ビデオや音声の場合)や矩形領域(イメージの場合)を用い、コンテンツの同一性の手がかりとしてデータサイズを用いている。
われわれのグループは、アノテーションサーバーからコンテンツサーバーへアクセスするときに、アクセス制限をかけることによって、原コンテンツの著作者が自分のコンテンツにアノテーションを関連付けることを制限することができるような仕組みを開発している。この場合、著作者はコンテンツにアノテーションを制限する声明を付随させ、アノテーションサーバーがこれを解釈して、エディタからのアノテーションの新規作成要求の時点で、コンテンツのURIとアノテータの名前などに基づいて、要求を拒否する、あるいはパスワードを提示させ判断する、などのやり方で対応できるようにしている。
2.2.4 言語的アノテーション
言語的アノテーションはデジタル化された文書を機械が適切に理解可能にするように導くためのガイド情報であり、現在利用可能な、いかなるアプリケーションよりも高い品質で検索、質問応答、要約、翻訳などの文書処理が実現できるようにする重要なステップの一つである。
ここでわれわれは、前述のGDAタグセットを用いて、文書の言語構造(文内・文間構造)や意味属性(語義)などの情報を形式的に記述している。
GDAは自然言語で書かれたオンライン文書を機械にとって理解可能にし、さまざまな自然言語アプリケーションを高い精度で実現することを目的としたチャレンジングなプロジェクトであり、XMLベースのタグセットの標準化を目指している。
GDAタグセットは、TEI (Text Encoding Initiative) , CES (CorpusEncoding Standard) , EAGLES (Expert Advisory Group onLanguage Engineering Standards) などの既存の言語構造分析とその標準化に関するプロジェクトの成果と可能な限り互換性を持ちつつ、これまでのプロジェクトが扱っていなかった、より深い意味に関する構造や属性に関する標準化も射程に入れている。既存のプロジェクトは、図書館や出版社や個人研究者などが研究や教育等を目的として、できるだけ表現力が豊かで、かつ将来に渡って利用できる形式的枠組みを考案し、あらゆる種類の図書や言語的資源を記述し蓄積・管理できる標準的なプラットフォームを構築することを目的としている。GDAは、さらに一般的利用者にとってもメリットがある仕組みを開発して、情報流通を促進させることを念頭に置いている。自然言語処理システムにとって、直接的に利用可能なものとして、GDAは特に係り受け関係や照応関係、さらに語義を中心に扱っている。
GDAタグ付きの文は、たとえば、次のようなものである。
<su><adp opr="loc"><adp opr="pos">人間の</adp> <np sem="0f2e4c">細胞</np>には、</adp> <np syn="c"><np><vp><adp><adp> <np sem="0f74e9">自動車</np>でいえば</adp> <adp opr="iob">アクセルに</adp>当たり、</adp> <adp opr="obj"><np id="a1" sem="3be2c7">がん</np>を</adp> <adp opr="gra">どんどん</adp>増殖する</vp> <n>「<namep id="a2"><np eq="a1" sem="3be2c7">がん</np> <n id="a3" sem="3bf4d0">遺伝子</n></namep>」</n></np>と、<np><adp> <np sem="107ab3">ブレーキ</np>役の</adp> <n>「<namep id="a4"><np eq="a1" opr="obj" sem="3be2c7">がん</np> <n sem="10d244 3cf57c">抑制</n> <n eq="a3" sem="3bf4d0">遺伝子</n></namep>」</n> </np></np>がある。</su> <su><adp opr="cnd"><adp opr="sbj"><np><adp opr="pos"> <np eq="a2 a4" sem="0face2">双方</np>の</adp>バランス</np>が</adp> 取れていれば</adp>問題はない。</su>
これらは統語構造を表わしており、各エレメント(タグで囲まれた部分)は統語的構成素である。ここで、
GDAの仕組みでは、多くのWebドキュメントの著者たちが、彼らのドキュメントに共通のタグセットでアノテーションを施すことによって、機械が自動的にそれらのドキュメントの根底にある意味的あるいは語用論的構造を認識することを目指している。その結果、知識のみならず知識の運用の仕方までをカバーする、ワールドワイドで自己増殖的な知識ベースが実現されるであろう。
GDAプロジェクトでは、次の3つのステップを実行し、最終的な目標に迫ろうと考えている。
-
まず、ドキュメントの構造を機械に認識させるためのXMLに基づくタグセットを提案する。
-
次に、タグ付きのテキストを多用途で知的なコンテンツとするための自然言語処理ならびに人工知能システムを構築し、Web上で運用を行って普及させる。
-
最後に、Webドキュメントの著者に彼らのドキュメントを提案したタグセットで構造化することの動機付けを与え、実行させる。
第1ステップで提案されたタグセットは、さらに深い意味を機械に推論されるために、参照関係や談話関係の他に、著者と読者の間の社会的関係や他のドキュメントの間の意味的関連性なども記述できるようにする。
第2ステップは、機械翻訳、情報検索、情報フィルタリング、データマイニング、質問応答、エキスパートシステムなどの人工知能応用を視野に入れている。ここでのタグセットで厳密に構造化されたドキュメントはこれらの応用システムの精度を飛躍的に向上させるだろう。それによって、新たなコミュニケーション支援ツールが開発されることになるだろう。
第3ステップは、アノテーションの結果として、自分の発信する情報によりよくマッチする受信者を世界中から見つけ出せることが可能になることを動機として、自らコンテンツの構造化を行うことを促進する。これは、標準的で適切なタグで構造化されたドキュメントは高い精度で翻訳・検索され、それによって、より望ましい読者を獲得する機会が大幅に増えることを前提としている。つまり、従来のドキュメントの差別化手法である絵や音による装飾という手段ではなく、より本質的で効果的な方法でコンテンツを差別化できるということである。
2.2.5 言語的アノテーションエディタ
言語的アノテーションエディタは、テキストコンテンツに言語構造(統語的・意味的構造)を関連付けるためのツールである。また、このエディタは基本的な自然言語処理の機能と曖昧さをインタラクティブに解消するための機能を持つ。図に示されるように、自動的に解析された文構造を容易に修正できるようになっている。
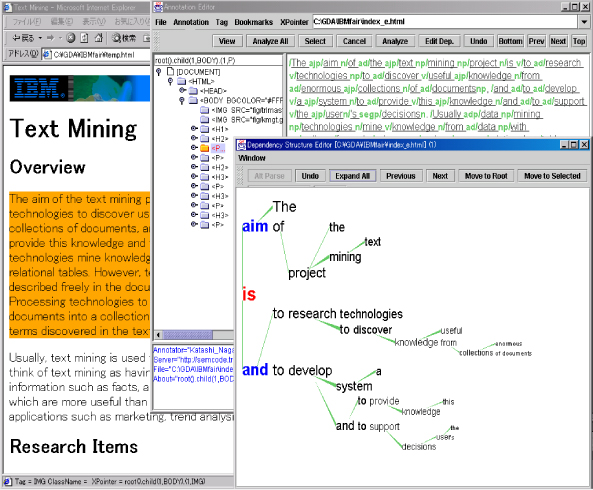
図7: 言語的アノテーションエディタの画面例
計算言語学の分野では、語義的曖昧さの解消は最も困難の問題の一つである。たとえば、ドキュメントの正しい翻訳のために、多義語の訳語を特定するのは不可欠な問題である。もし従来の手法で、ある程度の精度までそれがうまくいくとしても、訳語の選択を一つでも間違うと全体の翻訳が誤りを含み、それによって読者に誤解を生じさせる原因となるだろう。
この問題を回避するために、ドキュメントの多義語の部分に、たとえばWordNetで定義されている語義のアノテーションを行う仕組みを用意している。これによって、機械が多義語の意味を正しく理解できる。
このようなことを一般的に行うためには、いわゆる概念辞書が必要になる。概念辞書は前述のオントロジーを辞書として利用可能にしたもので、概念には適切な名前が付けられている。オントロジーは、もの、こと、関係などの概念記述の集合で、複数の機械の間で同一の情報を共有するときに利用される。
つまり、語義に関するアノテーションは、ドキュメント中の単語(あるいは複合語)とオントロジーに含まれる概念の間にリンクを張ることに相当する。われわれの作成した語義アノテーションツールは、WordNetを一つのオントロジーと見なしてそれに含まれる語義を概念とし、そのラベルを属性として単語や複合語のタグに付加することができる。
われわれのアノテーションエディタによって、ユーザーは統語的あるいは意味的言語構造をドキュメントの任意の要素に付与でき、またそれらの要素にコメントを付けることができる。また、図に示されるような語義アノテーションのためのツールを備えている。この図の右中央にはオントロジービューアと呼ばれるオントロジー(ここではWordNet)の表示ウィンドウがあり、オントロジーに含まれる概念を容易に選択することができる。選択された概念のラベルは、ドキュメント内の任意の領域の語義属性として付け加えられる。
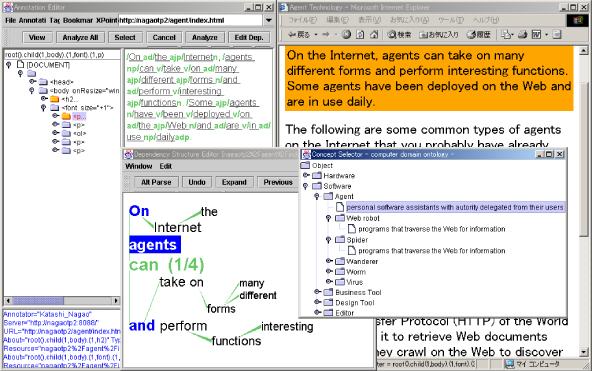
図8: 語義アノテーションのサブウィンドウ
2.2.6 コメントアノテーション
コメントアノテーションは、主にドキュメント内の非テキスト要素(画像や音声など)にテキスト情報を関連付けるために用いられる。ただし、コメントはテキスト要素あるいはその部分(言語構造のタグが付いているもの、あるいは個々の文字)に付与することもできる。また、コメントの内容はテキストとは限らず、イメージやリンクを含むこともできる。現在のところ、コメントアノテーションは、図に示されるようにドキュメントの上に重なる子ウィンドウ内に、ユーザーがコメントが付与された対象(あるいは、テキストの場合はコメントの存在を示すアイコン)にマウスカーソルを置いたときに表示される。
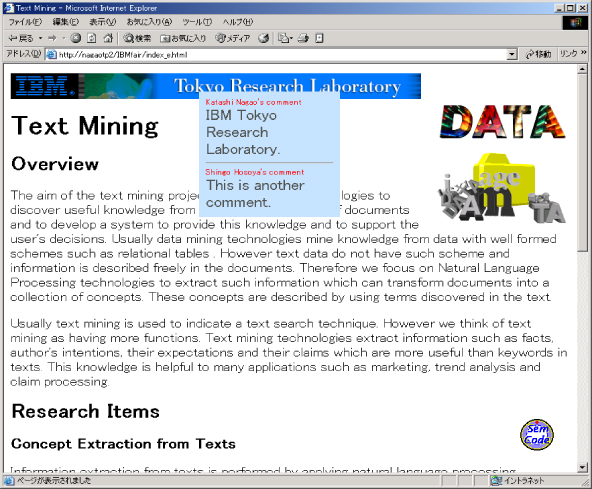
図9: コメントアノテーションの画面例
テキスト要素にコメントを付与する場合、ドキュメント内の単語の綴りが間違っている場合は、正しい綴りのものをコメントとして付けたり、難しい表現に対するよりわかりやすい言い換えを付けたり、言葉にアンダーラインを付けることができる。このようなアノテーションは、後述するテキストトランスコーディングにおいて原テキストとコメントを合成して、新しいテキストを自動生成する場合に利用される。
ハイパーリンクに対するコメントアノテーションは、リンクをクリックする前にリンク先のドキュメントに関する情報を表示することなどに利用することができる。もしリンク先のドキュメントに言語的アノテーションが与えられている場合は、リンク先ドキュメントの要約や翻訳を行って、リンク元のコンテンツのハイパーリンクにコメントとして関連付けることもできる。
これまで、Webにおけるコメント共有に関する研究はさまざまなものが行われてきた。たとえば、Annoteaは、Web上のドキュメントにメタ情報を付与する一般的な仕組みを提供する。この仕組みは、基本的なサーバー・クライアント間のプロトコル、一般的なメタ情報記述言語(RDF)、サーバーシステム、オーサリングツールとブラウザから成る。Annoteaによって、ユーザーは任意のドキュメントの任意の位置にコメントを付け、他のユーザーと共有することができる。
これらのコメント共有システムの多くは、特定の人たちの間で特定のドキュメントを共有する場合に用いられているが、われわれのアノテーションおよびトランスコーディングシステムは、Web上の任意のドキュメントの任意の要素に、複数のコメントを付け、共有することを可能にしている。また、コミュニティに限定したアクセス権を持たせることも可能にしている。あるトランスコーディングプロキシが、あるコミュニティ専用のコメントを処理することができ、さらにそのコミュニティからのアクセス以外は受け付けない仕組みにすることができる。将来的には、アノテーションサーバーとトランスコーディングプロキシの間の通信に安全性を考慮した特別なプロトコルを適用し、他のサーバーやプロキシから許可なくアクセスされ、アノテーションデータを利用されるのを防ぐこともできるだろう。
ここでの中心的な話題は、オンラインコンテンツをユーザーに適応させることであり、コミュニティ内でコメント付きドキュメントを共有するのはある特別な機能の一つに過ぎない。後述するように、われわれのトランスコーディングシステムでは、コメントと言語的アノテーションをすべてコンテンツの意味を考慮した変換に利用することを考えている。
ただし、コメントアノテーションは、専門家のグループにおける知識共有と再利用においても利用される。
2.2.7 マルチメディアアノテーション
マルチメディアコンテンツ(たとえば、デジタルビデオ)は、近年、ますますあたりまえの情報ソースとなってきている。このようなコンテンツは、データサイズも大きく、視聴するのに時間がかかるため、重要な部分を逃さずに必要な部分だけ効率的に視聴する要約等の手段が求められている。シーン等の映像の断片や映像内の人物や対象物に関する意味情報をマルチメディアコンテンツに関連付けることは、将来の高度なマルチメディアコンテンツサービスにとって非常に重要なことである。音声のトランスクリプトのような自然言語テキストは有用性が高いので、音声・自然言語処理はマルチメディアアノテーションにとって不可欠な役割を果たす。
われわれのグループでは、次のものを統合した半自動的ビデオアノテーション技術を開発している。(1)多言語音声トランスクリプション、(2)自動ビデオ解析、(3)インタラクティブ映像・音声アノテーションである。自動ビデオ解析は、色変化検出、フレーム解析、フレーム属性の類似度に基づいたシーン認識を含む。
ビデオアノテーションに関しては、これまでのさまざまなアプローチがなされてきた。たとえば、前述のMPEG-7は、マルチメディアコンテンツの必要な部分を高速に検索できるようにするためにインデックスやコメント等を記述して関連付けることができる。しかし、これらの記述を人手で作成するには多大なコストがかかるため、自動的にコンテンツを解析して人間を支援する仕組みが必要である。われわれの手法は、MPEG-7データを作成するツールに統合することができる。MPEG-7の追加提案の一つである言語的記述スキーマは、この統合において重要な役割を果たすだろう。
このようなアノテーションデータに基づいて、われわれは高度なマルチメディア処理に関するビデオ要約と翻訳システムを開発した。要約ビデオは単にオリジナルビデオの短縮版ではなく、ビデオシーンのキーフレームやトランスクリプトを含むインタラクティブなマルチメディアプレゼンテーションコンテンツである。ユーザーは、このコンテンツを操作し、視聴するだけでなく、要約のサイズを変えてみたり、要約に含めてほしいキーワードを入力するなどして、要約結果をカスタマイズすることができる。また、ユーザーの視聴するデバイスがビデオ再生機能を持たない場合は、ビデオドキュメントと呼ばれるHTML形式のビデオ内容を説明するドキュメントを自動生成して配信することもできる。
マルチメディアアノテーションは、異なるデバイスに向けたマルチメディアコンテンツの配信において非常に有効である。アノテーションによって、異なる目的(ダイジェスト視聴、通常視聴、キーフレームのみ閲覧など)、異なるクライアントデバイス(PC,PDA,携帯電話など)等に適合させたコンテンツを配信することができる。また、コンテンツの構成要素に関する記述によって、音声や映像の特定の部分に関する検索や閲覧が可能になる。
マルチメディアアノテーションは、テキストアノテーションの拡張として捉えることもできる。文字データは、バイナリーデータ(イメージやビデオなど)に比べて、加工や検索が容易なため、マルチメディアに対しても自然言語文を含むテキストをさまざまな手段で関連付ける。たとえば、ビデオに含まれるナレーションなどの音声を文字化し、タイムスタンプを付けることによって、ビデオの適切な場所にテキストを対応付けることができる。クローズドキャプションのような字幕情報からテキストを抽出することもできる。マルチメディアアノテーションに含まれるテキストには前述のGDAのような言語的アノテーションが付与される。
2.2.8 マルチメディアアノテーションエディタ
われわれのグループでは、マルチメディアアノテーションのオーサリングツールの一つとして、ビデオアノテーションエディタと呼ばれるシステムを開発している。このエディタはビデオカット(シーンチェンジ)検出、多言語音声トランスクリプション、言語解析、テキストとビデオの関連付けなどの機能を持つ。
図にこのエディタの画面例を示す。エディタ画面は、3つのウィンドウから成り、上の画面はビデオの内容(キーフレームのイメージ、トランスクリプト)、左下はトランスクリプトの編集用で、右下はその言語構造を編集するためのウィンドウである。ビデオを読み込むと、まずカット検出によって、シーンの開始終了時間とそのキーフレームが自動認識され、同時に、音声認識によってトランスクリプトが生成される。もし複数言語の音声が含まれる場合は、それを分離して、それぞれの言語用の音声認識エンジンに渡され、結果が表示される。トランスクリプトには音声が認識された時間が自動的に付与され、ビデオシーンとの対応付けが自動的に行われる。トランスクリプトの言語構造も自動的に解析され、ユーザーはその結果に含まれる誤りを修正する。
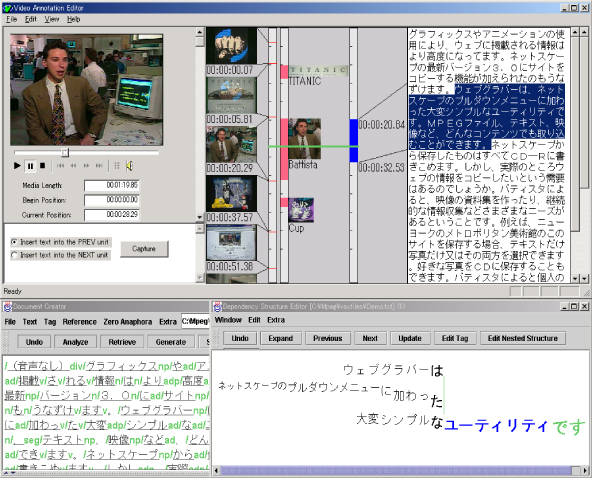
図10: ビデオアノテーションエディタの画面例
このエディタによって、ビデオコンテンツの内容記述が半自動的に生成される。ユーザーは、シーン、映像オブジェクト、音声トランスクリプトおよびその言語構造をインタラクティブに編集して、アノテーションデータを作成する。このアノテーションデータは、前述のアノテーションサーバーに送信され、管理される。
2.3 セマンティック・トランスコーディング
セマンティック・トランスコーディングは、アノテーションにもとづくトランスコーディング手法であり、ユーザーの好みに応じたコンテンツ適応が可能である。トランスコーダつまりトランスコーディングを行うモジュールは、HTTPプロキシの拡張として実装されている。つまり、HTTP (HyperText Transfer Protocol)でコンテンツとアノテーションがやり取りされる。
図は、セマンティック・トランスコーディングの全体の仕組みを表している。
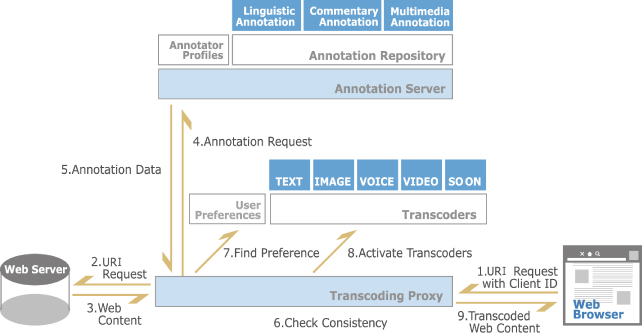
図11: トランスコーディング環境
トランスコーディングにおける情報の流れは以下のようになる。
-
トランスコーディングプロキシ(以下、単にプロキシ)はクライアント(主にWebブラウザ)からクライアントID(後述)とURI (Uniform Resource Identifier)リクエストを受け取る。
-
プロキシは、URIリクエストをWebサーバーに送信する。
-
プロキシはWebサーバーからコンテンツを受け取り、そのハッシュコードを計算する。
-
プロキシは、同時に、あらかじめアドレスが設定されているアノテーションサーバーにURIに関連したアノテーションデータを要求する。
-
アノテーションサーバーに該当するアノテーションデータが存在する場合、それをプロキシに送信する。
-
プロキシはデータを受け取ると、それに含まれるコンテンツのハッシュコードと先に計算したものを比較する。
-
プロキシは、同時に、自分のデータベースから、受け取ったクライアントIDに対応するプリファレンスデータを検索する。もし存在しない場合は、デフォルトのプリファレンスを用いる。
-
コンテンツのハッシュコードが一致した場合、プロキシはアノテーションデータとプリファレンスデータを考慮して、必要なトランスコーダを起動する。トランスコーダは並列あるいは直列に実行される。直列の場合は、トランザクションデータとして、トランスコードされたコンテンツを次のトランスコーダに引き渡す。
-
プロキシは最終的にトランスコードされたコンテンツをクライアントのブラウザに送信する。
トランスコーディングプロキシと各トランスコーダについては、以下でより詳しく述べる。
2.3.1 トランスコーディングプロキシ
われわれはIBMの開発したWBI (Web Intermediaries)をセマンティック・トランスコーディングシステムの開発プラットフォームとして採用した。
WBIはJavaによるプログラミングによって拡張可能なHTTPプロキシである。WBIはユーザーに対して個別にアクセス制限をかけることやその入出力に操作を加えるためのAPI (Application Programming Interfaces)を提供する。
WBIに基づくトランスコーディングプロキシは次の機能を持つ。
-
ユーザーのプリファレンスデータの管理
-
アノテーションデータの収集と管理
-
トランスコーダの起動とその結果の統合
ユーザープリファレンスの管理を行うには、まずアクセスしてきたユーザーを特定する必要がある。ユーザーの特定には通常のWebブラウザで用いられているCookieを使う。プリファレンスを管理するIDを、Cookieデータとしてユーザーに渡す。これにより、ユーザーのアクセスポイント(自宅、職場、外出先など)に関係なくユーザーの特定が行なえる。ただし、既存のWebブラウザは、Cookieをセットしたサーバーに対して、そのCookieを渡すものであり、一般にプロキシによるCookieの利用は考慮されていない。通常プロキシは、ホスト名とIP (Internet Protocol)アドレス(これをクライアントIDと呼ぶ)のみによってユーザーを識別する。そこで、ユーザーがプリファレンスデータをセットした時に、Cookie情報(ユーザーID)とプリファレンスデータを関連付け、一方、アクセスポイントの変化ごとにIPアドレスとホスト名、Cookie情報(ユーザーID)を関連付け直す。これによりIPアドレスが変化してもユーザーの特定が行える。つまり、通常のプロキシとして動くときは、クライアントID(ホスト名とIPアドレス)→Cookie情報(ユーザID)→プリファレンスデータという流れで、クライアントIDからプリファレンスを引き出す。アクセスポイントが変化したときは、プロキシをWebサーバーとしてアクセスすることでCookie情報を取得し、クライアントIDとCookie情報(ユーザーID)を関連付け直す。
トランスコーディングプロキシは、アノテーションサーバーと通信して、アノテーションデータを入手する。アノテーションサーバーは複数存在することができるので、セマンティックトランスコーディングの次のステップでは、分散するアノテーションサーバーから効率よくアノテーションデータを収集する必要がある。
トランスコーディングプロキシは、分散する複数のアノテーションサーバーを定期的に巡回し、それぞれの持つアノテーションデータの索引を収集する。それによって作成されたアノテーションデータの索引集(マルチサーバーアノテーションカタログ、以下では単にカタログと呼ぶ)を定期的に作っておく。このカタログは、サーバー名(ホスト名とIPアドレス)とアノテーションインデックス(アノテータ名、原コンテンツへのポインタ、アノテーションデータのアドレスの3つ組)から成る。このカタログを、ユーザーからのコンテンツの要求があったときに、どのアノテーションサーバーからデータを入手すべきかを判断するために役立てる。
トランスコーディングプロキシの最も重要な役割は、ユーザーのプリファレンスデータとアノテーションデータに基づいてコンテンツを加工することである。コンテンツの加工は、適切なトランスコーダを選択的に起動し、その結果を統合することによって行う。加工された結果は、要求元のクライアントに配信される。同じコンテンツに対して、プリファレンスを変更して、再びトランスコーディングを実行することもできる。
現在、開発済みのトランスコーダは、テキスト、画像、音声、映像にそれぞれ対応したものである。これらのトランスコーダを直列あるいは並列に起動し、結果を結合することで、複合的なトランスコーディングが実現できる。たとえば、文書を要約後に翻訳して、さらに音声化するなどの一連の処理をトランスコーダの使い分けにより行う。
2.3.2 テキストトランスコーディング
テキストトランスコーディングは、言語的アノテーションを持つテキストコンテンツを、ユーザーの要求する形式に変換するものである。われわれは、いくつかのタイプのテキストトランスコーディングを実現している。それは、テキスト要約、言語翻訳、テキストパラフレーズ(言い換え)、そしてテキスト音声化である。ただし、音声化については、音声トランスコーディングのところで触れる。
言語的アノテーションの一つの単純な応用例として、テキストトランスコーダに自動テキスト要約のモジュールを実装した。一般に、要約には深い意味処理と多くの背景知識が必要である。しかし、これまでの研究の多くは表層的な手がかりやドキュメントの持つ何らかのスタイルに関するヒューリスティックスを用いるものであった。たとえば、文の重要性を判断するのに使われる特徴素としては、文の長さ、キーワードの出現回数、時制、文のタイプ(たとえば、事実(...である)、推測(...だろう)、主張(...べきだ)など)、修辞関係(たとえば、理由、例示など)、文頭からの位置、文末からの位置などがある。これらの大部分は、特に深い処理を行わなくても、ある程度抽出できるものであり、それゆえ、これに基づく処理は非常にロバストである。また、これまでの要約システムは、上記の特徴に基づいて計算された文の重要性の高いものを順に選択し、元の文章における文の出現順に並べるという手法を用いているものが多い。確かに、これらは現在の技術をもって実用的なシステムを作ることに成功している。しかしながら、どれほどのヒューリスティックスをもってしても、要約の品質の向上はすぐに限界にきてしまうだろう。いずれにしても、内容に基づく処理は必須である。
ここでは、前述のGDAタグから得られる、文の構成要素の重要度(活性値)を用いた要約を提案する。基本となるアルゴリズムは、一般に活性拡散と呼ばれている。この手法は、ドキュメントのドメインやスタイルに関するヒューリスティックスを用いていないため、GDAタグの付いたテキストならどのようなドキュメントにも適用可能であり、また、文より細かい単位で重要度を計算しているので、一文をさらに短くすることも可能である。
言語的アノテーションを持つドキュメントは、ドキュメント内ネットワークと呼ばれる構造を自然に作り出すことができる。このネットワークのノードは、GDA(XML)のエレメントに当たり、リンクは統語的あるいは意味的関係を表している。ネットワークは統語解析木(文の構成要素の階層的関係)、照応・参照関係、章・節・項・段落階層、そして修辞関係によって構成されている。
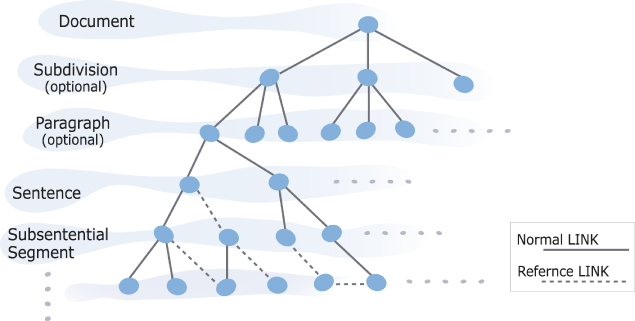
図12: ドキュメント内ネットワーク
活性拡散はドキュメント内ネットワークの各ノードの重要性の度合い(活性値と呼ばれる)を計算するために用いられる。これは反復計算であり、ネットワークのすべてのノードの活性値を、直接のリンクで結合するノードの活性値から計算するのである。すべてのノードの活性値が一度に更新され(これを1サイクルと言う)、すべてのノードの活性値が直前のサイクルからどのくらい変化したかを計算して、その平均値がある閾値を下回る場合(このとき収束したと言う)は、計算を終了する。
活性拡散が収束したときに、より高い活性値を持つノードがより高い重要性を持つとして、重要度の順位が決定される。
このとき要約のアルゴリズムは以下のようになる。
-
要素とその参照要素の間、または、統語的要素とその主辞(下位要素うち、他の要素に依存しない中心となるもの)の間で重要度が等しくなり、それ以外では重要度が減衰するように重要度の計算(活性拡散)を実行する。
-
重要度の拡散演算が終了した時点で、平均重要度の大きい順に文を選択する。
-
選択された文で削除すると意味が通らない必須要素を抽出する。必須要素になりうるのは、以下のものとする。
-
文の必須要素をつなげて文の骨格を生成し、要約に加える。照応表現(いわゆるゼロ照応も含む)の先行詞が要約に含まれない場合は照応表現を先行詞で置き換える。
-
要約が指定された分量に達したときは終了する。まだ余裕がある場合は、次に活性値の高い文と省略した要素の活性値を比較して、高い方を要約に加える。
ユーザーは、要約のサイズを容易に変更することができる。これはトランスコーディングプロキシに変更したプリファレンスを送信することによって実行される。プリファレンスの更新については以下で述べる。
また、要約はそれを行う人間の知識によっても変わってくるが、それを読む人間の興味などによっても変わってくるべきであろう。ここでの、GDAタグを用いた要約は、内容に基づく一般的な手法によるものなので、個人の興味や嗜好のようなパーソナライゼーションのための情報を取り入れれば、その個人に特化した要約を行うことができる。つまり、読み手が知りたい内容を含むように要約を生成することができるのである。そのための手段として、たとえば、要約を開始する時点で、任意のキーワードを入力できる。要約モジュールは、キーワードと関連するドキュメント中の単語を重要語として処理する。活性拡散を実行するときに、重要語を含むノードの初期活性値を高くすることで他のノードと区別される。
図は、要約されたドキュメントの例を示している。これは、図に示されたWebドキュメントを要約したものである。
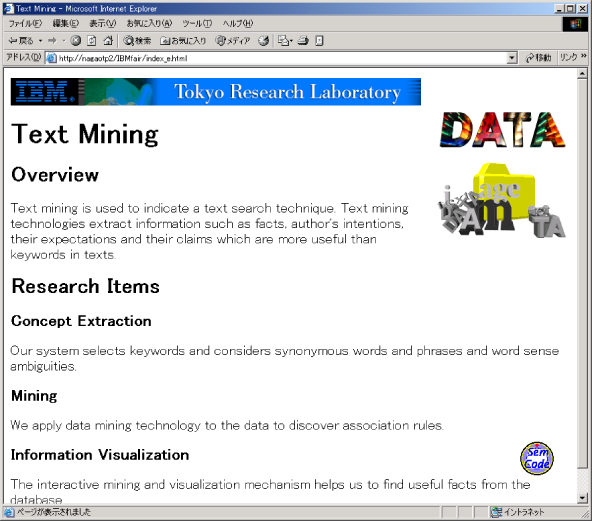
図13: 要約されたドキュメント
このほか、テキスト文書のトランスコーディングの例としては翻訳が挙げられる。現在、英語から日本語、および英語からヨーロッパ言語(ドイツ語、フランス語、スペイン語、イタリア語)の自動翻訳をトランスコーディングとして実現している。翻訳は各言語専用の翻訳エンジンによって実行される。トランスコーダは、原コンテンツが何語で書かれているかをアノテーションによって判断し、ユーザーが何語を要求しているかをプリファレンスで知った上で、適切な翻訳エンジンを選択する。英日翻訳に関しては、日本アイ・ビー・エムが開発した翻訳エンジンを、アノテーションを考慮して翻訳するように拡張した。翻訳で用いる言語的アノテーションはIBM東京基礎研究所が開発したLAL (Linguistic Annotation Language)に基づいている。翻訳用のトランスコーダは、アノテーションデータをGDAからLALへ自動的に変換してから翻訳エンジンに渡している。図は、図のドキュメントの英日翻訳の結果を示している。
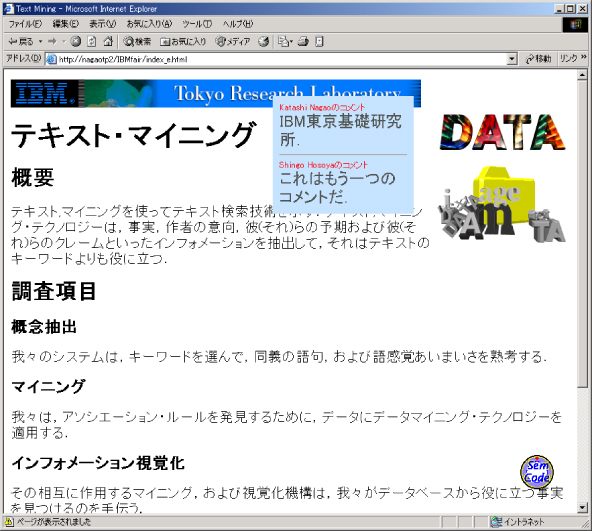
図14: 翻訳されたドキュメント
2.3.3 イメージトランスコーディング
画像のトランスコーディングは、ユーザーが使用する機器の表示能力などに合わせて、コンテンツに含まれる画像のサイズや解像度を変換する処理である。ただし、変換された画像は必ずもとの画像へのリンクを含むようにしてあるため、オリジナルのサイズや解像度で見ることが可能な状態のときは、単にその画像をクリックすることによって、もとの画像を見ることができる。
図はオリジナルのイメージを1/2に縮小した例である。この図の右下のウィンドウはプリファレンスに含まれるパラメータを設定するためのもので、イメージの縮小率の他に、要約の分量やアノテータの指定なども設定できる。このウィンドウは、ユーザーが右下角の丸いアイコン(このアイコンはトランスコーディングプロキシが自動的に挿入する)をダブルクリックすることで表示される。このウィンドウで設定したプリファレンスは、トランスコーディングプロキシに送信後、ユーザーIDと共に保存され、それ以降のトランスコーディングにおいても利用される。
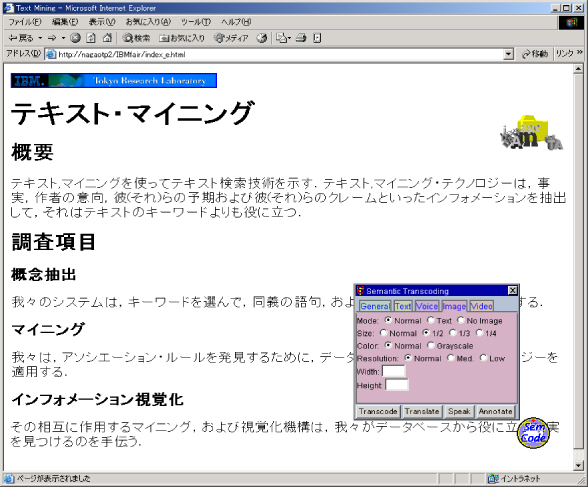
図15: イメージトランスコーディングとプリファレンス設定ウィンドウ
イメージトランスコーディングはテキストトランスコーディングの要約と併用して、コンテンツの表示面積を縮小してユーザーの用いるデバイスの画面サイズに適合させることができる。
2.3.4 音声トランスコーディング
音声トランスコーディングとは、コンテンツを音声化するトランスコーディングである。テキストコンテンツの音声化は、厳密にはテキストトランスコーディングの一種であるが、音声データの生成とコンテンツと音声データの関連付けの部分を含めて、音声トランスコーディングとする。テキストトランスコーディングと同様に、コンテンツに関連付けられた言語的アノテーションを用いる。これは、テキストコンテンツをまず音声合成に適した形式に変換するために用いられる。音声合成に適したコンテンツの形式の一つに、SSML (Speech Synthesis Markup Language)がある。アノテーションが有効な例には、人名や地名などの固有名詞や専門用語に関するものがある。言語的アノテーションの一部である語レベルのアノテーションは、語の意味だけでなく読み方の情報を得るためにも必要である。
テキストコンテンツを音声化するトランスコーディングには、2種類のやり方が考えられる。一つはトランスコーディングプロキシが、MP3 (MPEG-1 Audio Layer 3)などによって表現された音声データを作成して配信するやり方で、たとえば、携帯電話やPDAなど、クライアントが音声合成機能を持たない場合に有効である。もう一つの音声トランスコーディングは、クライアントが音声合成システムを利用していることを前提に、音声合成に適した形式に加工して配信するやり方である。前者は後者によって生成されたテキストデータをプロキシから直接利用可能な音声合成エンジンで音声合成を行った結果を配信する場合と考えられるので、どちらのやり方もほぼ同じプロセスを必要とする。
また、たとえば、HTMLドキュメントが``alt''属性を持たないIMGタグ(つまり、説明文のないイメージを埋め込むタグ)を含んでいて、そのイメージにコメントアノテーションが付与されている場合、音声トランスコーディングは、コメント情報を含めて音声合成に適したテキストコンテンツを生成する。また、固有名詞など辞書にない語を正しく読むために、言語的アノテーションに語の読み情報が含まれている場合は、それも含めて生成する。さらに、読み上げ時に適切な場所にポーズを置くために、言語的アノテーションによって得られた、フレーズの切れ目に関する情報も含めることができる。
図は、音声トランスコーディングによって生成されたHTMLドキュメントを示している。このドキュメントはフレームによって分割されており、上部のフレームにはオーディオプレイヤが埋め込まれている。ユーザーがプレイヤのプレイボタンをクリックすると、合成された音声が再生され、該当するコンテンツの部分がオレンジ色の背景でハイライトされるようになっている。
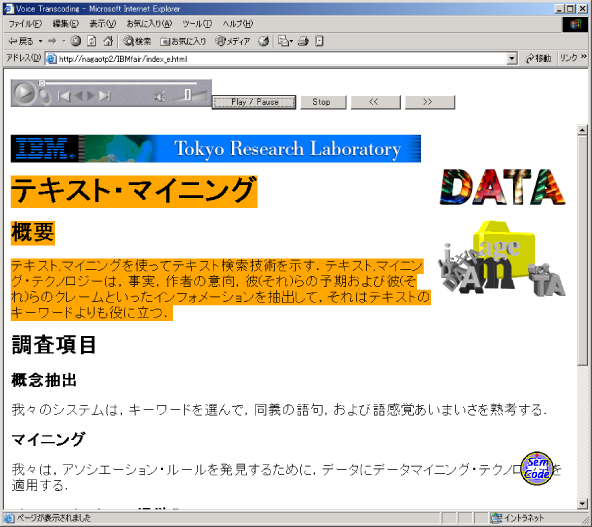
図16: 音声トランスコーディング
2.3.5 マルチメディアトランスコーディング
マルチメディアトランスコーディングはマルチメディアアノテーションを利用したトランスコーディングである。マルチメディアアノテーションは、前述のように、ビデオに含まれる音声のトランスクリプト(書き起こしテキスト)に言語的アノテーションを施し、カット(シーン切り替え)のタイムスタンプ、シーンごとのキーフレーム、映像内オブジェクトの名前とその出現位置(時間と領域座標)などを含めたものである。マルチメディアトランスコーディングの具体例には、ビデオの要約や翻訳が含まれる。また、マルチメディアトランスコーディングの一つの機能として、ビデオドキュメントの生成がある。ビデオドキュメントはアノテーション付きのビデオコンテンツをインタラクティブなHTMLドキュメントに変換して、ビデオの視聴以外にキーフレームおよびトランスクリプトの閲覧を可能にしたものである。
映像コンテンツの要約はテキストの要約と同様に盛んに研究が進められている。古くはCarnegie Mellon Universityが開発したInformediaがある。これは、映像コンテンツに含まれるさまざまな属性を自動抽出して、より重要な部分を選択する。たとえば、画面上に現れる文字情報や人の顔、シーンの変わり目、クローズド・キャプションと呼ばれる字幕情報などを使う。あらかじめリストアップされた重要な固有名詞の出現頻度や、キーワードの重要度を計算し、そのキーワードの現れるシーンをつなぎ合わせて要約とする。また、IBMアルマデン研究所のCueVideoはビデオのキーフレームを並べて表示して、ユーザーがどれかを選択すると、その部分のビデオを再生することによって、人間がビデオ全体を見る手間を減らしている。また、音声のみを再生して、画像は静止画をシーンが変わるごとに変化させることによって、ダウンロードする情報の容量を少なくする工夫もなされている。このとき音声の再生スピードを変化させることによって、早口にしたり、ゆっくり聞き取りやすくすることもできる。CueVideoはディスタンスラーニングと呼ばれる遠隔教育におけるビデオの利用に焦点を当てて研究が進められており、教育に使われるビデオを効果的に見せるためのさまざまな手段が開発されている。たとえば、ある講義のビデオとその講義の資料(PowerPointなどのスライドファイル)を自動的にリンクして、再生時に連動させることもできる。また、ビデオのシーンを検索するのに、任意の単語やフレーズを入力すると、音声認識を利用してその言葉を含む部分を抽出してリストアップし、そのうちのどれかを選択するとその部分を再生する、という通常のテキスト検索と同様のことがビデオに対して行える。同じくIBMワトソン研究所の開発したVideoZoomは、ビデオの画像の解像度を動的に変化させ、荒い画像のビデオから徐々に鮮明にしていったり、荒い画像のビデオをまずダウンロードして、細かく見たいところのみについて差分の情報を追加していくことができる。これも、ネットワークやデバイスの制約に依存して、ビデオコンテンツを加工するトランスコーディングの一種と言える。これらのビデオトランスコーディングはアノテーションを用いないので、一度実装すれば利用するのは簡単であるが、ビデオをさまざまな形で再利用するためには問題がある。われわれはビデオが今後重要な情報ソースになることを確信しているので、要約やフィルタリングに限定されない、さまざまな再利用を可能にする枠組みを用意しておきたいと考えている。また、将来MPEG-7のようなアノテーションの標準的フレームワークが確立した場合にも、われわれの仕組みは容易にコンバートして利用可能である。
ビデオコンテンツの要約と翻訳は、まず図に示されるようなビデオドキュメントを生成することから始まる。トランスコーダは、アノテーションデータから必要な情報を取り出し、それに基づいてビデオドキュメントを生成する。ビデオドキュメントは複数のフレームを含むHTMLドキュメントで、左フレームにビデオプレイヤとその下に字幕を表示するウィンドウ、中央にタイムバーと呼ばれるビデオの再生中にアイコンで時間を表示するものがあり、右フレームにシーンのキーフレームとそのシーン内の音声をテキスト化したトランスクリプトが表示される。字幕ウィンドウには、トランスクリプトの一部をビデオの再生に同期して表示する。キーフレームのイメージは対応するビデオシーンへのリンクを含んでおり、ユーザーがイメージをクリックすると、該当するシーンが左フレームのビデオプレイヤで再生される。トランスクリプトは言語的アノテーションを含んでいる。このドキュメントは後述する要約・翻訳モジュールに利用される。
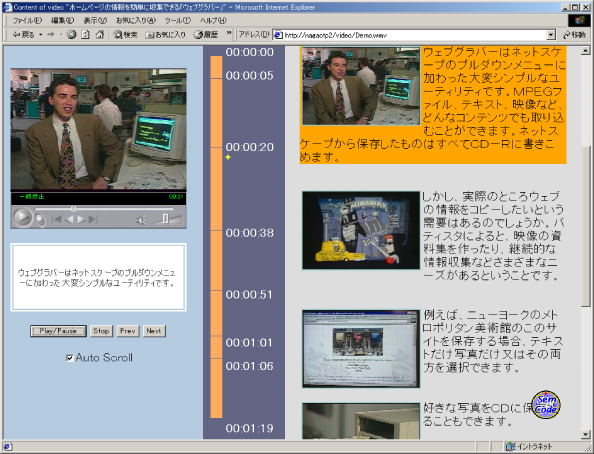
図17: ビデオドキュメント
この変換処理は、クライアントのデバイスがビデオを再生することができない場合にも有効である。この場合、トランスコーダは、キーフレームとトランスクリプトのみを含む、簡略化されたビデオドキュメントを生成する。さらに、このドキュメントのイメージサイズを変更したり、テキストを要約して、さらにコンパクトなドキュメントにすることもできる。
ビデオの要約は、まずビデオのトランスクリプトを要約して、その要約に対応するビデオシーンを抽出することによって行われる。トランスクリプトの要約は、テキストトランスコーダによって行われる。やはり、言語的アノテーションによって構成されるネットワークにおいて活性拡散を行い、ノードの活性値からテキスト要素の重要度を判定している。
トランスクリプトの要約が終了したら、その要約に対応する、重要と思われるビデオシーンを抽出することによって、ビデオの要約を実現する。重要シーンの抽出は、アノテーションに含まれるタイムスタンプの情報を手がかりに自動的に行う。要約の結果として、キーフレームと要約されたトランスクリプトを含むビデオドキュメントが生成される。キーフレームのうち、重要シーンに対応するものは通常サイズで、それ以外のシーンに対応するものはより小さいサイズで表示される。
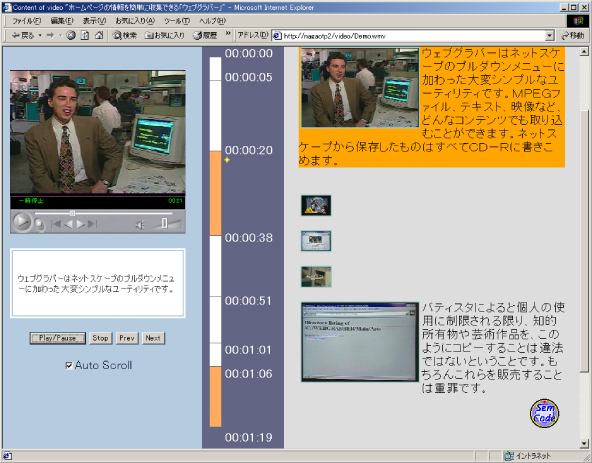
図18: 要約されたビデオドキュメント
この図の中央にある垂直のタイムバー上に色付きの領域があり、この領域が要約されたビデオに含まれているかどうかを示している。この領域をクリックすると該当するビデオシーンが再生される。右フレームに表示されているキーフレームのイメージをクリックしても同様である。このキーフレーム上で適当な領域をマウスでドラッグすると、その領域に含まれるフレーム内オブジェクトの情報がポップアップして表示される。テキスト要約と同様に、ビデオ要約もプリファレンスデータを変更することで、インタラクティブにカスタマイズすることができる。すなわち、任意のキーワードを入れたり、要約のサイズを変更することができる。キーワードは、トランスクリプトと照合され、要素の重要度が変化し、キーワードがマッチしたシーンを要約に含むようにビデオドキュメントが更新される。
ビデオ翻訳の一つの形態は、次のように実現される。まず、トランスクリプトをテキストトランスコーダを用いて、ユーザーが要求する言語に翻訳する。次に、翻訳されたトランスクリプトから字幕を生成する。変更されたビデオドキュメントで、ビデオを再生すると、翻訳された字幕がビデオの再生と同期してビデオプレイヤの直下のウィンドウに表示される。もう一つのビデオ翻訳の形態では、トランスクリプトの翻訳結果をさらに音声化して、ビデオ再生と同期して、該当する部分の音声データを再生するものである。これによって、多言語化されたビデオコンテンツを動的に生成して配信することができる。また、フレーム内オブジェクトに付与されたコメントも、同時に同じ言語に翻訳され、ポップアップ表示される。
複数の言語による音声トラックを含むビデオの場合は、マルチメディアアノテーションがそれらすべての音声トラックのトランスクリプトを含んでいるので、当然、ユーザーが選択した言語がそのどれかに該当した場合は、トランスコーダはわざわざ翻訳を行わずに、あらかじめ用意されたトランスクリプトと音声トラックを含むビデオドキュメントを生成する。
3 おわりに
アノテーションを作成し、利用する一連のメカニズムについて述べた。それは、言語的アノテーション、コメントアノテーション、マルチメディアアノテーションを作成するオーサリングツール、それらアノテーションデータを管理し配信するアノテーションサーバー、アノテーションデータをコンテンツのトランスコーディングに用いるトランスコーディングプロキシから構成される。この場合のトランスコーディングはコンテンツの意味を考慮し、ユーザーの好みを反映させたものであり、セマンティック・トランスコーディングと呼ばれる。
セマンティック・トランスコーディングにとって、自然言語処理技術は重要な役割を果たす。われわれの開発したアノテーションエディタは、できるだけ人間に負担をかけないように、最新の自然言語処理技術を導入し、自動処理の結果を人間がインタラクティブに修正してアノテーションデータを作成できるようにしている。
また、マルチメディアアノテーションのためのツールにおいて、音声認識によって多言語のトランスクリプトを生成する機能は重要であり、それによってマルチメディアコンテンツの高度な利用が実現される。このツールは、ビデオのシーンやフレーム内オブジェクトの情報を半自動的に抽出し、アノテーションデータの作成を支援している。
アノテーションに基づくマルチメディアトランスコーディングの例として、ビデオコンテンツからビデオドキュメントを生成する仕組みを紹介した。これは、ビデオとイメージやテキストを含みインタラクティブにビデオ情報を閲覧できるコンテンツである。さらに、このドキュメントに基づいて、ビデオ要約や翻訳を実現することができる。
この技術は、コンテンツに付与されたコメント情報の共有や、ユーザーの視聴デバイスの特性に合わせた適応を実現するためにも用いられる。アノテーションは、従来のデジタルコンテンツを知的コンテンツとするための最良の手段である。それは、人間が、自分自身あるいは他者の創り出したコンテンツを再評価し、価値あるものとそうでないものを見分ける良い機会が与えられるからである。コンテンツを人類共有の財産とするためには、やはりそのコンテンツを責任を持って吟味する人間が必要であろう。アノテーションとは、まさにそのような責任の所在をより明確にし、内容にさらなる価値を与えていく仕組みなのである。そして、アノテーションは人間と機械の構成するシステム全体が賢くなっていくための仕組みである。この場合の機械とは、あらかじめプログラムされた手続きを文脈に応じて選択的に実行する自律的なシステム、すなわちエージェントである。エージェントをある程度以上に複雑にする代わりに、コンテンツの方をアノテーションによって、人間がエージェントにとって都合の良い形に変えていければ、人間とエージェントとコンテンツが構成するシステム全体をより高度にすることができる。つまり、コンテンツそのものがより理解しやすくなれば、それを扱うエージェントが可能なタスクもより高度になるだろう。エージェントはアノテーションの付与されたコンテンツを対象にすることによって、単純な手続きを繰り返すだけで、より高度なサービスを提供できる。これは、見かけ上、エージェントが賢くなったように見えるが、実際はコンテンツそのものが(多くの人間の不断の努力によって)賢くなっているのである。
今後の課題には、もちろん、アノテーションの作成コストを下げていくことが含まれるが、その他に、アノテーションに基づく、Webコンテンツからの知識発見を実現することがある。近い将来には、Web上の情報検索には、既存の検索エンジンから、複数のコンテンツから新たな知識を得てその結果を要約して出力するような、いわば知識発見エンジンを使うようになるだろう。それによって、ハイパーリンクを集めた大量のリストの代わりに、短時間で容易に理解できるように要約されたコンテンツを読むことができるようになると思われる。さらにもう一つの課題は、映像や音声といったマルチメディア・データを含むデジタルコンテンツの効率的な検索である。この場合の検索の質問には単なるキーワードではなく、音声あるいはテキストの自然言語文を用いる。こうした課題を克服することは、将来やってくる情報の洪水から自分自身を守る最良の方法になるだろう。