
デジタルコンテンツの部分関連付けと文脈情報の可視化に基づく論文執筆支援に関する研究
概要
1 はじめに
近年の計算機及びインターネット関連技術の発達により、文書・画像・音楽・映像などの多種多様なデジタルコンテンツを身近なものとして扱うことが可能となった。記録のためにメモやノートなどを電子的にテキストファイルとして保存したり、デジタルカメラやiPadなどの携帯端末を用いて画像・音楽・映像などを記録することが現在日常的に行われている。また、Web技術の発達により、単にコンテンツを作成するだけではなく、TwitterやFacebookといったSNS(Social Networking Service)など、CGM(Consumer Generated Media)サービスを用いて容易にコンテンツを発信し、他者と共有することが可能となり、コンテンツの増加・多様化が進んでいる。近年では、クラウドコンピューティングという概念も普及してきており、様々なデバイスから容易にコンテンツを作成・管理することも可能となっている。実際に普及しているクラウドサービスとしては、あらゆるコンテンツが記録可能なEvernote[http://evernote.com]、ストレージサービスであるDropBox[https://www.dropbox.com/]などが挙げられる。
研究活動においても、コンテンツの記録・作成は頻繁に行われている。具体的には、調査のための論文などの文献を収閲覧・収集してアーカイブし、後に見返すためにインデックス付けして管理する行為、研究内容の整理のためのノートの作成する行為、成果報告のための発表資料の作成する行為などが例として挙げられる。我々は、このような研究活動におけるコンテンツの作成・閲覧・記録を支援するための研究を行ってきた。林らは、論文閲覧時における文章に対するマーキングとそれらの論文執筆時の検索を実現している[1]。石戸谷らは、複数人で行うミーティングを行う際に、各参加者が作成した研究ノートの一部を電子ホワイトボードに送信することで新しい議事録コンテンツの作成を実現している[2]。また、土田らはプレゼンテーションスライドを用いた発表において、発表中の映像と発言を議論構造と共に記録する仕組みを実現している[3]。また、研究以外にも、学術的な活動を支援するためのWebサービスも多く存在している。Zotero[http://www.zotero.org/]は、ブラウザ拡張プラグインとして動作し、Web上にあるコンテンツを整理して保存することが可能であり、またWeb上からコンテンツに関するメタ情報をある程度自動で抽出することで検索を容易にしている。Pliny[http://pliny.cch.kcl.ac.uk/index.html]やEvernoteでは、Webページの一部分をクリップしてノートを作成・管理することが可能である。SlideShare[http://www.slideshare.net/]では、プレゼンテーションスライドをWeb上での閲覧・共有を実現し、多くのユーザからスライドに対するフィードバックを獲得することができる。
このように、研究活動において作成・閲覧されるコンテンツは、論文・研究ノート・発表資料・議事録・Webサイトなど多種多様であり、コンテンツの量は日々増加していると考えられる。
一方で、研究者は、それらのコンテンツを論文として1つの文章に整理してまとめる必要がある。しかし、研究成果が出て論文を執筆し始めるまでに、長期にわたる研究活動を行っていると考えられるため、コンテンツの量は膨大になっていると考えられる。故に、それらの膨大なコンテンツの中から論文に必要な部分だけを探し出すことは容易ではない。数年前に調査した論文や作成したノートといったコンテンツは特に困難であり、それらを作成・閲覧したこと自体を忘れてしまっていることも少なくない。
また、既存の研究やWebサービスにおいては、それぞれのシステムの中でコンテンツを検索することは可能ではあるが、検索できる情報はそのシステムの中で閉じている場合が多く、多種多様なコンテンツを論文執筆時に横断的に検索することは困難であると考えられる。
また、論文執筆に慣れていない学生などにとっては、そもそも何を書くべきか、論文に必要な情報は何なのかということすら頭の中で整理できない場合も考えられる。論文のような論理的な文章を執筆する経験に乏しい学生は、章・節構成のような大まかな構成を考えることは可能でも、実際に文章を書き始めてみると、何を書いてよいのか分からないといったことや、必要な情報が整理できていないまま、文章を書き進めてしまい、他者に指摘されるまで、論理的矛盾に気付くことができず、後で大幅な修正をしなければならない可能性も考えられる。
そこで、本研究では、コンテンツの効率的な検索に加えて、著者自身に、論文に何を書くべきか、何が足りないかを気付かせるための仕組みを実現することで論文執筆を支援する。おおまかなアプローチの手順は以下のようになる。
- 論文執筆時のコンテンツの検索支援
- 論文アウトラインへのコンテンツの関連付け
- コンテンツ作成時の文脈情報の提示
論文アウトラインとは、文書における章・節・項構成に加えて段落構成を含んでいる。また、ここで述べる文脈情報とは、あるコンテンツを作成・閲覧するときに、参照・引用された異なるコンテンツの情報を指す。この3つの仕組みについて順に説明する。
(1)の論文執筆時のコンテンツ検索支援の実現のために、コンテンツに対するアノテーションを利用する。アノテーションとは、コンテンツの全体あるいはその部分に対して関連付けられるメタ情報であり、 アノテーションを獲得することで、コンテンツの管理・検索などの応用を実現する研究が盛んに行われている[4][5]。本研究では、研究活動において自然に行われるコンテンツの作成・閲覧・引用行為に基づくアノテーションを主に取り扱う。これらのアノテーションは、各コンテンツの作成・閲覧者がアノテーションを作成しているという意識を持たずに暗黙的に収集されることが特徴である。これらのアノテーションの収集は前述した我々の既存研究の仕組みである論文閲覧・ノート作成・議事録作成システムを利用することで実現する。具体的なアノテーションの例としては、論文閲覧時における文章や画像へのタグやコメントの付与、Webサイトへのブックマーク、会議における発言に対するマーキング、論文や画像などのノートへの参照・引用などが挙げられる。我々は、特に参照・引用行為に着目し、(3)のコンテンツ作成時の文脈情報として参照・引用情報を提示する。
我々は、過去の発表資料の一部をコピーして新しい発表資料を作成したり、同じ画像ファイルを複数の論文に流用したりするように、日常的にコンテンツの参照・引用を行っている。このことをもっとも象徴しているのが、コピーアンドペーストと呼ばれるコンピュータ上の編集操作である。コピーアンドペーストは、テキストだけでなく、ファイルそのものや画像、文書のレイアウト情報などをクリップボードと呼ばれるデータ領域にコピーし、異なる箇所へその内容を複製する機能であり、コンテンツの引用を容易に行うことができる。
コピーアンドペーストの問題点は、使用時に引用元および引用先の関係情報が記録されないことである.結果として、時間が経過するにつれてペーストされた情報が、どこからコピーされたものなのかが分からなくなってしまい、コンテンツ作成に至るまでの文脈情報が失われてしまう(そもそもそれがペーストされた情報なのかどうかも分からなくなる可能性もある)。我々の仕組みでは、引用元および引用先の関係情報を記録しながら、コピーアンドペーストのようにコンテンツを引用しながら新たなコンテンツを生み出すことを実現する。
前述のアノテーションを適切に行うための必要な要素として、部分要素の定義について触れておく。部分要素とは、論文や研究ノートなどのテキスト文書であれば、章や段落、文章といったレベルの要素を指し、画像や映像であれば特定の矩形範囲や時間区間を指す。我々は、コンテンツの部分要素に対し、固有のURI(Uniform Resource Identifier)を割り当てることにより、それらの要素に対するアノテーションの付与を可能にしている。部分要素に対するアノテーションの具体例としては、論文のある特定の文章や図表の一部分に対するマーキング、論文の一部分や映像の部分である映像シーンを引用してノートを作成するといったことが挙げられる。特に、論文や映像といった情報量の多いコンテンツに対してアノテーションを行う場合は、このような部分要素に対するアノテーションは非常に有効であると考えられる。
このように、各コンテンツ作成・閲覧システムを通して、自動的に収集された部分要素に対するアノテーションを論文執筆時に活用する。本研究では、コンテンツと共にそれらのアノテーションを文章作成時に検索可能としたエディタ(TDEditor)を開発した。アノテーションに基づいた検索の例としては、あらかじめ付与されたタグに基づく検索、コンテンツの作成・閲覧時期に基づいた分類、参照・引用関係に基づいた関連検索などが挙げられる。アノテーションによりコンテンツに対して付与されるメタ情報は、著者及びその研究グループのユーザが付与したものであるため、画像処理や自然言語処理などを用いてコンテンツ内部の情報を機械的に解析するだけでは獲得することが困難であるものも含まれる。故に、アノテーションを用いた検索では精度の高い検索が期待できる。
ここで論文を執筆するために検索したコンテンツ(の部分要素)を、さらに、論文アウトラインへの関連付ける仕組み(2)を実現する。論文は、一般的に大まかな章・節・項といったアウトラインを練ってから始められる。その際に、そのアウトラインに対して、頭の中で、書くべき内容について考える。その際に、過去に著者が記録したノートや論文など、そのアウトラインの中で、参照・引用すべきコンテンツについて、頭の中で整理する。このように、論文アウトラインとコンテンツを関連付ける作業は、通常、頭の中で行われている作業であるといえる。
TDEditorでは、この頭の中で行う作業をシステムの中で実現し、論文アウトラインに対して、参照・引用するコンテンツを可視化する仕組みを実現する。システムによってコンテンツが可視化されることで、論文執筆に不慣れな学生であっても、今書こうとしている論文に必要な情報の有無を確認することが容易となる。この論文アウトラインへの関連付けに関しては、執筆にどのような影響を与えるのか被験者を用いて評価実験を行った。
一方、人手による関連付けでは、必要となる情報を網羅的に扱うことができるとは限らない。たとえ、論文を執筆するために必要な情報を含んだコンテンツが存在しても、論文執筆までの間にあまりにも年月が経ちすぎたために、存在そのものが忘れられてしまったコンテンツを探し出し、関連付けることは困難である。また、完成に必要な論文の情報量を考慮すると、関連付けることのできるコンテンツ全てを人手で探し出すことは非常にコストがかかる。そこで、論文アウトラインに対してコンテンツが1つでも関連付けられた際に、(3)の機能である文脈情報の提示を行う。前述したように文脈情報は、コンテンツ作成時に収集されたコンテンツ間の参照・引用情報を含んでおり、この情報は関連するコンテンツを探し出す際に有用である可能性が高い。すなわち、最初に論文アウトラインに関連付けたコンテンツを起点として、文脈情報を辿ることで、過去のコンテンツを探すことが可能となる。例えば、アウトラインに対して関連付けた研究ノートから、そのノートを作成する際に参照した論文部分を提示し、さらに、その論文の引用・被引用関係を提示することで、ノートに関する内容の文献を横断的に検索することが可能となると考えられる。
TDEditorでは、これらの3つの仕組みに加え、関連付けたコンテンツ(の部分要素)に対して、執筆中に容易にアクセスし、必要に応じてコンテンツを論文の中に引用することができる仕組みを実現している。執筆中に参照・引用可能なコンテンツを常に提示することで、効率的な論文執筆を支援する。
また、TDEditorの目的の一つに、文書作成を支援しつつ暗黙的にアノテーションを収集することがある。論文執筆の過程において、収集される関連付け情報、及び引用情報が、他の既存の研究支援システムに利用されることを想定している。論文は研究の集大成であり、既存研究の中において収集される参照・引用関係と比較するとより多くの情報が集まることを期待している。
本研究では、以上のような、研究活動の中で収集されるコンテンツのアノテーションに基づく検索、論文アウトラインに対するコンテンツの部分関連付け、アノテーションに含まれる参照・引用関係に基づいたコンテンツの提示の3つの仕組みについて述べる。また、論文作成において収集された参照・引用関係を用いた高度な検索・応用に関しても述べる。
以下に、本論文の構成を示す。第2章では、我々の研究室で実現されてきた研究活動における多様なコンテンツを記録・閲覧する仕組みとその中での文脈情報を獲得するための仕組みについて述べる。第3章では、本研究で拡張した論文閲覧支援ツールであるTDAnnotatorについて述べる。第4章では、TDEditorとその論文執筆支援の手法について述べる。第5章では、TDEditorを用いて行った論文アウトラインへのコンテンツの関連付けに関する評価について述べる。第6章では、システム全体の中で収集される参照・引用関係に基づく応用について述べる。第7章で本研究と関連する研究について述べ、第8章で本論文のまとめと今後の課題について述べる。
2 研究活動におけるコンテンツの記録と文脈情報の獲得
本章では、論文執筆のプロセスについて述べた後に、本研究で我々の研究室で行われてきた研究活動支援システムについて述べる。
本研究では、論文執筆を支援することためのシステムの構築を目的としている。その第一歩として、文書執筆のプロセスについて述べる。基本的な文章作成プロセスのモデルであるHunter[6]のモデルでは、文章作成のプロセスを、情報を集め、書く内容やアイディアを思いつく「創作」(generating) プロセス、必要な内容を選択し、それを線形、または階層的にまとめあげる「組織化」(organizing) プロセス、計画に従って実際に文章を書く「作文」(composing) プロセス、必要に応じて挿入、削除、順番の変更、置き換え、計画の変更を行う「推敲」(revising)プロセス、という互いに関連し合った4 つの基本プロセスで捉えている。このモデルを研究活動における論文執筆に適用する。
論文執筆における創作プロセスとは、日々の研究活動である。研究活動には、論文のサーベイ、研究ノートの作成やゼミ発表のための研究資料の作成などのコンテンツの作成・閲覧行為が含まれている。
組織化プロセスは、創作プロセスにおいて収集されたコンテンツに含まれる断片的な情報を組織化していく。具体的には、論文の章・節・項といった論文アウトラインを木構造で表現する行為に当たる。一般的に、組織化プロセスを支援する手法としては、木構造表現の他に二次元空間を用いる手法が考えられる。木構造表現はトップダウン、二次元空間はボトムアップの文章作成に適しているが、論文を対象とする場合は、執筆の初期段階において著者自身である程度構成を決定できると考えられるため、木構造表現が適用される。
作文プロセスでは、組織化プロセスにおいて決定された論文アウトラインの文書化を行う。論文執筆の作文プロセスの中では、創作プロセスの中で記録された論文やノートなどのコンテンツを参照する行為や、参考文献として引用する行為が含まれる。特に執筆に不慣れな学生は、何も参照せずに、論文を完成させることは困難であるため、作文プロセスの中でのコンテンツの参照・引用は頻繁に行われる行為と言える。
論文執筆における推敲プロセスは、筆者単独で考え、修正するのではなく、指導者や共著者等にコメントをもらう行為が含まれる。多様な視点から草稿を見直すことで、論文のクオリティを向上させることが可能となる。
創作プロセスに関する支援の仕組みは、論文検索支援[7]、論文閲覧支援[8][1]、ノート作成支援[9][10]、ミーティングやゼミなどの会議支援[2][3]など、非常に多岐にわたり行われている。組織化プロセスにおいては、大野らが2次元表現と木構造表現を適宜切り替えながら文書の論理構造を組み立てるためツールを実現している[11]。作文プロセスに関する研究では、林らが論文閲覧時のマーキングの情報を用いた引用支援の仕組みや執筆中の専門用語の検索の仕組みを実現している[1]。推敲プロセスにおいては、自然言語処理に基づいた校正・推敲支援ツール[11]や文書に対するフィードバックコメントの自動生成[12]といった仕組みがある。また、近年では、Google Docs[http://drive.google.com]のような、複数人で同一文書に対して同時に編集・推敲が行えるようなWebサービスも普及している。
本研究では、これらのプロセスのうち、主に組織化プロセスである論文アウトラインの作成を支援する。論文アウトラインの作成は、前述したように、創作プロセスである研究活動で収集されたコンテンツを整理し、木構造にすることである。しかし、研究活動で収集されるコンテンツに含まれる情報量は、論文執筆に至るまでの時間を考慮すると非常に膨大なものとなるため、論文執筆に不慣れな学生の場合は容易ではない。論文執筆に必要な情報を整理できないまま、著者が論文アウトラインを作成してしまった場合、他人に指摘されるか、自身で作文するまでアウトラインの論理的な間違いや執筆に必要な情報の不足に気付くことができない可能性がある。
本研究では、まず、論文執筆に必要な情報を著者に整理させるために、論文アウトライン作成時に、著者が記録してきたコンテンツの検索を実現する。コンテンツの検索を可能にするために、本研究では、研究活動におけるコンテンツを可能な限り記録する。
2.2 研究活動におけるコンテンツの記録
論文執筆に必要なコンテンツは、著者の研究内容に大きく依存するため、著者ごとに適した検索を実現する必要がある。そこで、本研究では、研究活動において作成されるコンテンツを可能な限り記録し、さらに、研究活動の中で検索に有用となるメタ情報を収集する仕組みを実現する。そのために、我々の研究室で開発されてきた研究活動支援のためのツール及びシステムを活用する。
執筆に必要なコンテンツは、著者の研究内容に大きく依存するため、著者ごとに適した検索を実現する必要がある。そこで、本研究では、研究活動において作成されるコンテンツを可能な限り記録し、さらに、研究活動の中で検索に有用となるメタ情報を収集する仕組みを実現する。そのために、我々の研究室で開発されてきた研究活動支援のためのツール及びシステムを活用する。
本研究で検索対象となる研究活動の中で記録されるコンテンツは、論文・研究ノート・画像・映像・論文・議事録・Webドキュメントである。本節では、我々の研究室で実際に運用しているこれらのコンテンツを記録する仕組みと、これらの仕組みの中で、コンテンツの作成・閲覧・引用におけるアノテーション(コンテンツに付与されるメタ情報)を獲得する仕組みを実現する。はじめにコンテンツの作成・閲覧・引用時におけるアノテーションの獲得について説明する。、
2.2.3 作成・閲覧・引用時のコンテンツアノテーションの獲得
コンテンツの意味内容を機械的な処理に適用可能な形式で取り込むために、アノテーションに関する研究が進められている。アノテーションとは、[annotation]に示されるように、あるコンテンツに対して関連付けられるメタ情報である。
本研究では、基本的には図のようにコンテンツの内部にアノテーションを埋め込まない方式を採り、コンテンツの情報を変更することなくアノテーションの管理が行える。コンテンツの内部にアノテーションを埋め込む方式の場合、コンテンツとアノテーションが切り離されないため、利用が容易であるが、コンテンツとアノテーションを同時に管理する必要があり、今後増え続けると考えられる様々な種類のコンテンツを対象としたアノテーションに柔軟に対応できるように、こちらの管理方法を採用している。本研究では、記録・作成されるコンテンツに対して、固有のURI(Uniform Resource Identifier)を設定することで、任意のコンテンツへのアノテーションを実現する。
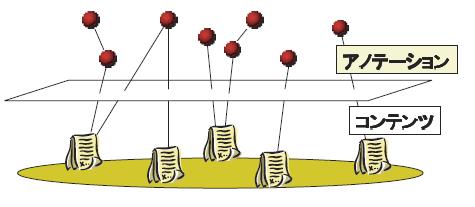
図2.1: コンテンツとアノテーションの関係
アノテーションに関する研究を分類すると、主に1. 規格化、2. 収集、3. 応用の3種類に分類されると考えられる。
アノテーションの規格化は、コンテンツに付与されるメタ情報の記述能力を左右する重要な点であるといえる。コンテンツの種類に依存したアノテーション形式と、コンテンツの種類に依存しないアノテーション形式に二分される。
コンテンツの種類に依存する形式としては、GDA(Global Document Annotation)[13]やMPEG-7が挙げられる。GDAはテキストに対する構文・意味情報を詳細に記述するための形式である.MPEG-7はマルチメディア・コンテンツに対するメタデータの表記方法に関する国際標準規格である。
一方で、コンテンツ自体の情報や、コンテンツ同士の関連性などを記述するアノテーション形式として、RDF (Resource Description Framework)[http://www.w3.org/TR/REC-rdf-syntax/]が標準化されている。URIを持つリソースであれば、コンテンツの形式を問わずアノテーションの対象に指定可能であるため、異種類のコンテンツ間の関連性を表現することができる。従来、コンテンツ間の関連は、HTMLのハイパーリンク構造により導き出されることが一般的であるが、ハイパーリンクには、リンクの意味を記述することができない点が問題であった.RDFのデータ構造は、[rdf]に表すように、主語・述語・目的語の組みによって、ラベル付き有向グラフとして表現される。例えば、ある楽曲の制作者を記述する場合、楽曲のURIを主語に、制作者のURIを目的語に、それらの間の関連性として、制作者であることを示す{dc:creator}という述語を記述する.またアノテーションの述語に相当する部分の柔軟な定義が可能であり、様々な関連性に関する情報を表現することができる.このことから様々な種類のコンテンツ同士の関係の把握を容易にし、多様なアプリケーションに適用可能な形式であるといえる。
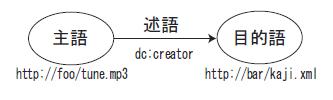
図2.2: RDFのデータ構造
また、コンテンツの部分要素に対するアノテーションを扱うためには、そのコンテンツのセグメントを指し示す手段が必要である。部分要素とは、論文や研究ノートなどのテキスト文書であれば、章や段落、文章といったレベルの要素を指し、画像や映像であれば特定の矩形範囲や時間区間を指す。梶らは、任意のURIを持つメディアに対してセグメントを指し示す形式としてElementPointer[14] を提案しており、本研究では、このElementPointerを参考に、任意のコンテンツの部分要素に対しても同様にURIを割り当てることで、アノテーションを可能としている。
次に、アノテーションの収集に関して述べる。アノテーションには計算機によって自動的に生成されるものと人間の手によって作成されるものが存在する。計算機の自動解析によってコンテンツの構造を認識する研究が多く存在するが、一方では自動解析によって得ることの困難な情報を、人間の手によって付与するシステムに関する研究が盛んになってきている[15][16]。アノテーションを付与するための特別なエディタを用意し、詳細な構造情報等を付与するというものである。しかし、特別なエディタを用いた人手によるアノテーションの収集は、コンテンツの内容に詳しい専門家がアノテーションを付与する形となるため、長期にわたって記録される大量の論文・発表資料・議事録といった研究活動におけるコンテンツに適用するのは、人的コストを考慮すると現実的ではない。
そこで、本研究では、日々の活動の中で行われるコンテンツの作成・閲覧・引用行為に着目し、研究活動のこれらの行為の履歴から自動でアノテーションを収集する。具体的な作成・閲覧・引用行為とは、閲覧した論文や作成ノート等にタグやコメントなどのテキストを付与したり、ある特定の論文の部分に対してマーキングしたり、ノートに論文の一部を引用するといった行為である。研究者が使用するツールにアノテーションを収集する仕組みを組み込んでおき、それらのツールを日常的に使用してもらうことで、人手によるアノテーションのコストを限りなく小さくすることが可能となる。
これらのアノテーションを獲得を実現するために、我々の研究室では数多くの研究活動支援ツールが開発されてきた。次項からは、それらのコンテンツを記録する仕組みと、その中で作成・閲覧・引用時のアノテーションを収集するための仕組みについて述べる。
2.2.4 論文の管理・閲覧
研究活動において論文の閲覧は、非常に重要な作業である。研究者は、自身の研究分野の動向やその分野における自身の研究の位置付けを知るために論文を図書館やWeb上のアーカイブから入手し、閲覧する。閲覧した論文は、印刷してファイルとしてまとめたり、計算機上で、インデックス付けされて管理される。文献管理用のソフトウェアとしては、EndNote[http://www.usaco.co.jp/products/isi_rs/endnote.html]などが挙げられる。EndNoteでは、論文のPDFファイルをWebで公開されているbibtexなどの書誌情報と関連付けて登録しておくことで、論文の管理・検索を行うことができる。
しかし、EndNoteでは、論文全体を検索することはできても、論文の部分要素を検索することは不可能である。個々の研究者にとって、他者の論文に含まれる全ての内容が重要あるとは限らないため、論文の特定の部分だけを検索したい場合も多い。
我々の研究室では、論文を閲覧時に、論文の部分要素に対してアノテーションを行う仕組みであるTDAnnotatorを開発・運用してきた[5]。[TDAnnotator]にその画面を示す。このTDAnnotator上では、Webブラウザ上での論文の投稿・閲覧が行える。さらに、閲覧中に論文のキャプチャ画像に対して矩形範囲を指定することで、その部分へコメントなどのテキストを付与することが可能となる。
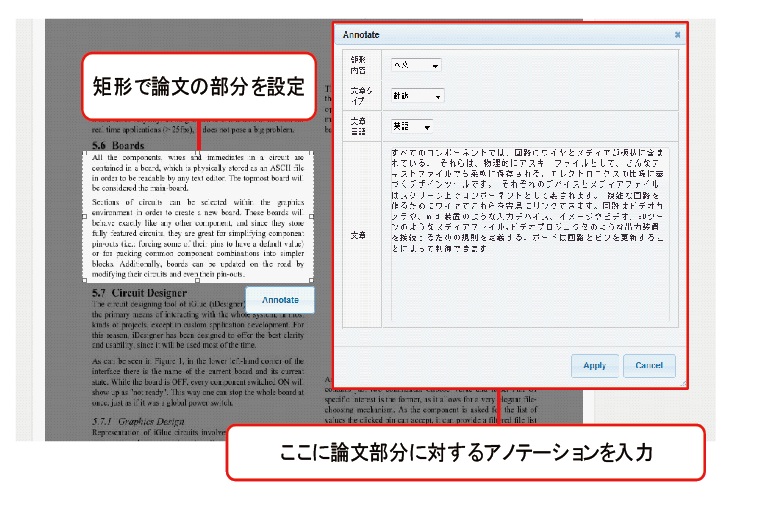
図2.3: 論文閲覧システムTDAnnotatorの画面
本研究では、このTDAnnotatorの仕組みを拡張し、著者が閲覧してきた論文を検索するための仕組みを実現する。拡張したTDAnnotatorの仕組みについては3章で詳細に説明する。
2.2.5 研究ノートの作成
研究活動において作成されるノートには様々なものが考えられる。具体的には、日頃の気付いたことを簡潔に記した覚書、実験結果や分析結果、文献調査やプログラミングなどの作業の計画や進捗を書き記したものなどが挙げられる。ここでの研究ノートは、一時的に利用され、用が済んだら廃棄してしまうような揮発性が高く再利用性が低い性質のものではなく、スケジュール帳のように、以前の内容を参照しながらの書き込みや、書き込み内容の振り返りによる継続的な活動を支援するテキストコンテンツを指す。
また、研究ノートは、以下のような特徴を持つ。
- 作成者本人のみが閲覧・編集するものである
- 特定のフォーマットが定まっておらず、作成者自身が自由に記述できる
- 日々の活動の中で常に内容が更新され続け、何度も見直される
- 時間や場所を問わず作成される
「作成者本人のみが閲覧・編集するものである」について、ここで定義する研究ノートは、個人が自身の日々の活動内容を記すものであり、会議の配布資料や論文のように他人と共有することを目的としたものではない。そのため、「特定のフォーマットが定まっておらず、作成者自身が自由に記述できる」という利点がある。
また、研究ノートの大きな性質として、「時間や場所を問わず作成される」という点が挙げられる。日頃の気付いたことを簡潔に示すようなメモやTODOといった内容を記録する場合、必ずしも現行の据え置き型コンピュータのような高度な機能性は必須ではなく、それよりも場所や状況に関わらず、いつでもどこにいても思いついたときに書き記すことができるこということがより重要視される。コンピュータが普及した現在においても、検索性や再利用性が低い紙媒体のノートや手帳を利用する人が多いのは、いつでもポケットから取り出して書き込みできるという手軽さがより重要視されるためであると考えられる。
代表的なクラウドノートアプリケーションとしてはEvernote[http://evernote.com/intl/jp/]が挙げられる。据え置き型コンピュータの使用に加え、スマートフォンなどのモバイル端末での利用も想定しており、比較的紙媒体のノートに近い使用感でノートを作成することができる。
我々の研究室では、iStickyと呼ばれるクライアントソフトウェアが開発・運用されている。iSticky上では、研究ノートの作成に加え、画像の編集・閲覧、及びスケッチの作成など様々な機能を有している。[isticky]にその編集・閲覧インタフェースを示す。
図2.4: iStickyのノート編集・閲覧インタフェース
iSticky上では、ノートにタグを付与して整理するための仕組みや、ノートに含まれるテキストに対し、「重要」「緊急」「予定」などの属性の付与が行える。それらの属性が付けられたノートの部分を検索することも可能である。これらのタグや属性の情報はコンテンツへのアノテーションとして、論文執筆中に自身の研究ノートの一部分を参考にする際に有用になると考えられる。
iStickyで作成したノートは、クラウド上にアップロードすることも可能である。[noteserver]にブラウザ上でクラウドにある研究ノートが一覧で表示されている画面を示す。ノートのアイコンとタイトルの一覧が表示されており、編集ボタンを押すことで、編集ページに遷移する。
図2.5: クラウド上のノート一覧画面
ブラウザ上でも、ノートの編集・新規作成・削除が行え、iStickyからアップロードしたノートをブラウザ上で編集した場合でも、iSticky側で同期して変更内容を反映することも可能である。
2.2.6 画像・音声・映像の作成
近年では、iPhoneなどの携帯端末でも画像・音声・映像といったコンテンツの作成・録音が容易になっており、また誰でもWeb上に手軽に公開することも可能となった。
研究活動においてもこれらのコンテンツは頻繁に扱われる。成果を分かりやすく説明するための画像の作成、ミーティング中の音声の記録、研究発表に用いるデモ映像の撮影・編集などが例として挙げられる。
我々の研究室では、実際に研究室で作成された画像・音声・映像をクラウドサーバ上に投稿・管理できる仕組みを実現している。[imageserver]にクラウドサーバに記録された画像の閲覧画面を示す。
図2.6: クラウドに記録された画像の閲覧画面
画像の投稿はPCブラウザまたは、前述したiStickyから行うことができる。ブラウザ上では図の左側に示すようにフォルダ分けして管理されており、フォルダの移動、画像の削除及び画像の共有設定などが行える。音声ファイルに関しても、川西ら[17]が研究活動における音声ログをクラウド上でタイトルやタグと共に音声を管理する仕組みを実現している。
さらに、研究室の中で映像を共有するための仕組みにSharvieがある。[sharvie]にそのインタフェースの画像を示す。[sharvie]では、投稿された画像の一覧が表示されている。Sharvieでは、Web上での映像の投稿・閲覧が可能である。ゼミや研究発表の際に用いたデモ映像や講義映像などをアップロードしておくことで、研究グループ間で映像を共有することができる。また、Sharvie上では、任意のシーンに対するコメントの付与や任意のシーンを切り出して保存・管理することがきるビデオスクラップブックの機能も有している。特に再生時間が長い映像の場合、シーンを閲覧時に切り出しておくことで、後で効率的に検索することが可能となる。ここでのシーンの切り出しはアノテーションとして開始・終了時刻といったセグメント情報を付与することを意味している。
図2.7: sharvie
これらの画像・音声・映像といったコンテンツへのアノテーションに関する研究やサービスは多く存在する。Haslhoferらの開発した2次元地図画像に対する アノテーションシステム[15]では、矩形、座標、楕円、自由線など様々な部分要素に対してアノテーションを行うことが可能である。FlickerやFaceBookといったSNSサービスでも投稿された画像の任意の矩形範囲へのアノテーションが行える。長尾らが開発したVideo Annotation Editor[16]では、カット検出やテロップや音声からテキストを抽出し、それらの機械的に抽出された情報を人手によって編集したり、さらにアノテーションを付与することも可能である。また、近年のニコニコ動画[http://www.nicovideo.jp]やYoutube[http://www.youtube.com]といった映像配信サービスにおいても、任意のタイムコードに対し、コメントを入力することが可能となっており、映像の部分に対するアノテーションは既に普及しているものとして考えられる。
2.3 研究活動支援システムからの文脈情報の獲得
本節では、研究活動の中で、コンテンツの作成時におけるコンテンツの部分要素間の参照・引用関係を研究活動における文脈情報として収集する。我々の研究室では主に、電子ボードを用いたミーティングコンテンツの作成、ゼミ発表における議事録の作成、ノート及びTODOを作成する仕組みの中で文脈情報を獲得する。
2.3.1 ボードコンテンツの作成・閲覧
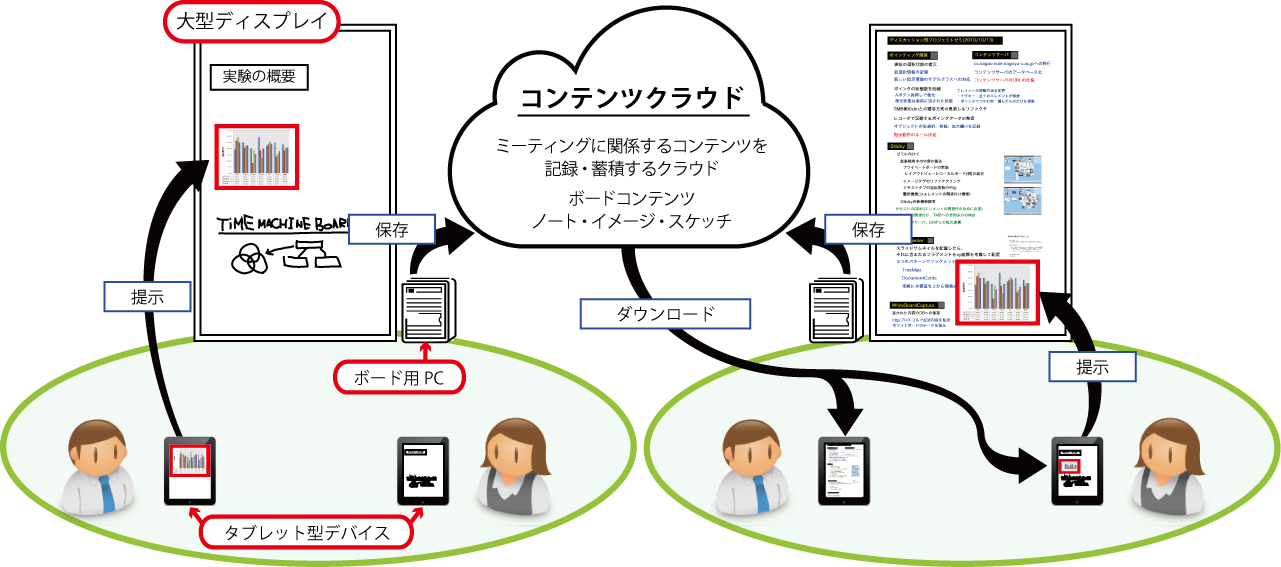
図2.8: TMBシステムの構成と利用イメージ
石戸谷らが開発・運用している継続的ミーティング支援システム[2]は、TimeMachineBoardと呼ばれるミーティング内容を記録するための仕組み(以下、TMBと略記する)と、個人の活動に関わるコンテンツを集約しTMBに情報を入力するためのクライアントソフトウェアであるiStickyによって構成される。[tmb]にTMBの概要を示す(利用イメージについては後述する)。TMBは、大型ディスプレイをボードとして用いる。
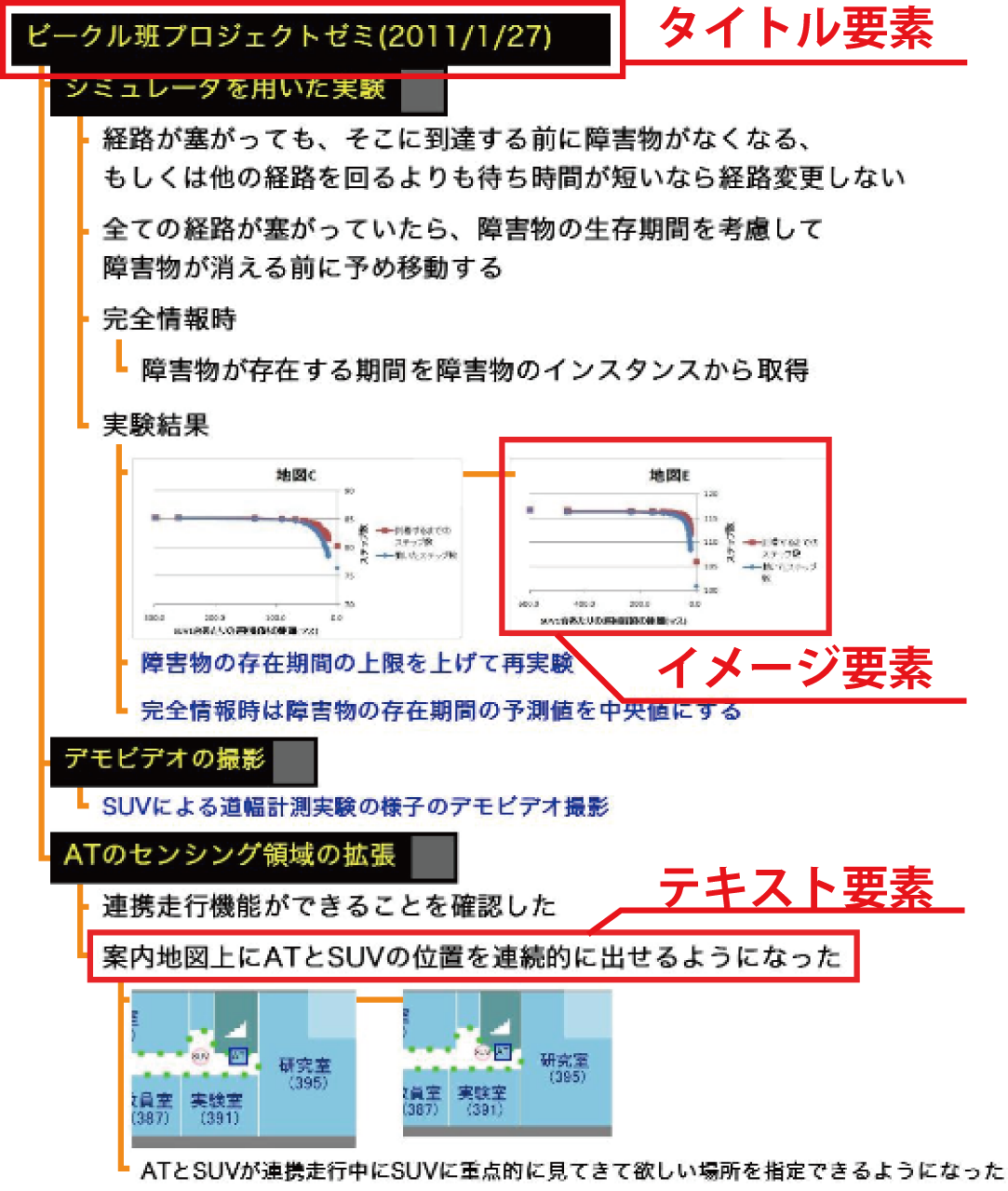
図2.9: ボードコンテンツと木構造
[tmbdump]ボードに提示される情報の一例を示す.ボードには、話し合いの内容を参加者全員で共有し理解しながらミーティングを進めるために、手書きの文字や図、テキスト・画像など(これらをボード要素と呼ぶ)を入力・提示できる。
これらのボード要素はiStickyを用いて作成する。iStickyには前述のように日々の活動記録をテキストとして書き込むためのノート機能、画像を管理するための機能、手書きの図を描くためのスケッチ機能、後述するミーティング記録の閲覧機能が実現されている。ミーティング参加者はこれらの機能を用いて、日々の活動を記録する。これらの記録はコンテンツクラウドに保存され、どこでも検索・閲覧・編集が行える。
そして参加者は、ミーティングの際にiStickyを用いて、自らが話したい内容、他の参加者と共有したい情報をクラウドに保存されたコンテンツの中から選んで、あるいはその場で新たなコンテンツを作成して、TMBに入力する.TMBに表示されている内容はiStickyに表示され、iStickyでボード要素の移動・拡大縮小、フリーハンドストロークの書き込み、ポインティングができ、これらの操作はTMBに反映される。そして、TMBに提示したボード要素を操作し、図に示すようにツリー状に配置してトピックごとにボード要素を分類・整理することでミーティングを進行する.最後に、TMBに表示されているミーティング終了時の状態をコンテンツ(これをボードコンテンツと呼ぶ)としてクラウドに保存する。
クラウドに保存された過去のボードコンテンツをいつでも手軽に参照できるようにするために、iStickyの機能として[tmbsearch]に示すような検索インタフェースが開発されている。検索インタフェース上部には、過去に行われたミーティングの最終状態を表すボードイメージを時系列順に並べたボードイメージビューを配置した。ビューを左右にスクロールすることでボードコンテンツの一覧を閲覧でき、必要に応じて、選択したボードイメージを拡大して閲覧できる.ボードコンテンツをクラウドに保存し、iStickyで閲覧できるようにすることで、過去に行われたミーティングを振り返りながら新しいアイディアを考えたり、話し合いに基づいて作業したりできる。
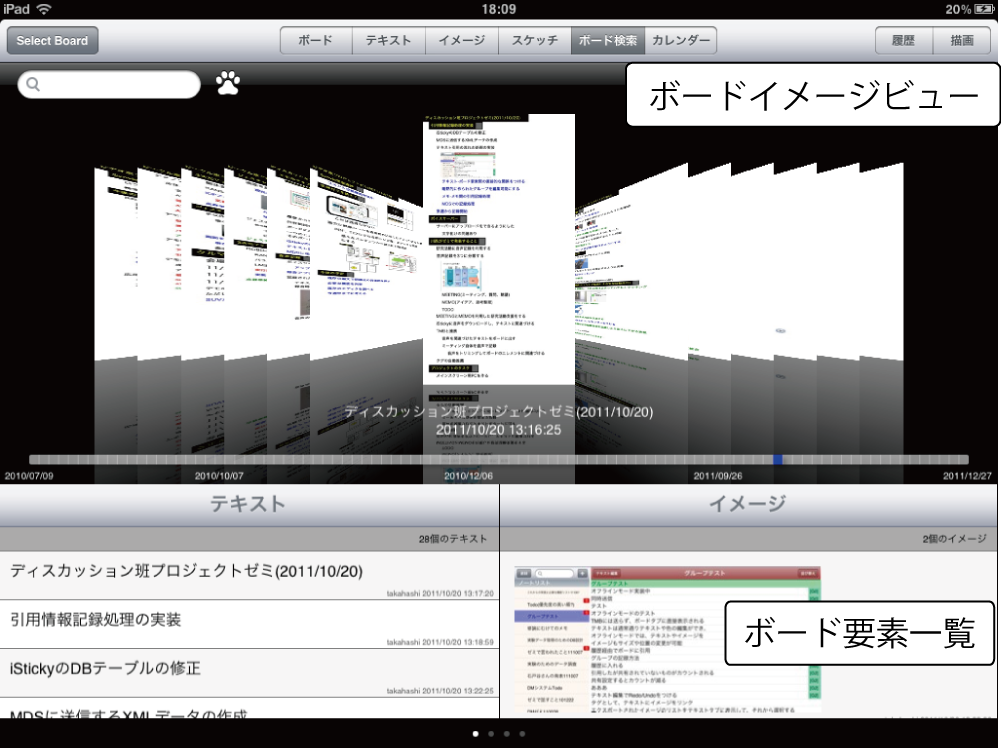
図2.10: ボードコンテンツ検索画面
石戸谷らは、過去のボードコンテンツの一部を進行中のミーティングにおいて引用する仕組みを実現している。引用は過去のボードコンテンツの一部を明示的に提示して話し合うことで同じ話の繰り返しや迷走を防ぐために用いられる。引用の流れを[quote]に示す。まず、参加者Aがあるミーティングでタブレット型デバイスから図をボードに提示(図中①)して話し合う.ミーティングを終了すると提示した図を含むボードコンテンツがクラウドに保存される(②).その後のミーティングで、参加者Bがクラウドからタブレット型デバイスにダウンロード(3)した過去のボードコンテンツから、参加者Aが提示した図をボードに再提示(④)する.明示的に過去のミーティング内容を提示する事で、過去のミーティングを踏まえて話し合うことができる。

図2.11: 木構造と引用情報から表した複数ミーティングの文脈
この引用の実現により、作成したノート及び画像とボードコンテンツの要素間の文脈情報を獲得することができる。この引用関係は、現在、iStickyの中でのみ検索可能となっているため、この引用関係を論文執筆において活用することが、本研究における課題の1つとなっている。
2.3.2 会議コンテンツの作成・閲覧とノートの作成
我々の研究室では、研究活動におけるスライドを用いた会議を記録するための仕組みであるDM(Discussion Mining)システム[3]を開発・運用してきた。
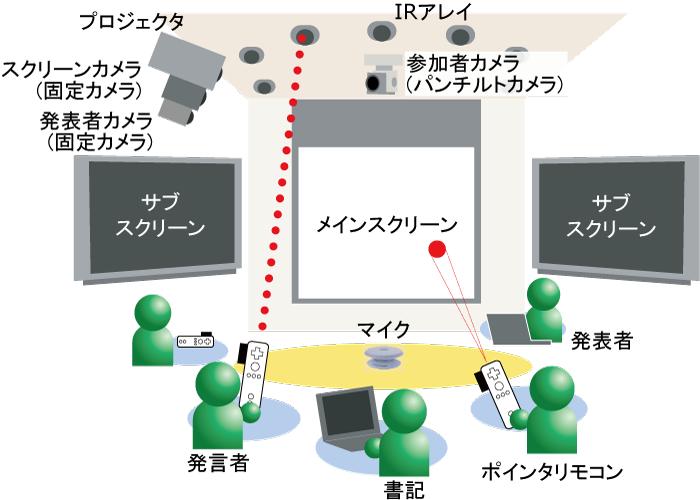
図2.12: ディスカッションルーム
会議を行うミーティングルームは[dm]のような空間を想定している。ミーティングルームには音声を記録するためのマイクが設置されている。会議の詳細な文脈を記録するために、1台のパンチルトカメラが設置されている。また、スライドを投影するスクリーンを記録するための固定カメラが1台、そして発表者の様子を記録するための固定カメラが1台設置されている。 また、DMシステムではミーティングルームの他に、議事録の作成・管理を行うための議事録サーバが用意されている。
会議中の発言に関する情報を記録するための設備として、参加者全員がポインタリモコン[wii]と呼ばれるデバイスを所持し、各参加者の頭上には赤外線信号を発信するIRバーが設置されている(IRアレイ)。会議において発言する際に、発言者はポインタリモコンと頭上のIRバーを一対一対応させることで、発言時の情報を送信する仕組みになっている。発言に関する情報は随時システムに送信され、書記の発言内容入力の支援を行う。
パンチルトカメラは、会議中ディスカッションルーム内をスウィングしながら参加者の様子を記録している。また、発表者以外の任意の参加者が発言を始めたとき、ポインタリモコンと連動し、パンチルトカメラがその方向に固定され、発言者の様子を撮影する。発言終了後には再び会場内を記録するためにスウィングモードに切り替わる。スクリーン用カメラは、スクリーンに投影されるプレゼンテーションに用いたスライド、デモ、その他の参考資料の様子を記録する。
カメラやマイクで会議の詳細な文脈を記録した音声・映像は MPEG-4形式で映像・音声データベースに保存される。発表者が入力したスライド情報、書記が入力したテキスト、参加者のデバイスを使って獲得したメタデータは、議事録XMLとしてXMLデータベースに保存される。

図2.13: ポインタリモコン
このようにして記録された議事録はXMLとMPEG-4によるマルチメディア議事録としてデータベースに記録される。記録された議事録はWebブラウザを用いて容易に閲覧できる。
参加者は発言を行う際に、ポインタリモコンを上に向けてから発言を行う。発言者の頭上には赤外線信号を送信するためのIRバーが設置されており、IRバーから送信される信号には座席位置を識別するためのIDが含まれている。この信号を受信したポインタリモコンは、座席位置だけでなく、ポインタリモコンの利用者(この場合は発言者)のIDや発言の種類(以降、発言タイプと呼ぶ)も含めた情報をサーバに対して送信する。議事録サーバには、これらの情報に加えて受信した時刻が送信・記録される。また、発言の終了時刻はポインタリモコンのボタン操作によって入力できる。
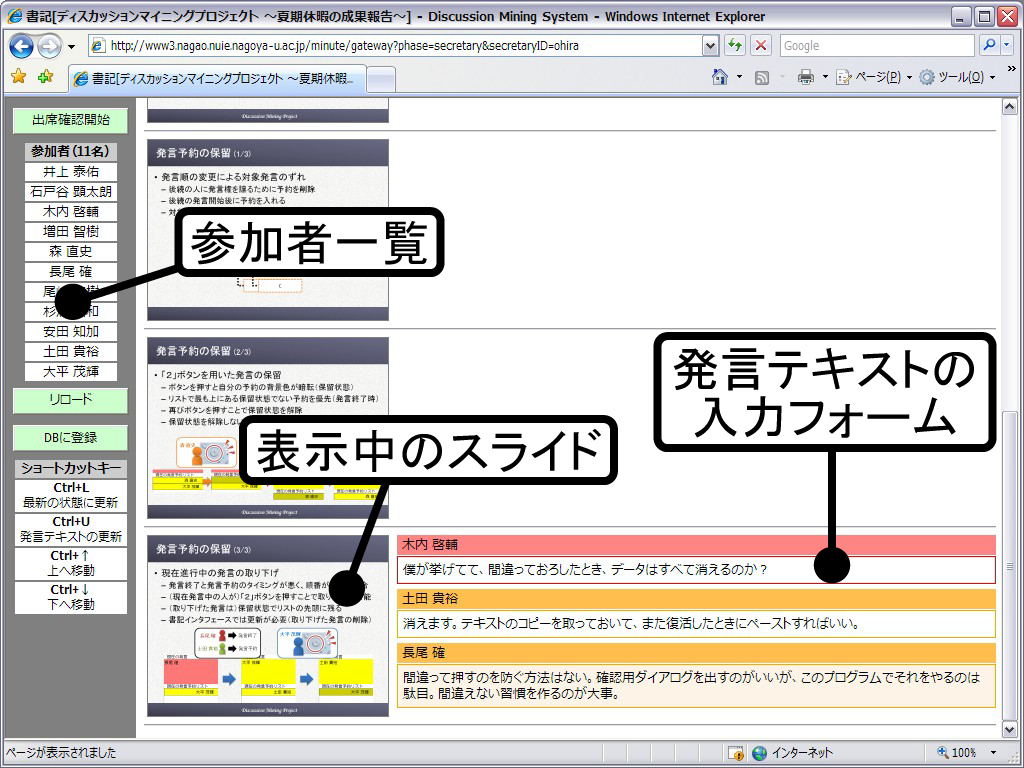
図2.14: 書記用インタフェース
書記は[dmwriter]に示されるWebブラウザベースの専用ツールを用いて議論の構造化と発言内容の記録を行う。また、参加者を撮影するカメラの制御や、データベースへの登録作業などもこの書記ツールから行うことができる。 書記ツールは前述のポインタリモコンと連動しており、参加者が入力した情報が随時追加されていく。ポインタリモコンから情報を発信すると、書記ツールに発言者と発言タイプが付与されたノードが生成される。書記はこのノードを選択し、テキストを入力することで発言内容を記録できる。
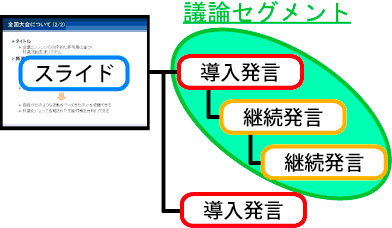
図2.15: 議論セグメント
発言タイプは「導入」と「継続」の2つに分類される。各発言間にどの発言を受けて行われたかを表わすリンク情報を付与することで議論内容の構造化を行っている。継続とは新たな話題の切り出しを行った発言、継続は直前の(あるいはいくつか前の)発言を受けて行った発言として定義されている。会議中、参加者に議論内容の構造化に対して思考を割くことがないように、この2つのタイプに限定している。[segment]のように、現在スクリーンに表示されているスライドに対し、一つの導入発言が付与される。そして、この導入発言をルートノードとし、継続発言がそれに連なるような木構造を形成する。そして会議が進み新たな導入発言が行われていくことで、先のような木構造をなす発言の集合が複数生成される。我々はこの一つの発言集合を議論セグメントと呼んでいる。このように構造化して発言を記録し、発表中に可視化しておくことで、会議で行われた議論の文脈が明らかになり、議論内容の理解を促進させることを期待している。
ポインタリモコンは、発言の開始・終了時間の入力だけではなく、発表者や参加者の発言に対する自分のスタンスといったアノテーションを入力することができる。ポインタリモコンで入力することのできるアノテーションには、発言に対する「賛成」、「反対」、および後述する「マーキング」の3種類がある.参加者はスタンスに応じたボタンを押下することで議事録サーバにそれらのアノテーションの情報を送信する。
図2.16: 複数参加者による図形の描画
また、ポインタリモコンは、メインスクリーンに向けることによって、レーザーポインタのように画面上の任意の箇所をポイントしたり、線や図形を描画したりできる.これにより発言者がスライドのどの部分に対して言及しているかが分かるようになっている。また、参加者全員がポインタリモコンを所持しているため、[pointer]のように、複数人が同時に図形を描画することも可能である。
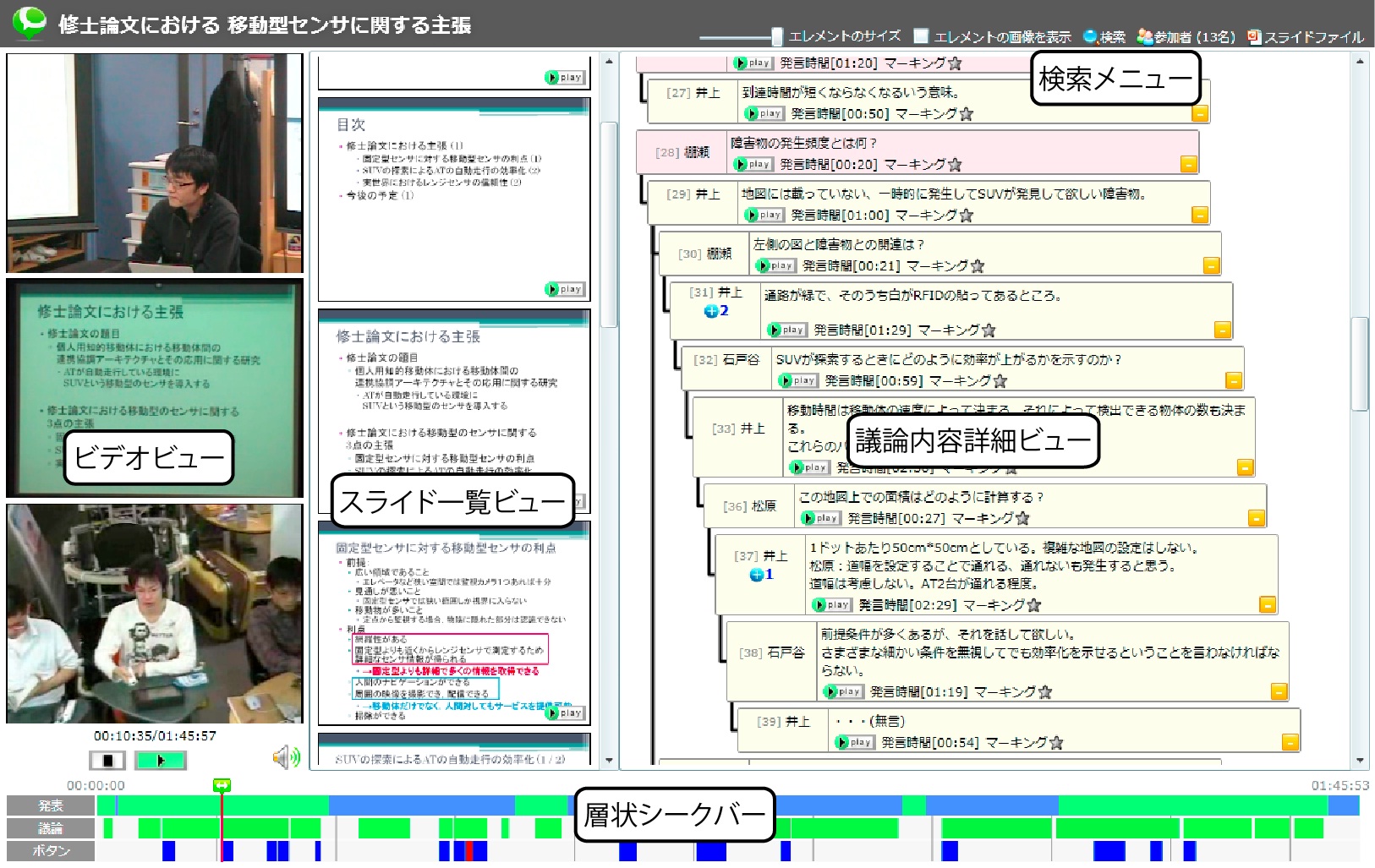
図2.17: DMブラウザ
次に、記録された会議コンテンツを閲覧する仕組みであるDMブラウザも開発・運用されている。ディスカッションブラウザの閲覧インタフェースの全体を[dmbrowser]に示す。このディスカッションブラウザは以下に示すコンポーネントから構成されている。これらのコンポーネントがそれぞれ相互に連携しながら動作することによって議論内容の効率的な閲覧を実現している。ビデオビューで表示される映像は、参加者ビデオ、発表者ビデオ、スクリーンビデオの3種類があり、これら3つのビデオの同時閲覧が可能である。スライド一覧ビューでは会議に使用されたスライドサムネイルが表示されている。スライドサムネイルはスライドの表示された順番にソートされ、また会議中に同じスライドが複数回表示された場合は、スライドサムネイルも複数枚表示される。そしてサムネイルの再生ボタンを押すことで、そのスライドが表示された時間からビデオを再生することができる。
層状シークバー上では、スライドの切り替え時間、議論中にマーキングボタンが押された時間、議論が行われている時間区間が分かるようになっており、それらの情報を参考にスライダーをドラックすることでその時間からビデオを再生することができる。これにより議論中の任意の位置にアクセスすることができる。議論内容詳細ビューでは、[segment]と同様の構造で発言者の名前と、書記が記録した発言テキストが表示されている。
詳細ビューで表示されているノードの再生ボタンを押すことで、その発言からビデオを再生することができる。また、DMブラウザ上でも発言ノードに対してマーキングが行えるため、議論中では、理解できなかったり、重要とは感じていなかった議論内容でもDMブラウザを閲覧することで、記録に残すことができる。
会議コンテンツにおいてマーキングした発言を参照・引用して研究ノートやTODOを作成する仕組みとしてDRIPシステムがある。DRIPシステムでは、会議コンテンツがデータベースに登録されるとそのデータをインポートをし、DRIPシステム上の画面の中に会議コンテンツノードを表示する。議論セグメントに対し、マーキングしておくと、[map]のように会議コンテンツノードからのリンクと共に議論セグメントノードも表示される。

図2.18: DRIPシステム上での画面議論セグメントからのTODOの作成
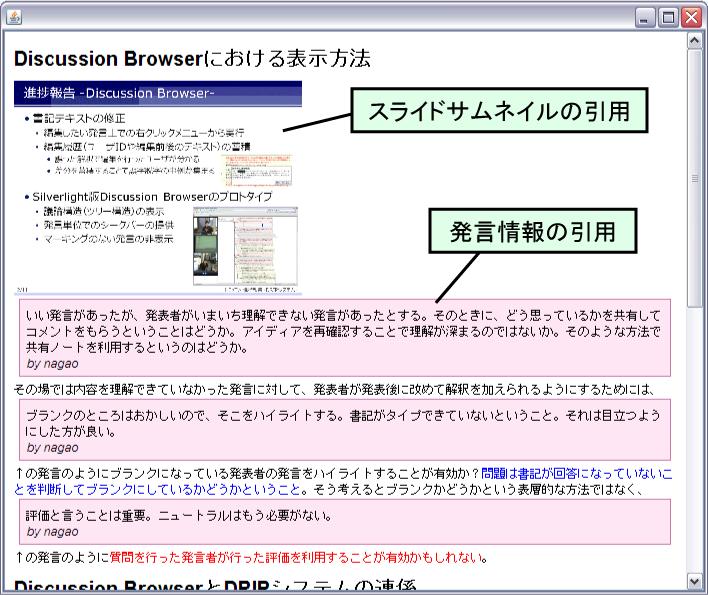
図2.19: スライドサムネイルや発言情報を引用したまとめノート
DRIPシステムのインタフェース上では、選択した議論セグメントのまとめを記述するコンポーネントがあり、ここで記述されたまとめは[map]のようにまとめノートして保存される。まとめには、書記の入力した発言テキストだけでは不足している議論内容の補足や、自分なりに解釈した発言内容などを記述する.その際、「このスライドの表現を受けてこのような発言が行われたのではないか」「この発言でこの人はこういうことを言っていたのではないか」といったように、スライドサムネイルや発言情報そのものを引用しながらまとめを記述できることが望ましい。そのため、インタフェース左側のスライドサムネイルや発言のリストには、引用を行うためのボタンが表示されており、必要に応じて引用を行うことができる。実際にスライドサムネイルや発言情報を引用して作成されたまとめの例を[matome]に示す。
さらに、議論内容をまとめることによって、自身がこれからどんなタスクを遂行するべきなのかが明確になった場合、利用者はまとめと関連付けながらTODOを作成できる.図の議論セグメントのまとめを記述するコンポーネント内で、特殊な記法を用いてTODOへのリンクを記述した状態で保存を行うと、[todo]のようなインタフェースが表示される。利用者は、TODOのタイトルや締め切り、重要度などの情報を入力することでTODOを作成する。
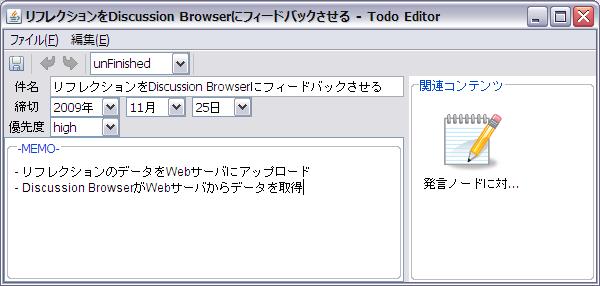
図2.20: TODOの作成インタフェース
[map]のTODOノードを右クリックして表示されるメニューからノートの作成を行うと[dripnote]のようなインタフェースが表示される。このインタフェース上では、ハイパーリンクの自動作成やリスト構造・表の利用など構造化されたノートを記述できる。そして、作成されたノートはタスクと関連付けられ、他のコンテンツに引用可能な状態となる。
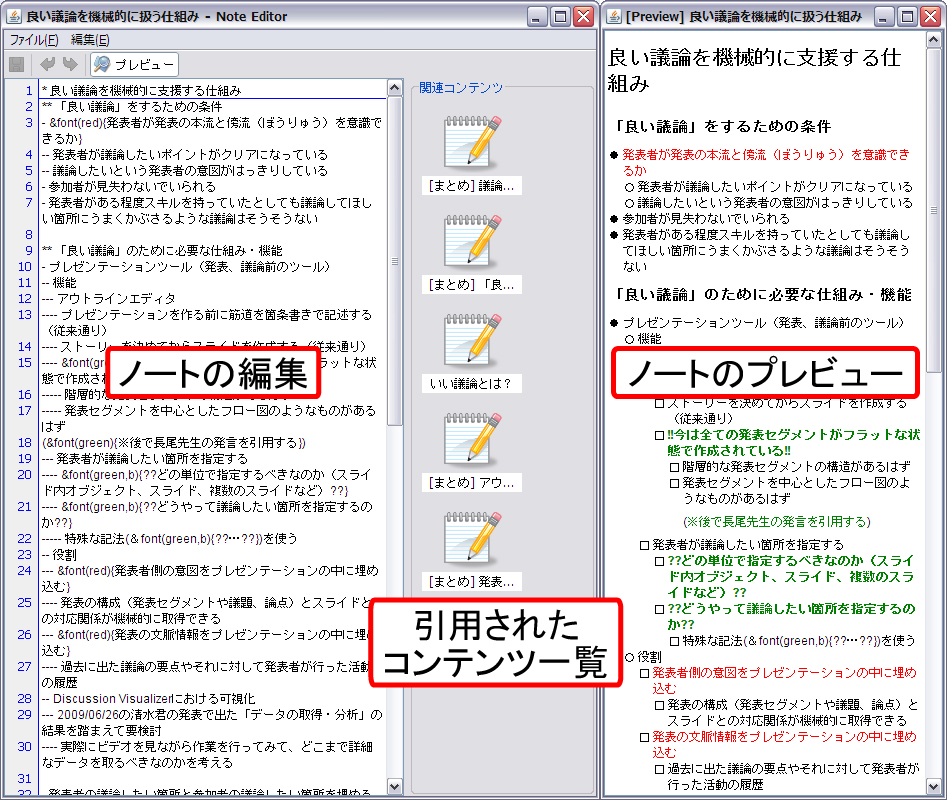
図2.21: ノート編集インタフェース
図2.22: 記録・蓄積されたコンテンツマップの可視化
さらに、DRIPシステムでは、会議コンテンツやノートやTODOに限らず、TDAnnotator上でアノテーションした論文部分、Sharvieで切り出した映像シーンといったコンテンツ(の部分要素)を参照・引用することも可能となっている。このように、研究活動において作成される任意のコンテンツをDRIP上で記録・蓄積することにより、[bigmap]のようなコンテンツのマップを作成することが可能となる。このように人間の頭の中で行われている思考に近い内容を目に見える表示で出力することによって、情報の記憶・整理・理解・発想を効率よく豊かに行うことができる。
加えて、DRIPシステム上では、作成されたノートやTODOを引用しながら、スライドの作成を支援する機能も提供されている。[makeslide]にそのインタフェースを示す。インタフェース上では、発表アウトラインの編集、過去のコンテンツの引用、スライドファイルの自動変換が行える。ユーザは、ノートの時と同様に発表内容を構造的に記述することができ、過去のコンテンツのテキストをコピーアンドペーストすることで自動的にコンテンツ間のリンク情報を記録できる(記録された情報は[bigmap]のインタフェース上で俯瞰できる)。そして、本インタフェースは、作成された発表内容をMicrosoft PowerPoint形式のスライドファイルへ自動変換できる。作成されたスライドを用いてDMシステムによる発表を行い、さらにその議論セグメントのマーキングをDRIPシステムに取り込むことで、継続的にコンテンツのリンク情報を記録することが可能となる。
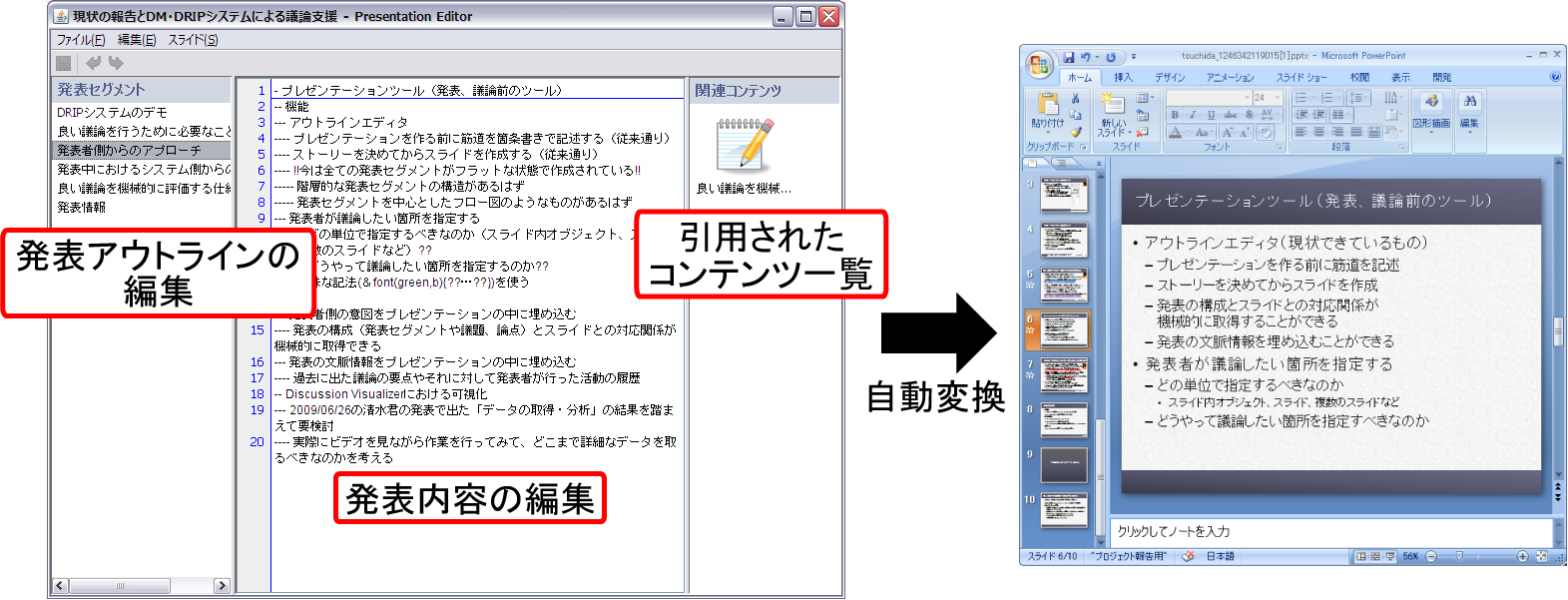
図2.23: スライド作成インタフェース
以上の仕組みにより、ノート、議事録、発表スライド、論文、映像といったあらゆるコンテンツの文脈情報を記録することを我々の研究室は実現してきた。
2.4 論文執筆支援に基づく文脈情報の獲得
我々は、2.2節で述べたように、研究ノートや画像の引用に基づくボードコンテンツの作成、ノートからのスライドの作成支援、論文・映像及び会議コンテンツ(の部分要素)のノートの引用行為などから、コンテンツの文脈情報である参照・引用関係を収集する仕組みを実現してきた。しかし、以下のような課題が残っている。
まず1つめに、これらの文脈情報を活用する機会が少ないことが課題として挙げられる。文脈情報を用いることで、ボードコンテンツの検索やコンテンツマップの可視化の中でコンテンツ間の横断的な検索を実現してきたが、あくまで、個人のコンテンツの俯瞰的な閲覧にとどまり、発見したコンテンツを用いて新たに別の目的に使用するための支援はあまり行われていなかった。そのため、横断的な検索といった応用のみでは、参照・引用を伴うコンテンツの作成に対してモチベーションが向上するとは言い切れない。モチベーションが高くないために、これまでの仕組みだけでは、大量の参照・引用関係を収集することが困難であった。故に、積極的に参照・引用を行うコストに見合った検索以外の応用手法を考案する必要がある。
2つめに、DRIPにおけるノート作成機能は、あくまでも個人の研究ノートを作成するためのものであり、論文のような他者と共有する文書の作成は考慮されていない。すなわち、網羅的に文脈情報を記録しているとはいえない。研究室のような定期的に内部の人間が入れ替わる環境では、その入れ替わりと共に、それぞれの研究者らが蓄積してきた文脈情報が途切れてしまう。そのために、彼らのコンテンツは年月と共に過去のコンテンツとして埋もれてしまう可能性がある。故に、他者のコンテンツを手軽に検索・参照・引用できる仕組み、作成した文書を他者も参照・引用可能な仕組みが必要となる。
そこで、本研究では、これらの文脈情報である参照・引用関係を論文執筆の過程で収集し、さらに、執筆作業においてDRIPシステムやボードコンテンツの中で収集された文脈情報を執筆作業のために応用する仕組みを実現する。論文執筆において、自身の過去の研究活動の文脈情報は、自身の活動を思い出すためにも非常に有用である。また、論文執筆は研究成果を公表するための非常に重要なタスクであり、研究を行う上で避けては通れない作業である。特に執筆に不慣れな学生は、頭の中だけで整理して論文を完成させることは非常に困難であるため、頻繁にコンテンツの参照・引用行為が発生する。また、論文に他者の論文を引用することは、自身の論文の客観的根拠を示すために必要不可欠である。さらに、完成した論文は、同じ研究グループの後輩などに参照・引用されることも多いため、グループ内で研究活動が続く限り、継続的に文脈情報を収集することが可能となる。
本章では、これまでの我々の研究室で実現してきた、論文執筆に至るまでに作成されるコンテンツを文脈情報を含むアノテーションと共に記録・収集する手法について述べた。次章では、論文を含む研究活動における文書の執筆中に文脈情報を収集するための仕組みであるTDEditorについて述べる。その過程で文書の検索・引用を支援するために改良したTDAnnotatorについて述べる。
3 文書作成時のコンテンツの部分引用関係の収集
論文執筆に至るまでに、研究者は様々な文書を作成する。その中には、2章で述べた個人のための研究ノートだけではなく、他者に公開するために作成される発表資料・サーベイ報告書などの文書も含まれる。本章では、このような、公開することを前提とした文書の作成を支援するための仕組み、さらにその中で文脈情報として参照・引用関係を収集する仕組みについて述べる。
公開を前提とする文書の場合は特に、著者の主張の根拠となる文献やデータを文書の中で引用し、明示することが求められる。そこで、文書作成時にあらゆるコンテンツ(論文・ノート・画像・映像・議事録・Webブックマーク等)の参照・引用を実現することで効率的な文書作成を支援する環境を提供する。本研究では、そのような文書作成時のコンテンツの参照・引用を実現したエディタ(以下ではTDEditorと呼ぶ)を開発した。
本章では、TDEditorについて述べる前に、研究活動中における文書の作成の中で、最も参照・引用が頻繁に行われると考えられるコンテンツである論文の管理・記録する手法について述べる。一般に、文書作成時に引用する文書は過去に閲覧したことのある文書であり、閲覧してから長い期間が経過していることが多い。例えば、他者の論文をサーベイしてから自己の論文を執筆するまでには、約1年間が経過していることも往々にしてあるだろう。そのため、既読文書を後で文書作成時に容易に検索・引用するためには、文書をフォルダ分けしたり、文書にタグやコメントを残すなどして管理する必要がある。我々の研究室で開発・運用されてきたTDAnnotatorと呼ばれる論文の管理システムでは、論文の部分要素に対するアノテーションが可能である。本研究では、文書執筆時にこれらのアノテーションの内容とその対象となる論文の部分を適切に検索できるようにTDAnnotatorの機能を拡張した。
次に、TDAnnotatorで管理する論文をアノテーションに基づいて検索可能としたTDEditorについて述べる。TDEditor上では論文に加えて、2章で述べた我々の研究室で記録されてきた多様な研究活動におけるコンテンツを参照・引用しながら文書の作成が行える。
TDEditor上では、システムの中でどのコンテンツ(の部分要素)が文章中に引用されたのかを全て記録しており、文書作成後に他者がその文書を閲覧する際にもその引用関係を閲覧することができる。この引用関係を新たな文脈情報としてクラウド上に記録する。
[system]にシステム構成の全体図を示す。コンテンツクラウド上には、各クライアントソフトウェアであるTDAnnotator・iSticky・Sharvieなどで作成及び投稿された論文・画像・映像・発表資料と、TMBシステム及びDMシステムで記録されたボードコンテンツと議論コンテンツが保存される。また、それらのソフトウェア及びシステムの中で収集されたアノテーションもコンテンツの保存と共に記録される。TDEditorはこれらのクラウド上に記録されたコンテンツ及びアノテーションの文書作成時の検索を可能とするWebブラウザで動作するクライアントソフトウェアである。TDEditor上で作成された文書は、クラウド上の文書に含まれる引用関係などのアノテーションと共に記録され、TDAnnotator上で閲覧可能となる。
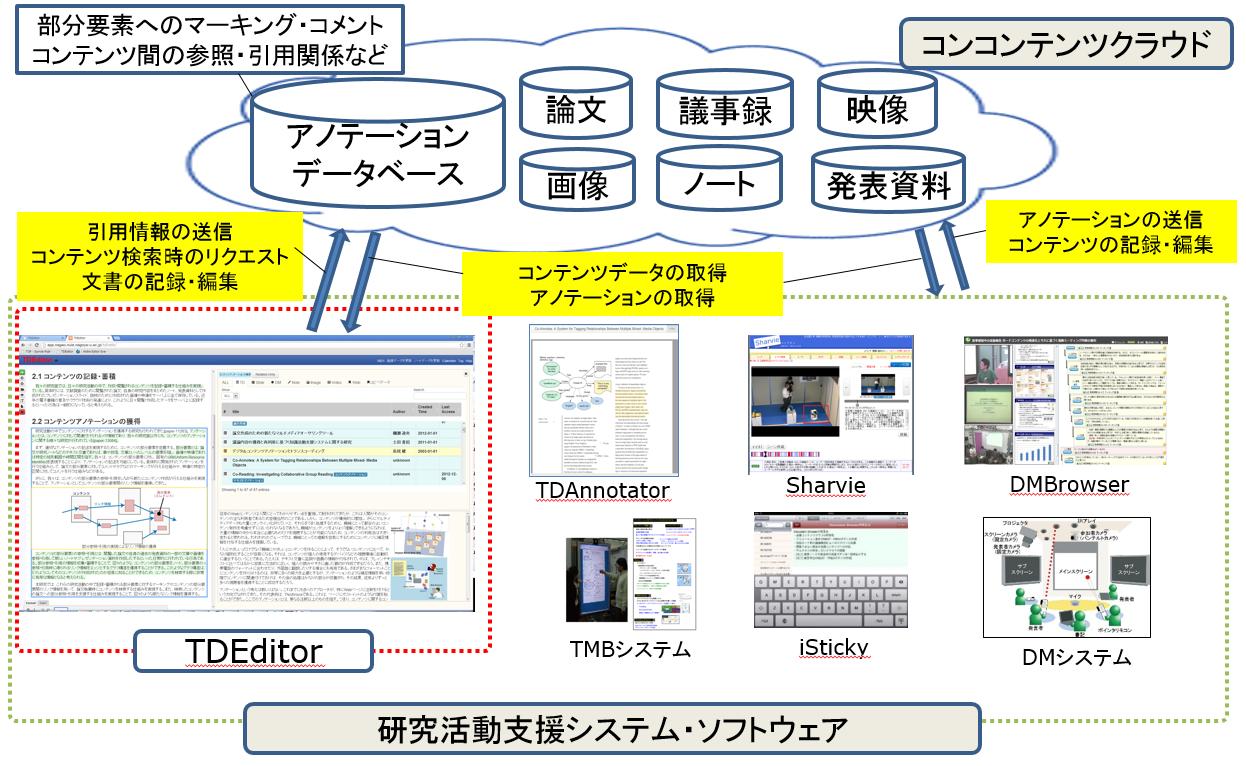
図3.1: 文章執筆支援環境
3.3 文書閲覧支援
他者に公開することを想定した文書を作成する場合、論文などの文献の引用が行われる可能性が高い。権威のある学会に投稿された論文を引用することは作成する文書の信憑性を高めることができる。しかし、世の中に公開されている文書は非常に多く、論文の場合は、文書中に含まれる情報量は比較的多いことが予想される。そのため、研究活動の中で収集した論文を適切に管理する仕組みが求められる。近年では、EndNote[http://www.usaco.co.jp/products/isi_rs/endnote.html]やzotero[http://www.zotero.org/]のような文献管理ソフトウェアやWebサービスが普及している。また、文書の部分要素に対し、アノテーションが行える仕組みも普及している。一般的に普及しているPDFビューワであるAdobe Reader[http://get.adobe.com/jp/reader/]においても、選択したPDFの選択したテキストに対してコメントの付与が行える。このような文書に対してマーキングやテキストの付与を行う研究は盛んに行われてきており、特に代表的な仕組みであるXLibris[8]では、電子化された文書に対してペンタブレットを用いて自由線や文字列のハイライトといったマーキングを行う仕組みを実現している。一般に、文書を閲覧する際には、文書中で重要だと感じた箇所に対してマーキングしたり、考察や感想をコメントとして記入する。これらの行為は文書の部分要素に対するアノテーションとして捉えることができる。
このような閲覧時のアノテーションは、既読文書の再閲覧をより効率よく行えるようにする。過去にユーザ自身が付与した閲覧時アノテーションには、過去に閲覧した際の文脈を想起させる効果がある。一般に、文書を読んでから自身の文書を書くまでには長期間経過していることが多いことを述べた。そのため、文書を書く際に過去に読んだことのある文書を再び閲覧しても,文書の内容をなかなか理解できないことがある。そのような場合に、文書に付与されているマーキングやコメントは文書と共に閲覧することで、文書を読んだ際に考えていたこと等が想起され、内容を再理解する際の手掛かりとして利用される。例えば、閲覧時に重要箇所をマーキングにより記録しておくことで、再閲覧する際には文章を流し読みするだけで、大まかな内容を把握できるだろう。
このような論文の部分要素に対するアノテーションを実現している論文管理システムであるTDAnnotatorを我々の研究室では開発・運用している。本節では、このTDAnnotatorについて詳細に述べる。
3.3.1 論文の登録・管理
TDAnnotatorでは、PDF形式及びXML形式で記述された文書の管理・閲覧を実現している。XML形式の文書は、後述するTDEditorを用いて作成された文書である。ここでは、一般的な電子文書のフォーマットであるPDF形式の文書のTDAnnotatorへの登録方法について述べる。PDF文書は、あらかじめユーザがWebのアーカイブ及び紙媒体の文書をスキャンして電子化することで入手していることを想定している。[submit]にPDFファイルの登録用のページを示す。登録ページでは、書誌情報を入力することができる。すべての書誌情報を手作業により入力することは、非常にコストがかかるため、Web上に公開されている文書の場合は、文書の公開URLをフォームに先に入力しておくことで、自動的に著者名や発行所などの書誌情報を取得する。具体的には、URLに存在するHTMLを解析し、書誌情報を含むRDFやbibtexを抽出することで実現している。現在はcinii[http://ci.nii.ac.jp/]に記録されている文書にのみ対応している。
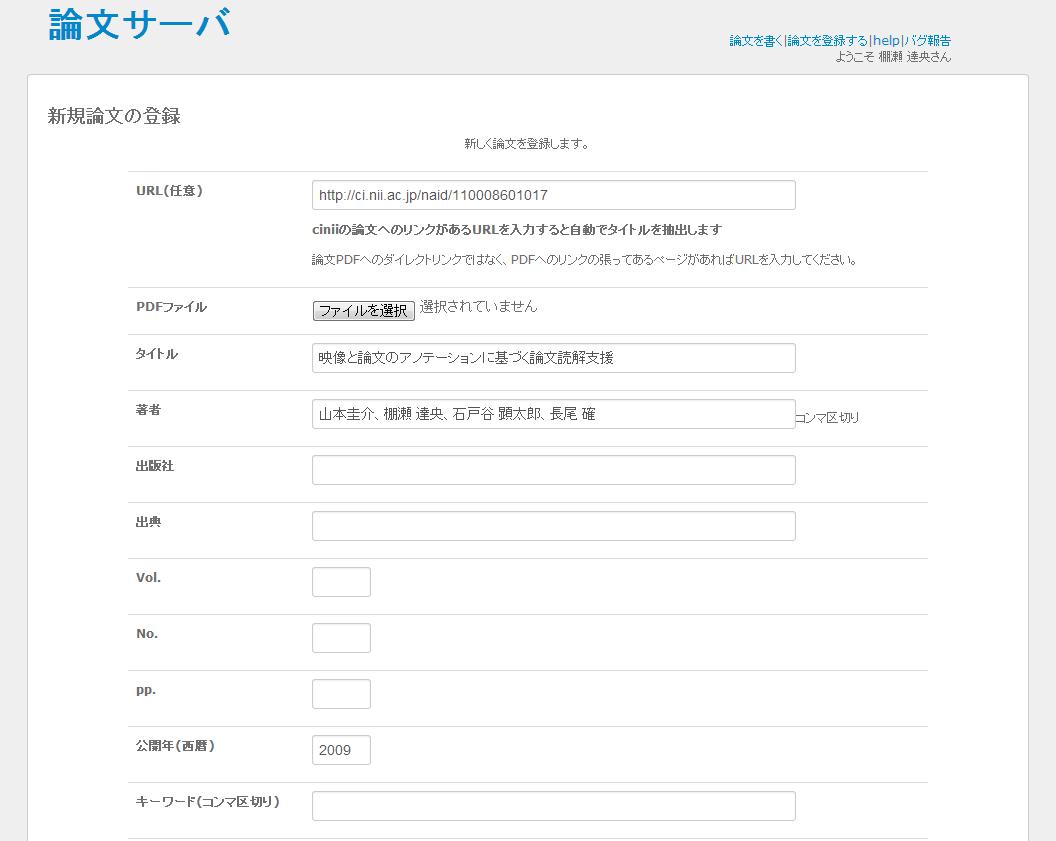
図3.2: 論文の登録画面
PDFの登録時には、[submitanno]のに示すように、コメントまたはタグを入力することが可能である。コメントを残すことで、後で文書を閲覧する際に、この文書の大まかな内容を把握することができると考えられる。タグは公開用タグと個人用のタグの2種類が存在する。登録する文書を同じ研究グループのユーザに対し、公開するか否かを設定することが可能であるため、公開される場合はそれらのユーザもそのタグで文書を検索することが可能となる。個人用に付与するタグは、必ずしも、登録者以外の検索に適したものであるとは限らないため、このように分けている。さらに、タグの入力の際には、オートコンプリート機能により、入力しようとしている文字列を含むタグが存在する場合は、入力候補としてフォームの下に表示され、入力コストを小さくしている。
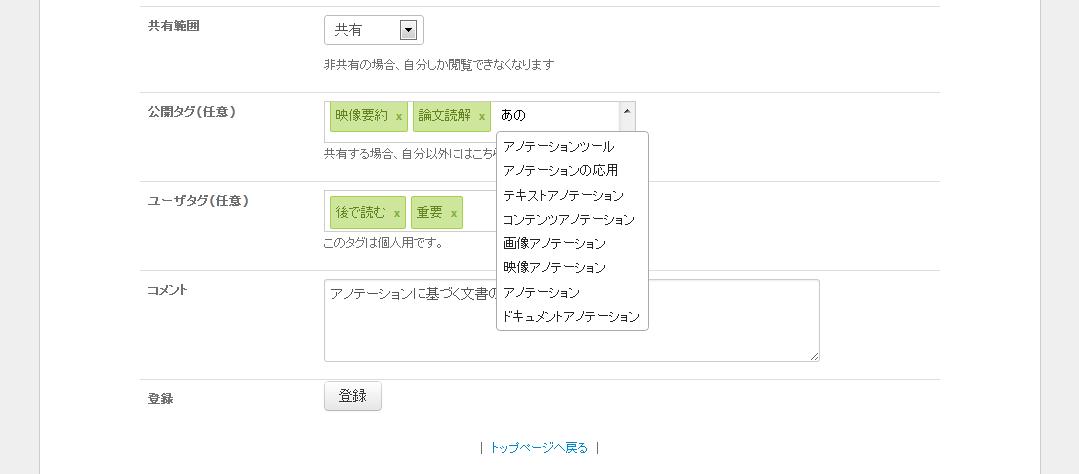
図3.3: 文書登録時のアノテーション
登録された文書の一覧は[paperlist]にのようにブラウザで閲覧することができる。[paperlist]中央には、論文のタイトルが書誌情報及び入力されたタグやコメントと共に表示されている。[paperlist]左には公開タグ及び個人タグが表示されており、クリックするとそのタグが付与された論文の一覧に画面が切り替わる。画面の上部のテキストフォームでは、タイトルや著者による検索を行うことができ、文書の検索が容易に行えるようになっている。検索した文書に対してアノテーションを行うと自身が文書を登録した文書と同様に、最初に表示される文書一覧に表示されるようになる。
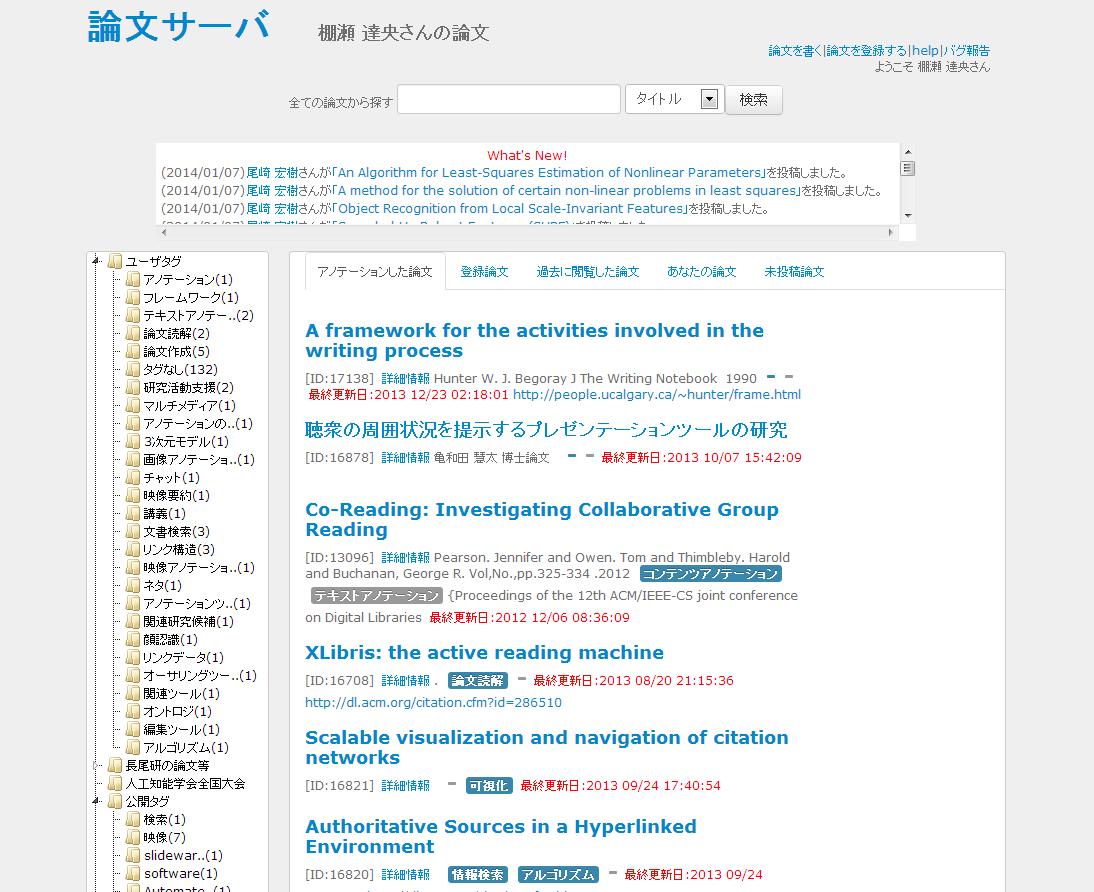
図3.4: 登録された論文の一覧
3.3.2 閲覧時アノテーションの収集
文書閲覧インタフェースを[annotator]に示す。文書の一覧のタイトルをクリックするとこのページに遷移する。画面左側が文書画面、右側にアノテーションの一覧が表示される。
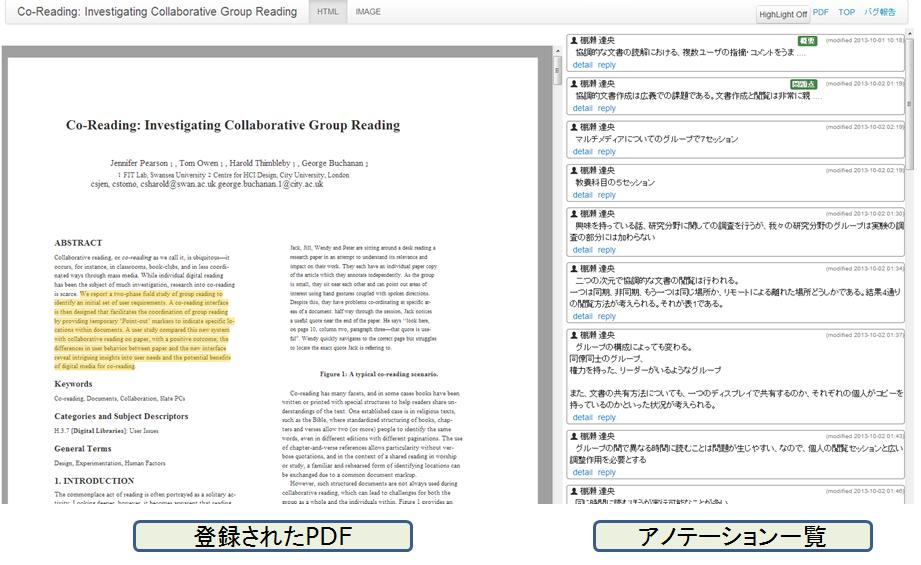
図3.5: TDAnnotator文書閲覧インタフェース
画面左上の論文タイトルをクリックすると文書全体へのアノテーションが行える。具体的には、登録時と同様なタグやコメントの付与が行える。このような論文全体に対するアノテーションは、後で文書を読み返す際に、大まかに文書の内容を想起させるのに有効である。例えば、文書全体を閲覧した感想や参考になった内容をコメントとして残したり、「アルゴリズム」「アノテーション」「論文執筆支援」といったその論文がどのようなトピックについて述べているのかをタグで簡潔に表現しておく、といったことが考えられる。
文書全体のアノテーションのみでは、大まかに論文の内容を思い出すことはできても、数十ページにもわたる論文などの場合は、文書のどの部分に重要な内容が記述されているのかを思い出すことは一般に困難である。TDAnnotatorの閲覧インタフェース上では、文書のテキスト部分のアノテーション、画像へのアノテーション、矩形範囲へのアノテーションを実現している。これらのアノテーションを実現するために、TDAnnotator上ではPDFが登録された際に、テキストと画像の抽出を行っている。抽出にはpdftohtml[http://pdftohtml.sourceforge.net/]を用いている。インタフェース上の画面は、pdftohtmlによってPDFから変換されたXMLを解析し、さらにHTMLに変換して出力されたものである。XMLは、内部構造に関する情報をタグとして保持することが可能であり、内部要素に対するアクセス手段としてXPointerと呼ばれる標準形式を利用することができる。ただし、PDFは紙ベースの文書をコンピュータ上で表示、印刷することを前提に設計されたものであり、文書の内部構造に関する情報を保持していない場合が多いため、pdftohtmlにより抽出される構造情報は段落構造程度であり、章・節といった文書構造や表・数式の構造情報は失われている。
テキスト部分へのアノテーションは[textanno]に示すように、テキスト範囲を選択することで行える。画像へのアノテーションは、[imganno]に示すように、画像の上で右クリックを行うことで行える。前述したように、表や数式は単なるテキストとして抽出されるため、PDFと同様に表示することが困難である場合が多い。その場合は、矩形範囲によるアノテーションを行う。[annotator]の上部に位置するIMAGEタブをクリックすることで左側の文書の表示が論文のページごとのキャプチャ画像に切り替わる。キャプチャ画像は論文の投稿時に抽出される。キャプチャ画像表示の場合は、[selectrange]のように、矩形範囲を選択することでアノテーションを付与することができる。キャプチャ画像に対するアノテーションであるため、矩形範囲によるアノテーションの際には、その選択範囲に対して表・画像・数式といった構造情報を付与することが可能である。構造情報を付与することはユーザの入力コストを増やすことにつながるため、PDFから自動的に構造情報を取得する仕組みや構造情報を持った文書形式が今後普及することを我々は期待している。
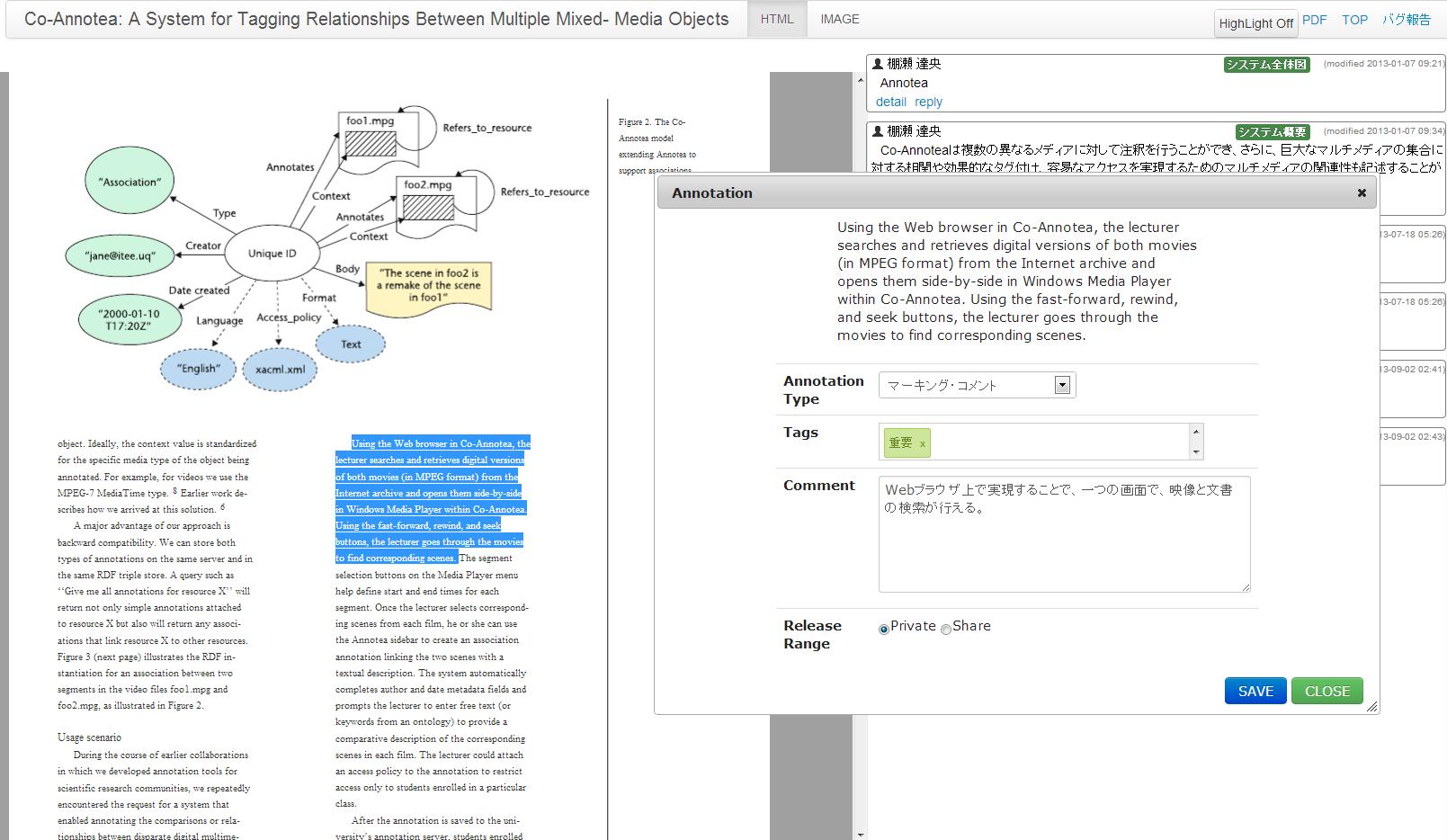
図3.6: テキスト範囲選択によるアノテーション
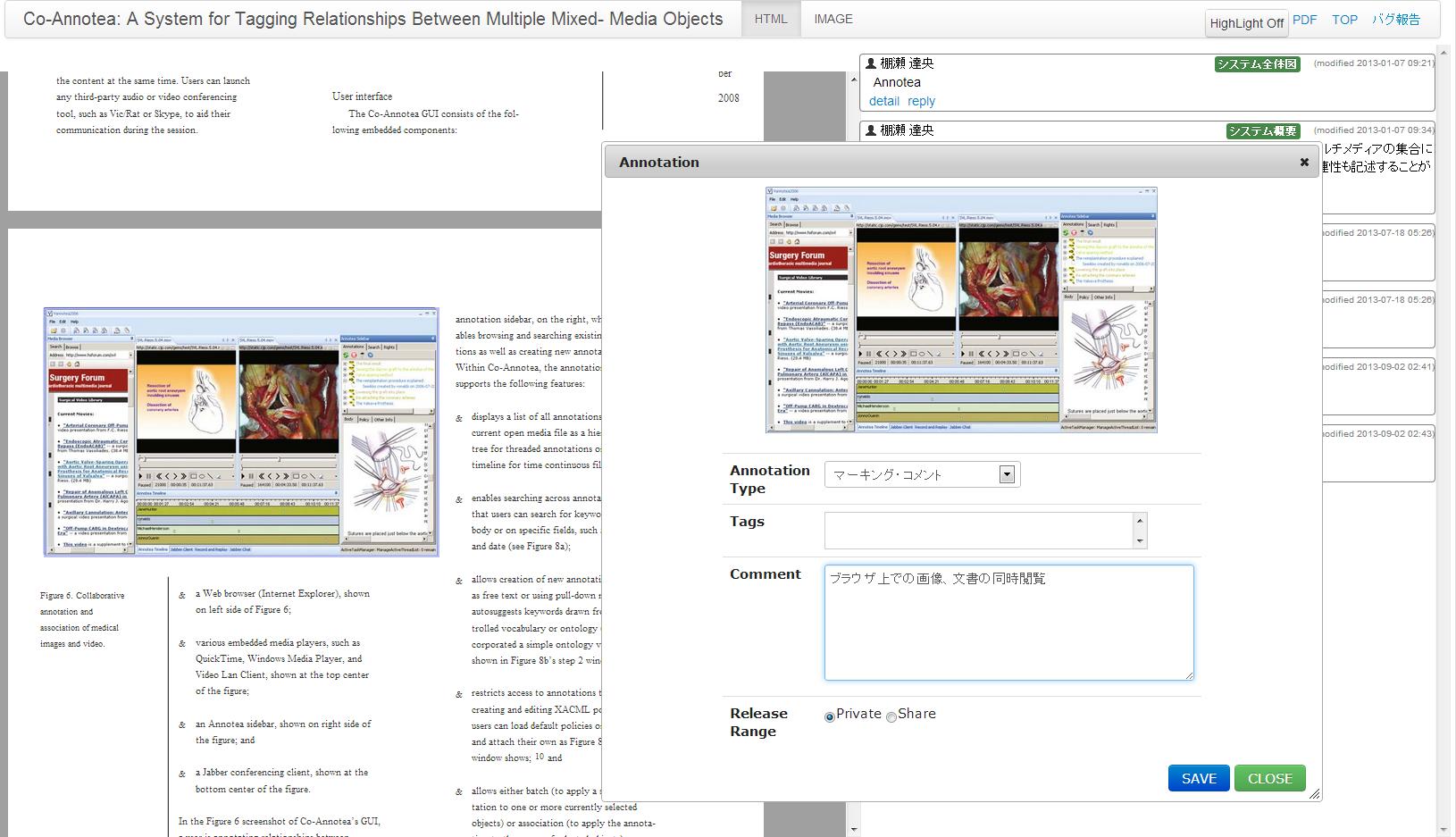
図3.7: 画像アノテーション
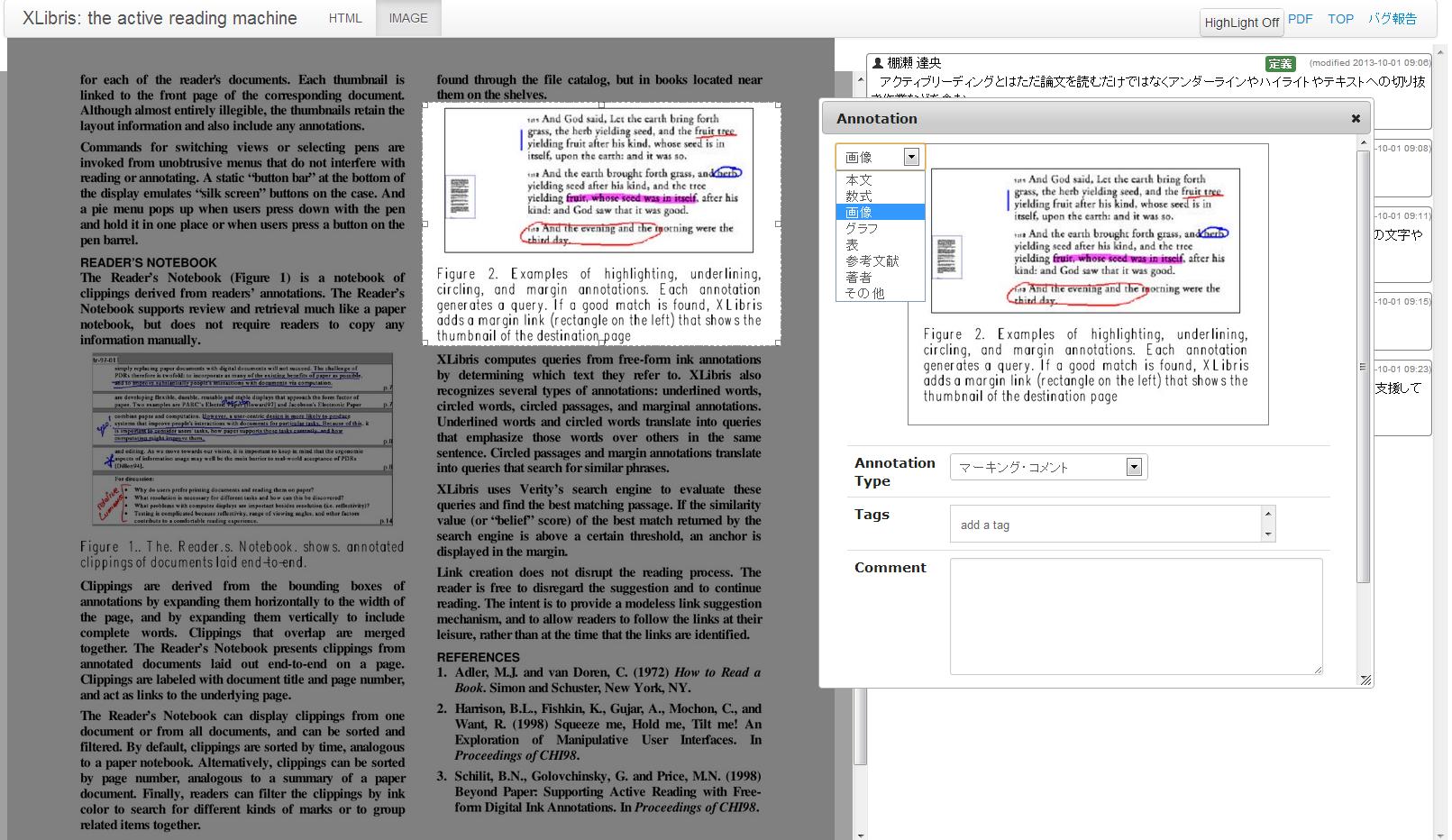
図3.8: 矩形範囲に選択によるアノテーション
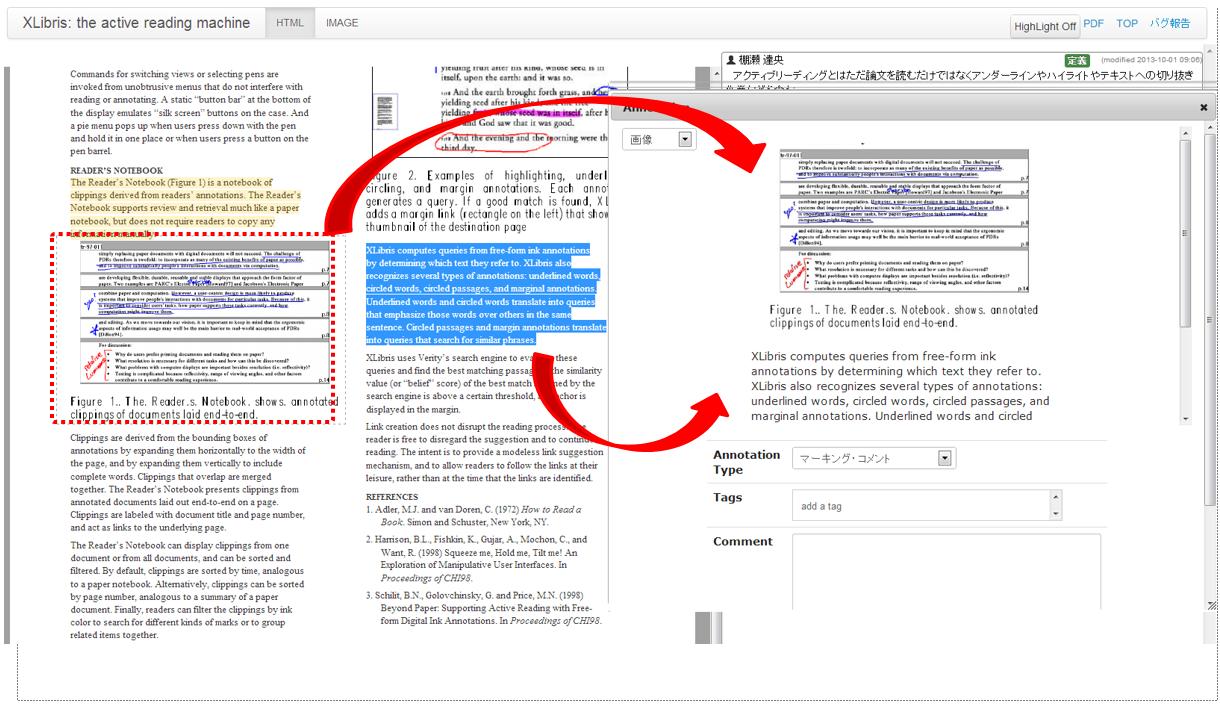
図3.9: 複数部分への同時アノテーション
また、複数部分への共アノテーションも可能である。例えば論文などの場合、画像と画像を説明している文章が離れていたり、異なるページに記述されている場合がある。共アノテーションは、そのような場合に、テキスト範囲、画像、及び矩形範囲を複数関連付けてアノテーションを付与する行為である。[multianno]に共アノテーションの様子を示す。このように複数部分への共アノテーションを実現することで柔軟なアノテーションが行える。
部分要素に対するアノテーションの場合も、文書全体に対するアノテーションと同様にコメントやタグの付与が行える。タグを入力する際は、文書登録時のタグの入力と同様に入力中のテキストに基づいて、既に登録されているタグが推薦される。研究活動における文書閲覧時には、研究内容に応じた様々なタグが付与されることが考えられるが、システム側であらかじめ提供できるタグも考えられる。林らが開発した文書閲覧システムでは、アノテーションの意図に関する属性情報を入力する仕組みを実現しており[1]、その中で提案されている「問題点」「感想」「和訳」「専門用語」といった属性を入力候補タグとして提示する手法が考えられる。他にも、選択した部分要素のテキストの解析内容からのタグを推薦する仕組みも考えられるが、いずれにせよタグの入力コストを減らす仕組みが必要であると思われる。
アノテーションを行う際には、共有範囲の設定も行える。共有範囲には、「private」「share」「public」の3つが存在する。「private」はアノテーションを行ったユーザのみがそのアノテーションを閲覧できる。「share」はあらかじめ設定したグループ内、「public」はシステムのユーザ全員が閲覧できる。サーベイなどで論文に対してアノテーションを行う場合は、privateに設定しておく場合が多いと考えられるが、複数人で1つの文書を分担して文書を閲覧したり、文書の翻訳情報などを共有したい場合は「share」や「public」が設定されるだろう。
タグやコメントを付与して保存ボタンを押すと、[annotator]の右側の一覧にアノテーションが追加され、さらにアノテーションされた論文の部分要素がハイライトされる。一覧では、アノテーション作成者、更新日時、コメント、タグが表示されておりアノテーション部分をクリックすると文書の中のアノテーションされている箇所に左の文書画面がスクロールする。逆に、ハイライト箇所をクリックするとハイライト箇所へのアノテーションが、ポップアップして右側に表示される。同じ部分要素に対するアノテーションが複数存在した場合、それらのアノテーションが全て表示される。アノテーションのdetail部分をクリックするとアノテーションの入力フォームと同様の画面が現れ、入力したアノテーションの編集・削除が行える。

図3.10: アノテーションへのリプライ
また、reply部分をクリックすると他者の共有されたアノテーションに対してさらにアノテーションを行える。具体的には、他者の文書に対するコメントに対して、補足意見を加えたり、間違いを指摘するといった行為が行える。アノテーションに対してアノテーションが行われると[reply]に示すように木構造で表示される。この機能によりある文書の部分要素に関して複数人で議論することも可能となる。
3.4 文書作成支援
本節では、3.1節で述べたTDAnnotatorに登録した文書を含む、2章で述べたコンテンツクラウドに存在する多様なコンテンツを検索・参照・引用可能なエディタTDEditorについて説明する。TDEditorは[tdeditor]に示すように、主に3つの機能から成り立つ。
- アウトライン作成機能
- 作文機能
- コンテンツ検索機能
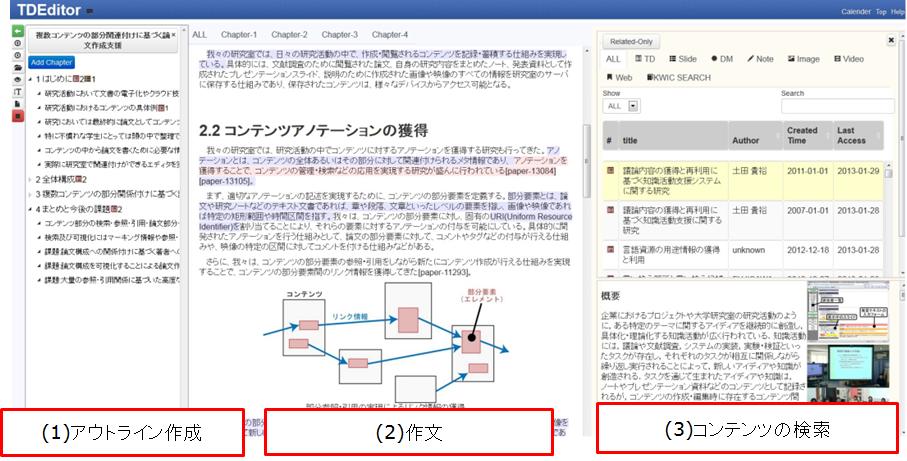
図3.11: TDEditorの構成
アウトライン作成機能は、一般的なテキストエディタに備えられているものと同様に、文書の構成を木構造で表現するものである。4章で詳細に述べるが、TDEditorでは、アウトラインに対してコンテンツを関連付けることが可能である。作文機能では、通常の文章編集機能に加え、3つめの機能により検索したコンテンツを必要に応じて作成中の文章内に引用することが可能であり、どのコンテンツの部分要素から引用されたかを記録する。
3.4.2 文書作成時のコンテンツの検索
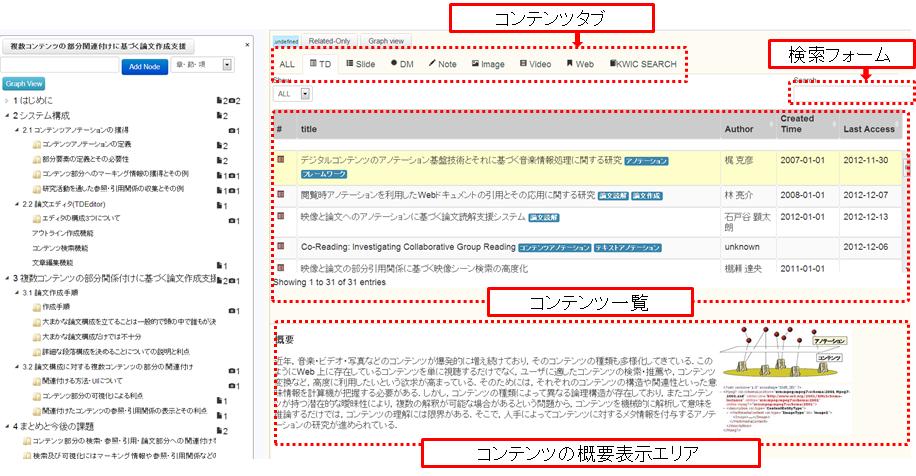
図3.12: 検索インタフェース
[search]にコンテンツの検索インタフェースを示す。インタフェース上では、ユーザが文書を作成するまでに、作成・閲覧してきたコンテンツの一覧がコンテンツの作成者・作成日時などのメタ情報と共に表示されている。コンテンツにタグが付与されている場合はタイトルの横にタグが表示される。また、タイトルの上にマウスを乗せると、インタフェース下部にそのコンテンツの概要やサムネイル画像が表示される。コンテンツの部分要素に対してアノテーションがされている場合、その部分要素の情報が優先的に表示される。作成者、閲覧日時などによるソート機能やキーワードによる検索も可能である。
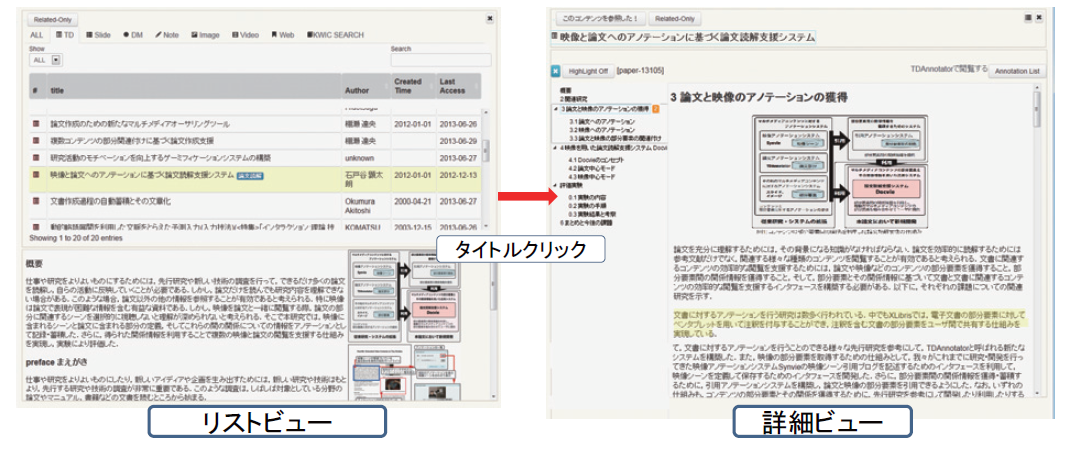
図3.13: リスト表示から詳細表示への切り替え
また、コンテンツは[search]の上部に示すように、コンテンツの種類によってタブに分けられており、タブをクリックするとそのコンテンツの表示に切り替わる。
[searchmode]に示すように、コンテンツのタイトルをクリックすると一覧表示から、クリックしたコンテンツの詳細表示に切り替わる。文書の作成者は、これらのコンテンツを参照し、必要に応じて検索した内容の一部を文章に引用しながら文書を作成する。参照・引用する部分を探しやすいように詳細表示ではコンテンツのアノテーションの情報が表示される。コンテンツにより表示方法が異なるため、それぞれの表示方法について説明する。
検索インタフェース上にあるTDタブでは、TDAnnotatorに登録されている文書、Noteタブでは、iStickyにより作成された個人研究ノートの文書が表示される。[paperinfo]に論文の詳細画面を示す。画面右側にはこの文書に対するアノテーションの一覧が表示されている。具体的には、論文の部分要素とそれらに付与されたタグ及びコメントが表示される。これらのアノテーションを閲覧することで、著者は、この文書がどのようなものであったのかを想起することできると考えられる。また、アノテーションには、アノテーション先のページ番号が表示されている。画面左に表示されているページ番号の該当する部分をクリックすることで、[changeview]に示すようにそのページの内容が表示されるため、アノテーション箇所だけでは、理解できない場合にそれらの前後の情報を閲覧することも可能となる。また、左のページ数の横には、そのページ番号に含まれるアノテーションの数が表示されており、どのページに対して集中的にアノテーションがされているのかを直感的に知ることが可能となる。
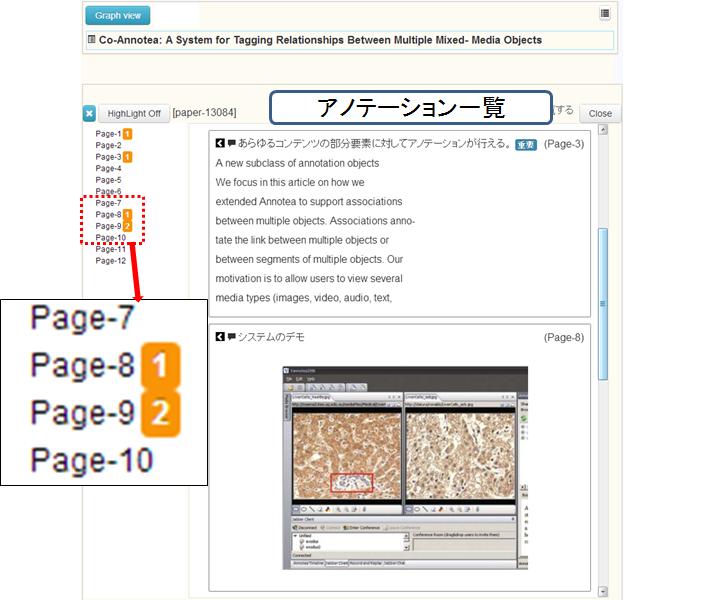
図3.14: 文書のアノテーション一覧表示
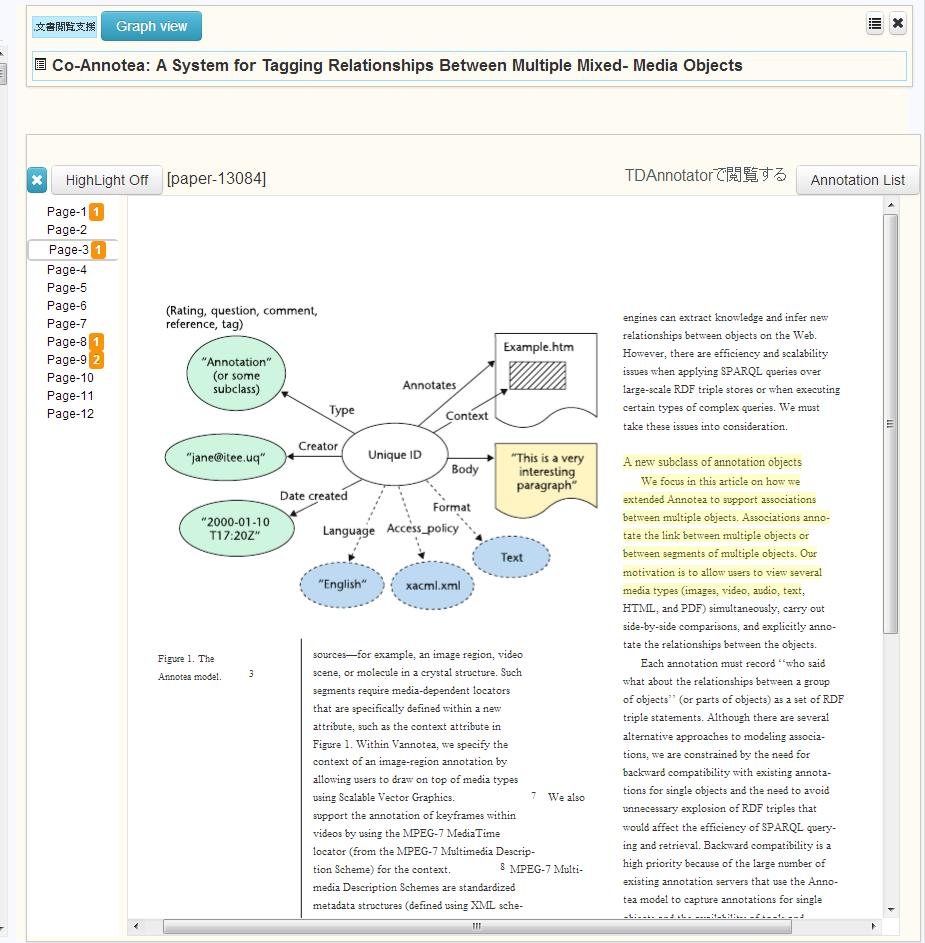
図3.15: アノテーション部分のTDEditor上での閲覧
2.1節で述べたSharvieにアップロードされた映像コンテンツを検索し、文書の作成時に視聴することが可能である。また、必要に応じて文書の中に映像を埋め込みむことできる。近年、電子文書の中に、映像が埋め込まれることは珍しくなく、ACM[http://www.acm.org/]などは論文と共に映像も同時に投稿される場合も存在する。[videoq2]に示すように、映像を文書に埋め込むことで、文書の閲覧者に直感的に著者の伝えたい内容を伝えることが可能となるため、今後も映像が埋め込まれた文書は増加していくと考えられる。
図3.16: 文書への映像の埋め込み
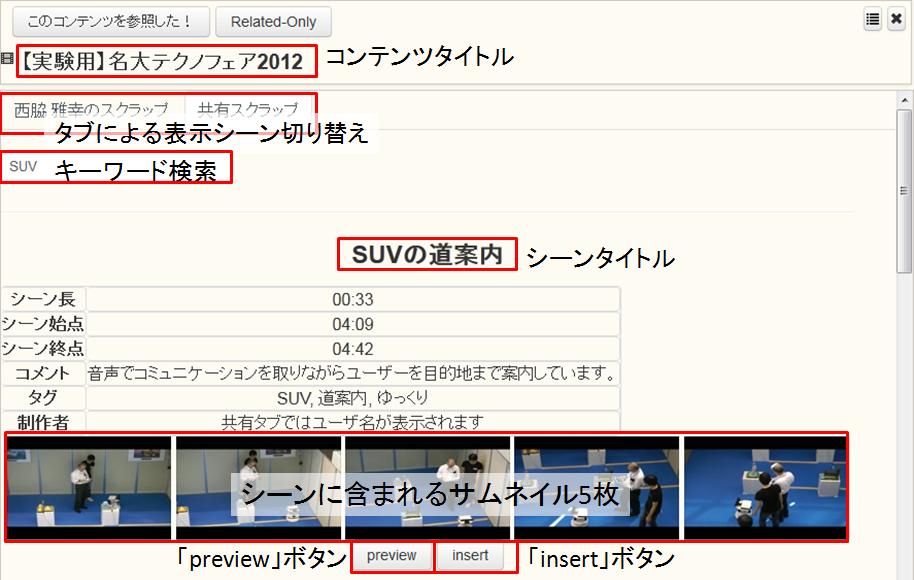
図3.17: アノテーションされた映像シーンの表示
2.1節で述べたように、Sharvieでは、特定の時間区間に対してアノテーションが行える。TDEditorの映像詳細表示では、文書作成前にあらかじめ特定の時間区間のシーンに対してアノテーションしてある場合に、それらのシーン情報が表示される。具体的には、[videoq]に示すように、該当するそのシーンの開始・終了時間やサムネイル画像が表示され、プレビューボタンを押すことでそのシーン区間のみを再生することができる。再生時間の長い映像の場合は、あらかじめシーンとしてアノテーションをしておくことで、文書作成時に効率的にそのシーンを検索することが可能となる。
TDEditor上では、コンテンツクラウド上に存在する発表資料であるパワーポイントファイルを検索することが可能である。[slides]に発表資料の詳細表示画面を示す。過去の発表の議論や反省を踏まえたTODOや課題をまとめた文書を作成する際に、このような発表資料の検索が必要になると思われる。また、同じ研究グループ内で共有されている発表資料も検索可能となっているため、他者の研究の中で、自身の研究に参照・引用できる内容を探す際にも、発表資料の検索は有用であると考えられる。
画面左側にはパワーポイントのスライドのサムネイル画像の一覧が表示され、画面右側にはフォーカスしているスライドの拡大画像が表示される。2章で述べたDMシステム上で発表に用いられたスライドの場合は、DMシステム上で収集されたアノテーションの情報が表示される。[slides]では、DMシステムの中でマーキングされた発言がスライドに関連付けられて表示されており、表示中のスライドでどのような議論が行われたのか想起できるようになっている。また、マーキングされた発言から、後述する議事セグメントの詳細画面に遷移することもできる。DMシステム上でポイントされたスライド要素やポインタ情報を含む発言テキストを表示するといったことも実現可能である。
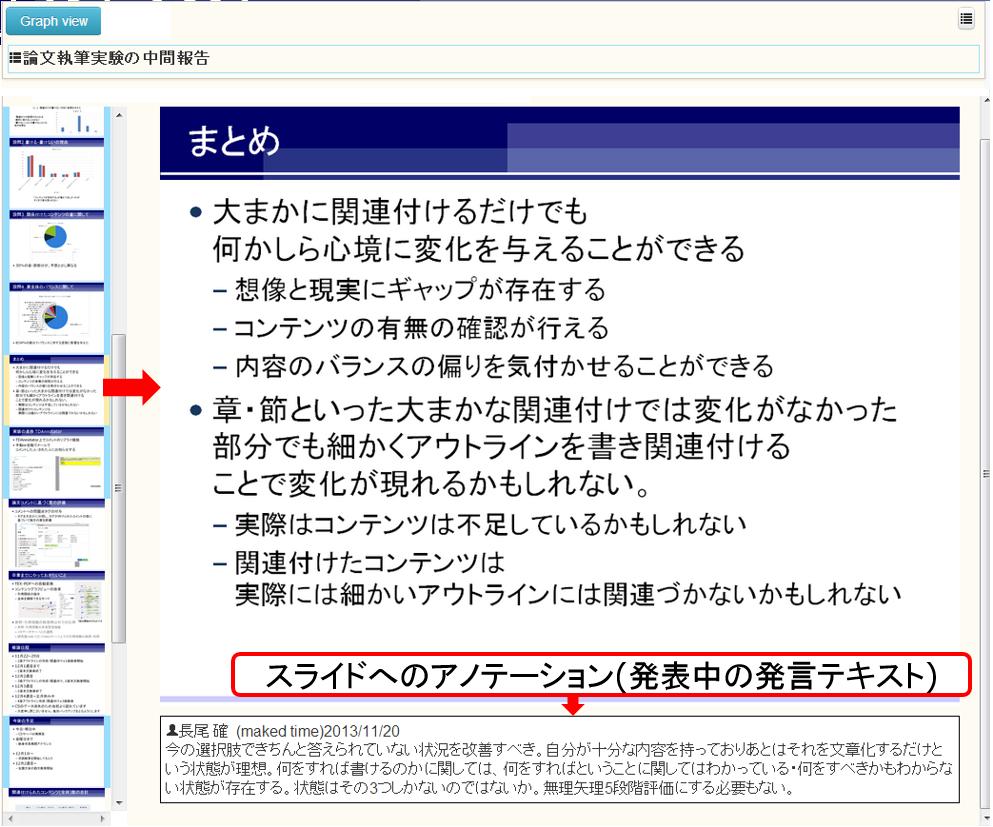
図3.18: 発表資料の詳細表示
2章で述べたDMシステムで記録された議事録を検索することも可能である。2章で述べたDRIPシステムと同様に、過去の発表の議論内容を踏まえてTODOや議論内容を文書としてまとめる際に、議事録を参照する、といった場合が考えられる。[dmsearch]に、議事録コンテンツの詳細画面を示す。画面上では、議論セグメントの一覧が表示される。デフォルトでは、導入発言のみが表示されており、導入発言をクリックすると、それらに付随する継続発言が閲覧できる。文書の作成者によってマーキングされている発言が存在する場合は、その発言が含まれる議論セグメントが最初から全て表示される。実際の議論の様子まで閲覧したい場合は、DMBrowserへのリンクをクリックすることで対応する議論の映像を視聴することが可能である。
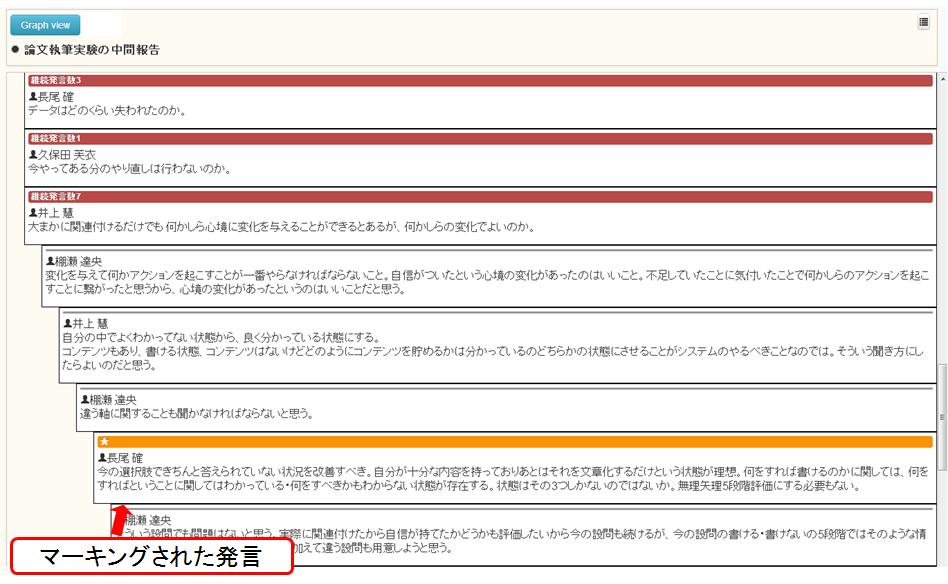
図3.19: 議論セグメントの検索
3.4.3 文書作成時のコンテンツの部分参照・引用
TDEditor上では、3.2.1項で説明したコンテンツを参照・引用しながら文書を作成することができる。本研究では、参照は、コンテンツを閲覧する行為、引用は、紹介・論評やその他の目的で、自己の著作物中に他者及び自身の著作物の原則として一部を転載する行為として定義する。
Webドキュメントや論文などの文書の引用の記述形式には、サイテーション(Citation)とクオテーション(Quotation)の2種類が存在する。一般に,サイテーションとは関係する文献や資料自体を参照記述する記述形式を指し、クオテーションは書かれたものの一部を一言一句そのまま記載する記述形式を意味する。現在、論文のような文書において見られるほとんどの記述形式はサイテーションである。サイテーションは引用箇所を引用者が要約して記述することが可能であるため、引用文書の文脈に合わせて適切かつ簡潔に引用することが可能である。つまり、サイテーションは文字数の制限がある投稿論文のような文書に適した記述形式であると言える。しかし、サイテーションによる記述にはいくつかの問題点がある。まず、[citequote]のように、サイテーションによる引用は、引用元文書のどの主張部分について言及しているのか明示的に示されないため、引用元文書全体に対するポインタを表現していると言える。通常、引用元文書の出所に関する情報は、巻末の「参考文献」のような項目に著者、文献名、出典、日付を用いて記述されることが多い。しかし、文書によっては数十ページに及ぶものもあり、引用している主張部分がその一部の数ページということもあり得る。つまり、サイテーションのような記述形式では、引用元の出所を明確に示すことはできない。そのため、サイテーションは引用先文書と引用元文書の関係を曖昧に記述する結果となっている。また、サイテーションの引用先文書の引用部分は引用者により要約されるため、引用元文書の著者の意図とは違った意味で引用してしまう可能性がある。つまり、引用元文書の主張を誤って解釈・記述してしまう可能性がある。
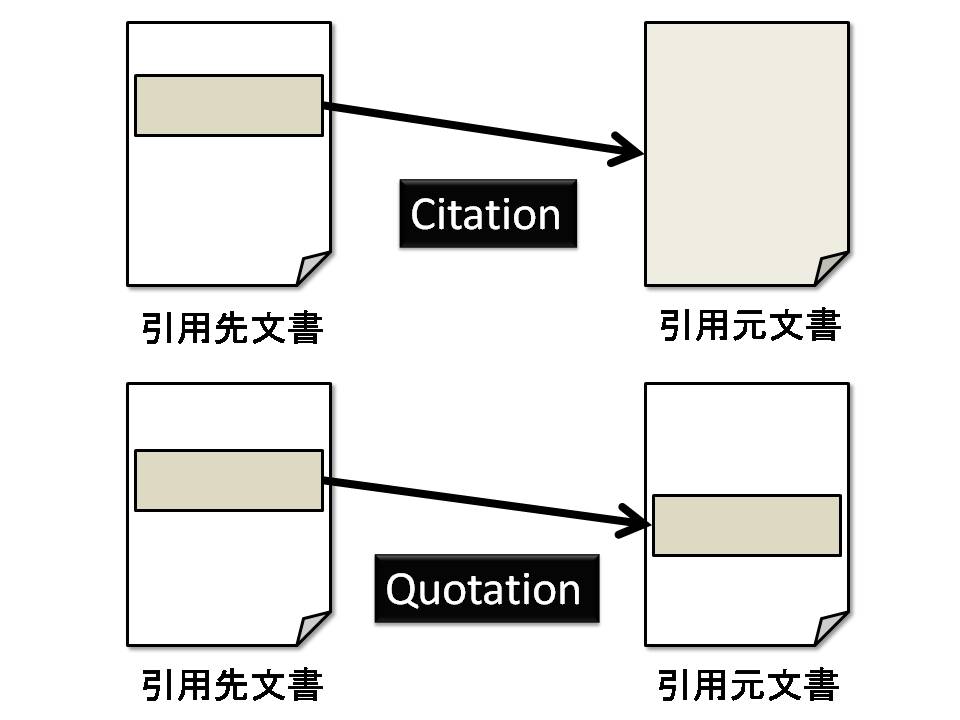
図3.20: サイテーションとクオテーションによる文書間の関係
一方、クオテーションの引用部分には引用元文書の文章の一部が一言一句そのまま記載されるため、引用元文書のどの主張について言及しているのか明確であり、また、誤って文章を解釈し記述する危険性は低い。つまり、[citequote]のように引用先・引用元文書の部分箇所間の関係を記述している考えることができるため、サイテーションに比べクオテーションは引用先・引用元文書の関係を明確に記述することが可能な形式であると言える。しかし、クオテーションは現在の文書においてほとんど使用されないことからも分かるように、引用者にとって適切でない場合が存在する。例えば、「システムの概要」のような引用したい主張が章全体のように文書の大部分にまたがる場合、クオテーションにより引用するのは冗長である。現状では、一文のように非常に短い文章に限り、クオテーションによって引用されることが多い。また、引用元文書の記述が引用先文書で記述したい文脈に適さない場合も存在することから、クオテーションは引用先文書の文脈に合わせて適切かつ簡潔に引用することが困難な記述形式である。
上記のように、クオテーションの方がサイテーションに比べ、引用先・引用元文書の関係を詳細に記述することが可能であり、引用者の意図を明確に伝えることができる記述形式であると言える。しかし、クオテーションは引用先文書の文脈に適した形で簡潔に引用することが困難であるため、現状ではほとんど利用されていない。つまり、求められる引用の記述形式はサイテーションのように引用先文書の文脈に適した形の柔軟な引用が可能であり、クオテーションにように引用元文書の主張部分に対する明確なポインタの記述が可能であることが望ましい。
そこで、TDEditorにおける作文機能はHTMLのWYSIWYGエディタとして設計した。HTMLに含まれるタグの属性に引用元のポインタ情報を記述することが可能であり、それらの情報は引用時に自動的に編集中のテキストに埋め込まれるため、サイテーションのような柔軟な記述方法を実現しつつ、クォーテーションのような引用元の文書を明確に示すことを可能としている。以下、本研究では、引用元の部分要素へのポインタ情報を保持した引用を「部分引用」として定義する。部分引用が行われたHTML文書がTDEditorからコンテンツクラウドに送信される際に、システムはHTMLのタグに含まれるポインタ情報を解析し、引用関係を双方向のリンク情報としてデータベースに記録する。すなわち、通常では行えない引用元の文書から引用先の文書へのリンク情報を取得することも可能である。
また本研究では、文書以外の画像や映像といったコンテンツの部分引用も実現している。画像や映像の文書への埋め込みは、埋め込まれた画像や映像の出所に関する情報は明記されないことも多いが、TDEditor上で検索可能な画像や映像を文書に埋め込む場合は、それらの情報は保持されるため、引用の一種として扱う。
コンテンツの部分引用の仕組みの利点は以下のとおりである。
本仕組みは引用元・引用先に対するポインタ情報を保持しているため、引用箇所と被引用箇所の文章表現が異なる場合にも引用構造を失わない。そのため、引用者はサイテーションのように引用箇所を自身の言葉で要約して記述することが可能である。作成する文書の閲覧者に引用元の情報に明示的に示すことにより、著者の主張を支える根拠や引用元との関連性を文書の閲覧者に明確に示すことができる。また、文書作成から時間が経ち著者自身がどの部分を引用したのか忘れてしまった場合でも、著者がは容易に引用元にアクセスすることができる。故に、著者はどのように意図で自身が引用を行ったのか容易に想起することができる。
通常、閲覧者は引用情報を引用先文書側からしか参照することができないが、本仕組みでは引用を引用先・引用元文書に対する双方向リンクとして表現するため、引用元文書側からの参照が可能である。また、後述する、作成した文書を閲覧する仕組みでは、引用をハイパーリンクとして表現するため、閲覧者は煩雑な作業をすることなく引用元・引用先文書の該当箇所にアクセス可能である。
本仕組みでは、引用情報を文書情報とは別にアノテーション情報としてデータベースに一元的に管理する。そのため、従来のように文書内のテキストを言語処理することなく、計算機を用いて引用情報を分析することが可能である。言語処理により引用関係を取得するParsCit[http://aye.comp.nus.edu.sg/parsCit/]などのツールは既に存在するが、本仕組みを用いることで、文書作成時に正確な引用関係を取得することが可能となる。
部分引用の仕組みには以上のように、多くのメリットが得られる。次に、具体的な部分引用の方法について述べる。
コンテンツの部分引用は、テキストの場合はコピーアンドペースト、画像や映像の場合はドラッグアンドドロップといった直感的な操作で行える。[quotetext]に論文部分を引用時の画面例を示す。引用したい部分をマウスで選択し、右クリックメニューのquoteを選択することでクリップボードに引用するテキストが保持される。引用したら中央のテキストエリアにCtrl+vまたは右クリックからpasteを選択することで引用が行える。ペーストされたテキストはハイライトされて表示されており、どの部分が論文の引用されて記述された部分が視覚的に分かるようになっている。引用部分は編集可能となっており、ハイライト部分が失われない限り、引用元のポインタ情報は保持される。論文のテキスト以外にも、研究ノートのテキスト部分や議論セグメントの発言テキスト部分を引用することも可能である。また、[quoteimage]に示すように、文書に含まれる画像の引用を行うことも可能であり、文書に埋め込む場合はドラックアンドドロップにより行える。画像や映像の引用は、このような文書の中に埋め込む形式ではなく、テキストの部分引用と同様に、画像や映像へのリンクを持つテキストとして文章に埋め込む形式でも行える。
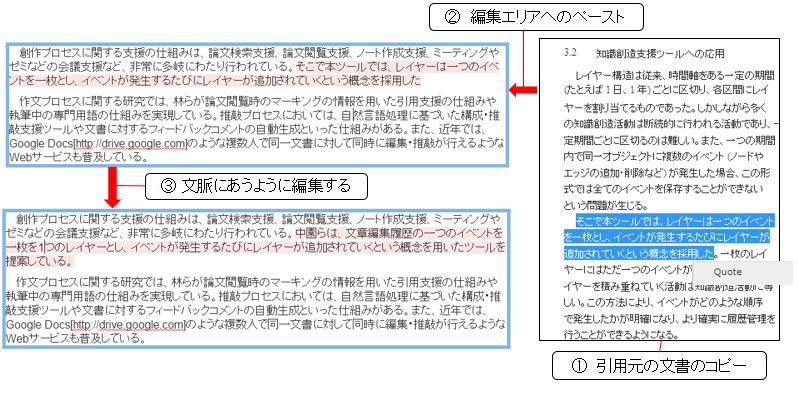
図3.21: テキストの部分引用
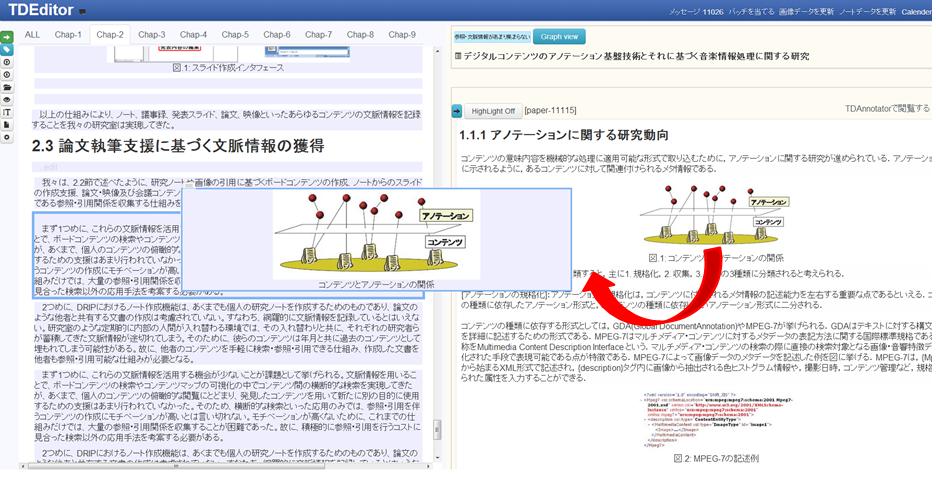
図3.22: 文書に含まれる画像の引用
本仕組みで実現する部分引用は、コピーアンドペーストといった手軽な操作により引用が行える。手軽であるがゆえに、一度に大量の文章が引用され、そのまま引用元の文章が編集されないことも考えられる。しかし、著作権法についての最高裁判所昭和55年3月28日の判例[http://www.courts.go.jp/search/jhsp0030?hanreiid=53283&hanreiKbn=02]において、引用先が「主」、引用部分が「従」の関係にあることが引用の条件とされている。つまり、引用部分は質的にも量的にも従属的なものであり、本文を主とするならば引用部分は従たる関係でなくてはならず、引用部分の分量が多い文章は著作権法の観点から見ても好ましくないと言える。コピーアンドペーストによる操作は、このような通常の引用としては不適切な引用を助長する可能性がある。故に、他者の著者物であるコンテンツに含まれる大量の文章を一度に引用する際は、一定の文字数以下に文章を減らすことをシステム側で促すなど配慮する必要がある。一方で、自身の著作物であるコンテンツや同じグループ内で共有されているコンテンツを文書に再利用(使い回す)することは特に問題ないため、引用元の著作物の情報によってそれらの仕組みを切り替える必要がある。また、文書の引用情報は原則公開されるべきものであるが、研究グループ内での文章表現や図の再利用の記録など公開すべきでない情報は、公開範囲を設定できるようにするなどの配慮が必要となる。
TDEditorにはコンテンツから直接引用するのではなく、閲覧時のアノテーションの内容を文書内に引用することで間接的にコンテンツを引用する方法がある。論文の表現を直接コピーアンドペーストにより引用するよりも、TDAnnotatorでの文書へのアノテーションの際に付与したコメントの方が、自身で記述した内容であるためそのまま文章の中に引用しやすい場合がある。例えば、ある論文の部分要素に対する要約や翻訳のテキストがアノテーションとして付与されていた場合は、コンテンツを直接引用するよりも、アノテーションのテキストを引用する方が編集コストの面において効率が良い。このように、閲覧時のアノテーションが多いユーザほど、効率的に文書が作成できるように設計されている。具体的な引用インタフェースを[annoquote]に示す。アノテーションから引用したテキストも、コンテンツから直接引用する際と同様に、作成する文章内で編集が行え、HTMLのタグにはアノテーション先の部分要素へのポインタ情報が埋め込まれる。
図3.23: 閲覧時アノテーション時のコメント文の引用
引用元へのポインタ情報が引用先のテキストに埋め込まれているため、編集中にどの部分から引用を行ったのか辿ることができる。[source]に示すように、編集中のハイライトされている箇所を右クリックしてsourceを選択すると右のコンテンツ検索画面に引用元のコンテンツが表示され、さらに、引用部分がハイライトされる。文書の作成期間が長期にわたる場合や、引用元の文書の量が膨大である場合は、引用箇所を忘れてしまう可能性が高いが、この機能を用いることで、容易に引用元にアクセスすることが可能となる。
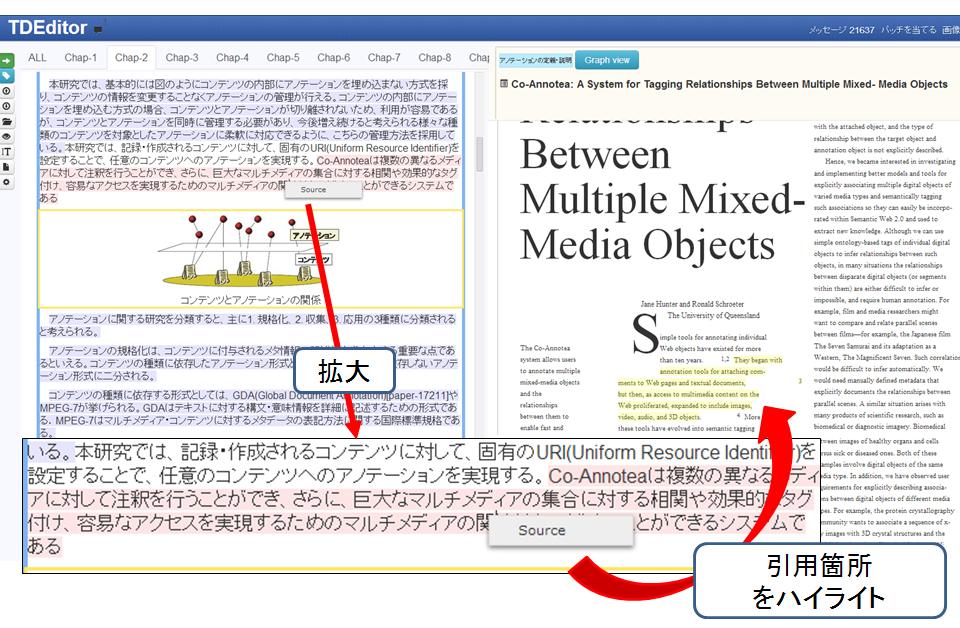
図3.24: 引用元へのアクセス
3.4.4 作成文書の閲覧
TDEditor上で作成した文書は、コンテンツクラウド上で、部分引用情報と共に管理される。TDEditor上で作成されたHTMLの文書を解析し、著者・タイトル・章・節・段落などの意味情報や構造情報と共にデータベースに保存されるため、TexやHTMLなど様々な文書に変換可能となっている。
作成された文書は、TDAnnotator上で、投稿されたPDF形式の文書と同様に管理・閲覧され、同時にTDEditor上での検索・引用も可能となる。作成された文書のTDAnnotator上での表示画面を[secanno](左)に示す。構造情報を持った文書であるため、章・節・項・段落といった構造単位でアノテーションを行うことが可能となっている。[secanno](右)では、文書のある項に含まれる見出しに対してアノテーションを行っている。アノテーションしたい部分が、特定のテキスト範囲ではなく、章・節・項などの広範囲にわたる場合にこの仕組みは有用となる。また、文書の中で部分引用が行われている場合は、[quoteinfo]に示すようにアノテーション一覧に引用情報が表示される。引用情報の画面には、引用元のテキストやサムネイル画像が表示されている。また、引用元の文書を閲覧したい場合は、アノテーションに含まれるタイトルをクリックすると引用元のコンテンツが表示される。これにより、文書の閲覧者は容易に文書の引用元にアクセスすることが可能となる。引用情報は閲覧時のアノテーションと同様に公開範囲設定や編集・削除が行える。
図3.25: 構造全体(図はある見出し)に対するアノテーション
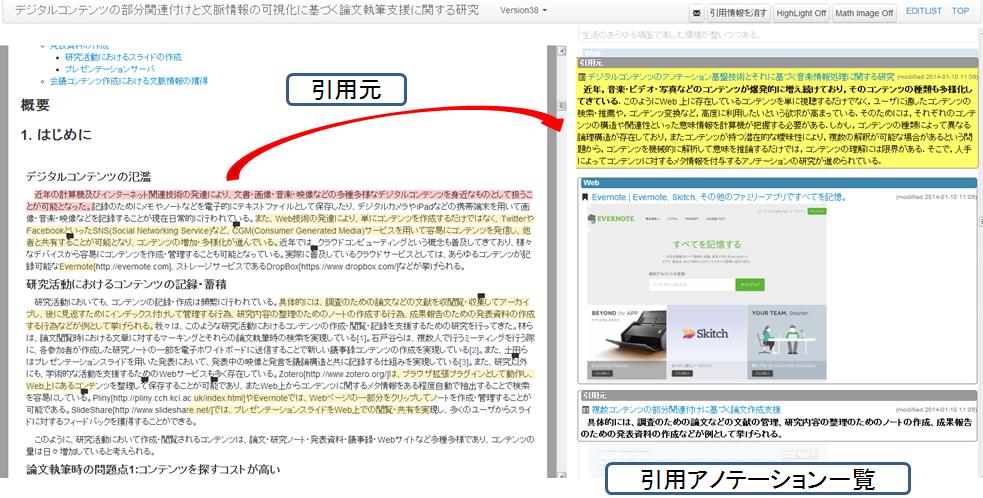
図3.26: 引用アノテーションの表示

図3.27: 被引用情報の表示
さらに、前述したようにデータベース上には、コンテンツから独立したアノテーションとして部分引用関係が保存されるため、引用元の文章を閲覧する際に、[quoted]に示すように、被引用情報をアノテーションとして表示することが可能となる。すなわち、引用先・引用元の文書の双方向にアクセスすることができる。通常の文書では、引用元である過去の文書を辿ることしかできないが、この仕組みにより、閲覧中の文書から引用先の文書を辿ることが可能となる。引用先の情報を辿ることで、その文献に比べてより新しい情報に容易にアクセスすることができると考えられる。
このアウトラインは削除
本章では、文書閲覧時の文書へのアノテーションの仕組み、文書作成時における、アノテーションに基づいた多様なコンテンツの検索・参照・引用の仕組み、部分引用に基づくコンテンツの文脈情報の収集の仕組みについて述べた。次章では、これまでに述べた研究活動において収集される文脈情報を論文執筆時に応用する仕組みについて述べる。
4 コンテンツの部分関連付けと文脈情報の可視化に基づく論文執筆支援
本章では、3章で述べた文書作成時に獲得した部分引用関係と、2章で述べた既存の研究活動支援ソフトウェア及びシステムから獲得した部分引用関係を利用して論文執筆を支援するための手法について述べる。その中で、以下に述べるような新しい論文執筆の手法を提案する。
- 論文のアウトライン(章・節・項・段落構成)を決める
- アウトラインに対してコンテンツの部分を関連付ける
- アウトラインの項目ごとの内容の文章を執筆する
- 指導者などの指摘に基づき論文を推敲する
論文アウトラインの作成は一般的に行われている行為である。本研究では、章・節・項といった文書構造に加えてさらに、段落構成までアウトラインの項目として記述できるようにした。手順2におけるコンテンツの関連付けとはアウトライン項目ごとにどのような情報が必要であるか整理する行為をシステムで支援するものである。手順3はアウトライン項目の内容を実際に論文に載せる文章を執筆していく作業であり、全てのアウトラインの内容の文章を埋めることで論文の初稿が完成する。手順4は、共著者や指導者などからコメントをもらうことで、多様な視点から著者の草稿を見直すことが可能となり、論文のクオリティの向上につながる。以下で、これらの手順について詳細に説明する。なお、これらの論文執筆支援の仕組みは3章で述べたTDEditorの中で実現される。
4.2 アウトラインの作成
論文執筆は一般的に、大まかなアウトラインである章・節・項を考えるところから始められる。このように章・節・項を考えることで、著者はどのような論理構成で文章を執筆していくのかを整理する。これらのアウトラインは論文の一部として他者からも閲覧される部分であるため、非常に重要な作業である。本研究では、これらの大まかな章・節・項に加え、段落アウトラインの作成まで支援する。[outline]に段落アウトラインまで記述された論文アウトラインの例を示す。フォルダのアイコンが付与されているものが段落アウトラインである。大まかなアウトラインを作成するだけでは、実際に文章を書いてみると何を書けばいいのか分からない場合が多いため、段落構成まで決めることでより詳細に論文に書くべき内容を整理する。酒井はその著書[18]の中で、段落アウトラインの作成は情報を整理する上で有効であると述べている。また、段落アウトラインは論文の一部として公開されることはないが、同じ研究グループや指導者が閲覧する際に、著者が文章の中で何について述べようとしているのか理解する上で有益な手掛かりとなる。

図4.1: 段落構造まで記述した論文アウトライン
最初から完璧な論文アウトラインを作成することは難しい。初期段階におけるアウトラインの作成時または文章の執筆中にアウトラインは頻繁に編集される可能性がある。そのため、本研究では容易にアウトラインの編集が行える機能を実装した。[outedit]に示すように、TDEditor上ではアウトライン項目の追加・削除・移動・結合・複製が行える。アウトラインの移動に関しては、右クリックによる操作の他に、[outmove]に示すようにドラッグアンドドロップによる編集も行える。
図4.2: アウトラインの編集

図4.3: ドラッグアンドドロップによるアウトラインの移動
4.3 アウトラインへのコンテンツの部分関連付け
アウトライン作成は、研究活動の中で著者が蓄積した自身のアイデアや研究成果などを取捨選択し、木構造として表現する作業である。しかし、論文執筆までに研究活動の中で蓄積された情報は膨大である。故に、特に論文執筆に不慣れな学生などは、それらの情報のどの部分が論文に必要な部分であるのか、どのようなアウトラインが適切なのか自身で判断することが難しい。その結果、論文の文章を執筆するか他者に指摘されるまでそのアウトラインの矛盾や内容の不足に気付くことができず、後で大幅な修正を加えなければならないことになり、効率的な論文執筆が行えるとは言えない。そこで、本研究は論文執筆に必要な情報が含まれると考えられるコンテンツをアウトラインに関連付ける仕組みを提供することで、著者にアウトラインの妥当性を判断させる仕組みを実現する。
関連付けの仕組みは、TDEditorの中で論文に必要な情報が含まれるコンテンツを検索し、必要な部分要素をドラッグしてアウトライン項目名に対してドロップすることで行える。著者は、3章で述べたTDEditor上で検索可能なコンテンツ(の部分要素)を関連付けることができる。コンテンツ全体を関連付けたい場合は、[wholea]に示すように、コンテンツ表示画面のコンテンツタイトル部分をドラッグアンドドロップすることで関連付けることができる。コンテンツの部分要素を関連付けたいときは、そのコンテンツの形式によって関連付けの方法が異なる。
図4.4: アウトラインへのコンテンツ全体の関連付け
TDAnnotatorで登録した文書やTDEditorで作成した文書の部分要素を関連付ける際は、[paperassociate]に示すように、特定のPDFのページ、画像・表、TDAnnotatorで付与したアノテーション、選択した文字列範囲を関連付けることが可能である。
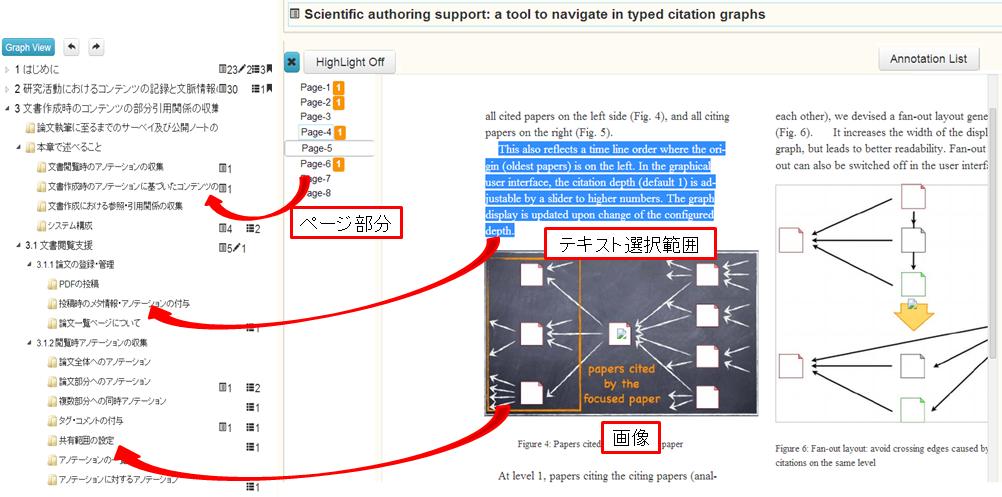
図4.5: 文書部分の関連付け
iStickyで作成した研究ノートの場合は、[contentassociate]①に示すように指定した行及び選択範囲を関連付けることが可能である。複数行をまとめて関連付けることも可能である。

図4.6: 様々なコンテンツ部分の関連付け
発表資料であるプレゼンテーションスライドは、[contentassociate]②に示すようにスライド一枚ごとを関連付けることができる。そのスライドに含まれるテキストや画像要素を関連付けることもできる。
2章で説明した議事録コンテンツの発言テキストは[contentassociate]③に示すように関連付けることができる。
ブックマークレットによりマーキングしておいたWebブックマーク関連付け
他にも[contentassociate]③④のように、議事録や映像コンテンツの一部分などを関連付けることもできる。関連付けられるコンテンツの種類や部分要素の単位は今後ユーザからのフィードバックに基づき拡張していく予定である。また、どのコンテンツでも[hlacontent]に示すように、いずれかのアウトラインの項目に関連付けられている部分は青色でハイライトされるようになっている。ハイライト箇所をクリックするとどのアウトライン項目に対して関連付けられているか表示され、そこから関連付けを解除することも可能である。
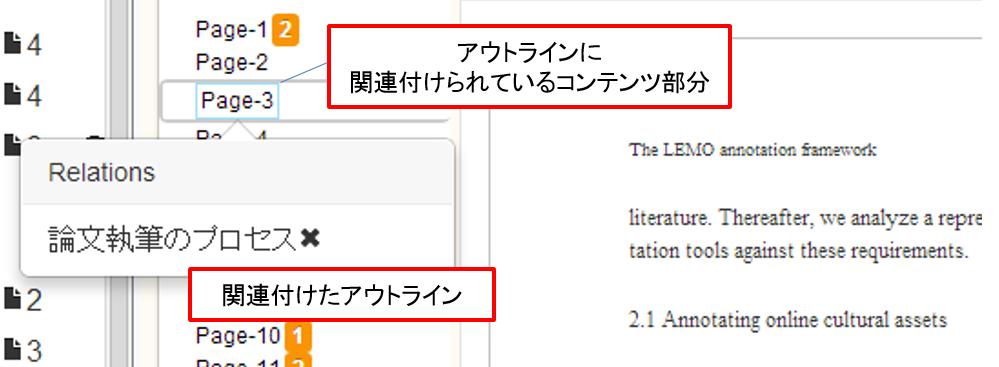
図4.7: 関連付けられたコンテンツ部分のハイライト
アウトラインに対して関連付けを行うと、[icon]に示すように関連付けられたアウトライン項目のタイトルの横にコンテンツの種類を示すアイコンが付与される。アイコンの横の数字はコンテンツ(全体)の数を表している。(同じコンテンツに含まれる部分要素を複数関連づけてもアイコンの数は変化しない)。コンテンツをこのようにアイコンを表示することで、直感的に、どのアウトライン項目に対して論文の材料となるコンテンツが存在しているのか把握することが可能となる。また、アウトラインに対して関連付けられるコンテンツが存在しないことで、論文に必要な情報が不足していることに気付くことができる。その場合、著者は、文献調査・実験・他者との議論などを行うことで不足した部分のコンテンツを補うことになるだろう。また、あるアウトライン項目に関連付けられたコンテンツの数が他のアウトライン項目と比較して著しく多い場合、著者がアウトラインに書く内容の偏りに気付くという可能性も考えられる。著者に対し、偏りに気付かせることで、アウトラインをより詳細に分割したり、他の章にそのアウトライン項目を移動させるなどの編集を促す効果が期待できる。

図4.8: コンテンツアイコンの表示
アウトライン項目のタイトルをクリックすると、関連付けられたコンテンツが[associateresult]に示すように、TDEditorの検索インタフェースのリストの上位に表示されるようになる。コンテンツの部分要素を関連付けた場合は、コンテンツリストのタイトルにマウスカーソルを当てると関連付けた部分要素がインタフェース下部に表示されるようになる。[associateresult]の場合は、アウトラインに関連付けられたある論文の章の内容が表示される。
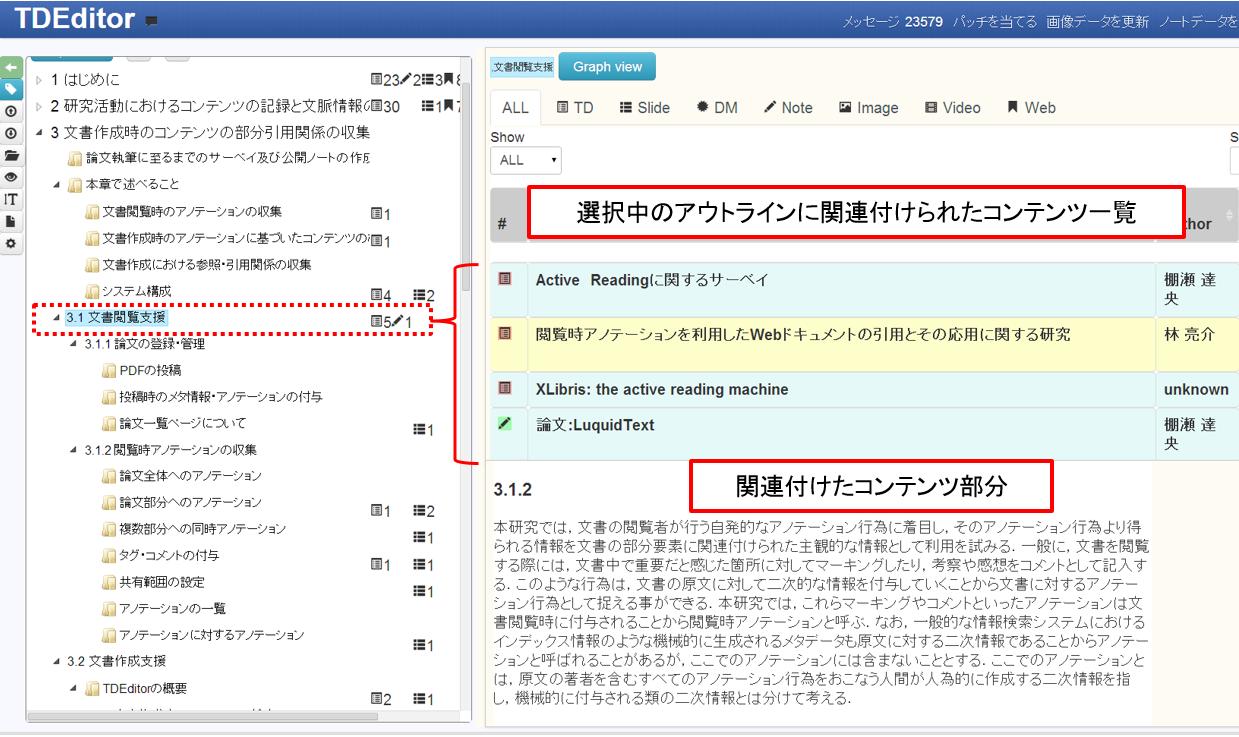
図4.9: 関連付けられたコンテンツの一覧表示
ここで、コンテンツを関連付けるアウトラインの順序について触れておく。関連付けの手順として、初期段階で段落アウトラインの項目まで記述してからコンテンツを関連付ける場合と、最初に章・節など大まかな作成したアウトライン項目に対してコンテンツを関連付け([outpattern]①)、その後より詳細に段落のアウトラインを記述し([outpattern]②)、さらにコンテンツを細かく関連付ける場合([outpattern]③)の2通りが考えられる。後者は、前者と比べると関連付けの回数が多いが、最初の大まかな関連付けにより、関連付けるコンテンツを大まかに絞り込むことで、後の詳細な段落のアウトライン項目を決定する際に参考にすることができる。初期の段階で段落アウトラインまで記述できるような場合は、関連付けの手間を考慮すると後者の手順が取られることはあまりないと考えられる。しかし、本研究では、論文執筆に不慣れな学生を支援の対象としている。そのような不慣れな著者は、初期の段階で段落のアウトラインまで記述することは困難である可能性が高い。

図4.10: ①大まかなアウトライン構成の作成・関連付け ②段落アウトラインの作成 ③段落アウトラインへ関連付け
後者の関連付けの手順で行う際の本手法での支援方法について述べる。[outpattern]の例では、2.1節に対して2つの論文(論文A全体、論文B全体とする)が関連付けられている。次に、その2.1節の段落のアウトラインに対して論文Aのある部分が関連付けられたとする。すると、2.1節に関連付けられたコンテンツの数が減るようになっている。もし、論文Bに関して、段落アウトラインの中で関連付くものがなければその論文Bは実際は執筆の中で必要ではないものとして削除の対象とすることができる。また、段落アウトラインに対して新たに論文Cが関連付けられる可能性もあるように、章・節のような大まかに関連付ける際には、必ずしも適切に関連付けがされるとは限らない。故に、[outpattern]の例のように段落アウトラインに対するコンテンツの関連付けを支援することで、執筆に不慣れな著者でも必要なコンテンツ部分を選択してアウトラインを整理することが可能となる。
4.4 グラフによる文脈情報の可視化
本研究では、関連付けられたコンテンツ(の部分要素)の量を直感的に把握できるようにするために、コンテンツ及びアウトライン項目をノード、関連付けや参照・引用情報をエッジとしたグラフ構造を表示するインタフェースを開発した。[graph]と[graphbig]にそのグラフ構造の表示画面を示す。[graphbig]では、アウトラインノードに対して論文の部分要素ノードとスライドの部分要素ノードを表すノードがエッジで結ばれている。部分要素ノードは、それぞれのコンテンツ全体のノードと結ばれている。画像やスライドなどのコンテンツの場合はサムネイル画像がアイコンの代わりに表示されている。ノードをクリックすると、[graph]に示されるインタフェースの下部にそのノードの情報が表示されるようになっている。また、この画面で関連付けの情報を解除することも可能である。このようにグラフを閲覧することで、コンテンツのアイコン表示やリスト表示では把握しにくい、関連付けられたコンテンツの部分を直感的に把握することができる。
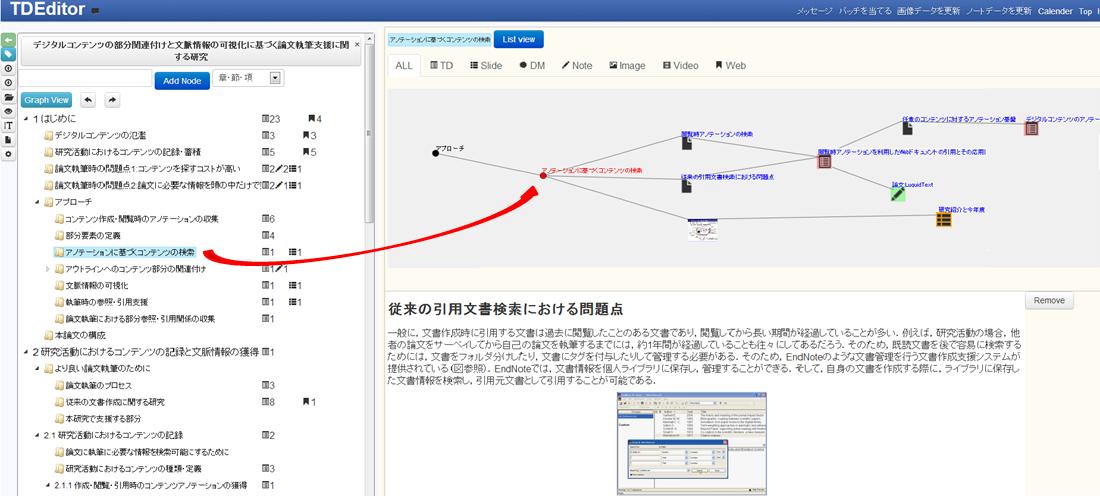
図4.11: グラフ構造表示
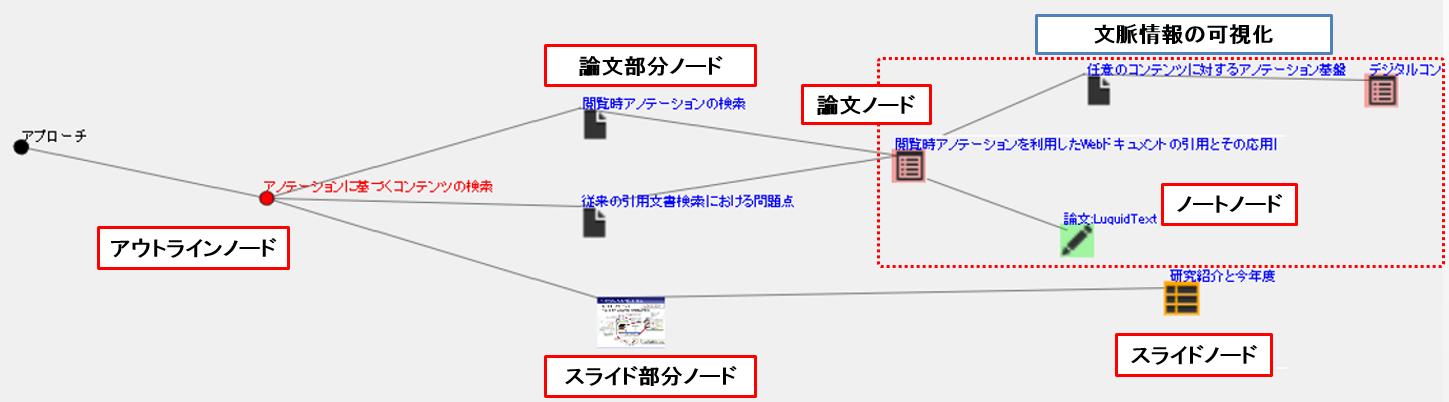
図4.12: グラフ構造表示詳細
さらに、[graphbig]上では、論文(全体)ノードからエッジで結ばれている論文部分ノードが存在している。これは2章と3章で述べたコンテンツの部分引用関係に基づいて提示されているコンテンツの文脈情報である。この場合は、関連付けられた論文の引用元のノートと論文部分が表示されている。このように最初にアウトラインに関連付けたコンテンツを起点とし、部分引用関係を辿ることで、新たなコンテンツを発見することが可能となる。
現在はコンテンツ全体の単位でアウトラインノードからの距離が2までのノードを表示しているが、部分引用が継続的に行われている場合は、さらに深く過去のコンテンツまで遡ることも可能となる。コンテンツの作成・閲覧時から論文執筆までの間が長期に渡る場合、そのようなコンテンツは時間の経過と共に埋もれてしまい検索することが困難となってしまうが、このように部分引用関係を可視化することで過去のコンテンツを容易に発見できる可能性がある。
また、論文のアウトライン全体を木構造ではなく、[allg]に示すようにグラフ構造にして閲覧することも可能である。このように全体を俯瞰することにより、どのアウトライン項目に対してコンテンツが集中して関連付けられているか、逆にどのアウトライン項目があまり関連付けられていないのかを直感的に知ることが可能となる。ただし、関連付けられるコンテンツの量やアウトラインの数が膨大になると[allg]のような表示方法では非常に分かりにくくなるため、グラフに含まれる情報を要約して必要最小限の情報を提示する仕組みを提供することが今後の課題となる。
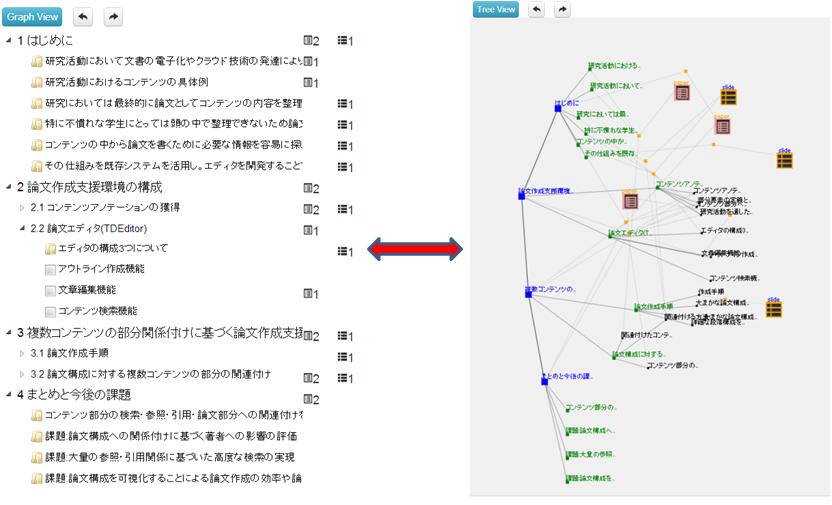
図4.13: 論文アウトライン全体のグラフ構造表示
4.5 執筆時のコンテンツの参照・引用
関連付けたコンテンツの情報は、論文の本文執筆時に容易にアクセスすることが可能となる。あるアウトライン項目の文章を編集しようとすると、そのアウトライン項目に応じて[interface]に示すように、右のコンテンツの表示が動的に切り替わる。これによって、一度コンテンツを関連付けてさえおけば、容易にそのコンテンツを閲覧することができる。
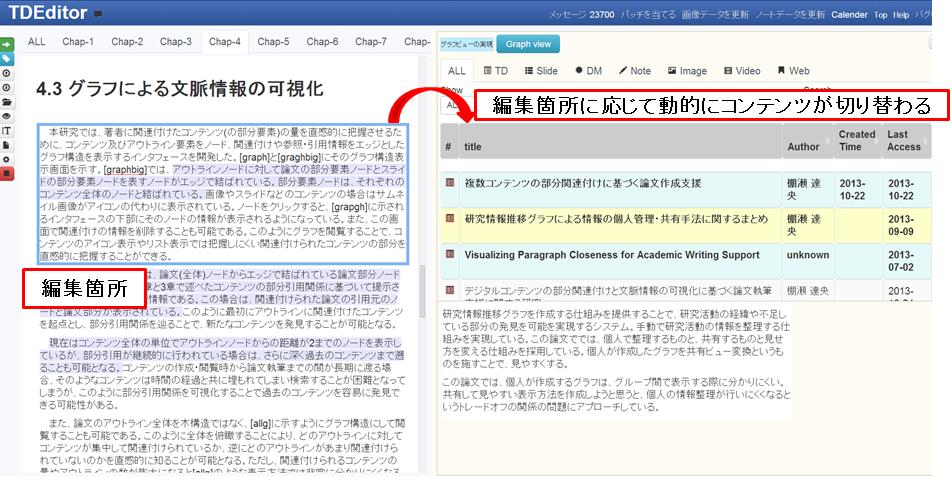
図4.14: 編集中のコンテンツの動的な切り替え
このように、あらかじめ関連付けたコンテンツを論文執筆中に著者に提示することで、コンテンツの部分引用を促進させる。論文のような、多くの情報を含むと考えられる文書の場合は大量の部分引用関係が収集できると考えられる。また、アウトライン項目へのコンテンツの関連情報に加えて、執筆中のコンテンツの検索履歴や操作履歴も記録として収集することが可能である。これらの記録を統計的に分析することで、執筆時におけるコンテンツの高度な検索や、関連付け情報や執筆内容に応じたコンテンツの推薦など様々な応用を実現できる可能性がある。
それらのコンテンツを文章作成時に必要に応じて論文の中に引用することで効率的に論文執筆を行うことが可能となる。文章中への引用行為は、その文章を含むアウトライン項目に対する関連付けの一種であり、関連付けられていない新しいコンテンツを文章の中に引用するとアウトライン横のアイコンの数が増える。アウトラインに関連付けた場合と実際に文章に引用した場合とでは、引用による関連付けの方が強い関連を持つと考えられるため、システム上では区別されて記録される。
4.6 フィードバックの収集
一般的に論文執筆では、共著者や指導者などからフィードバックとなる指摘をもらうことで多様な視点から草稿を見直すことで論文のクオリティの向上を図る。本提案手法では、TDAnnotatorの論文部分へのアノテーションの仕組みを拡張することにより指摘を収集する。また、TDAnnotator上では、TDEditor上で作成された章・節・項・段落構成を含む文書構造を閲覧可能となっており、アウトラインに対する指摘も行える。さらに、部分引用関係や関連付けの情報を提示することで、その論文の著者がどのようなコンテンツを参照・引用しながら論文を書いたのか他者に知らせることができる。
本システムでは、作成された論文への指摘を効率的に収集するために、論文校正用の属性・タグ・コメントを付与する仕組みを実現した。属性には「アウトラインに対する指摘」「スタイルに関する指摘」「内容に関する指摘」を付与することができる。「アウトラインに対する指摘」は、章・節・項・段落などのアウトライン項目に対してアノテーションを行われると自動的に付与される。スタイルに関する指摘は、語の表記揺れや誤字脱字など語彙・文法的なミスに対して付与されることを想定している。「内容に関する指摘」は、論文の表層的な部分ではなく、内容に深く関連する指摘である。さらに、同じような指摘を何度も入力させることを避けるため、論文の問題点に関するタグを用意した。用意されたタグの一覧を[problemstag]に示す。これらの問題点を表すタグは、我々の研究室の過去の論文に対して行われた指摘に基づいて作成した。このようにあらかじめ問題点となる内容をリストアップしておくことで、効率的に指摘が行える。

図4.15: 論文指摘用タグ
論文の著者は、TDAnnotator上で収集されたコメントを閲覧しながら、論文を修正する。TDEditor上で指摘コメントを閲覧することも可能である。指摘に対して、著者はリプライ機能を用いて、指摘者に修正内容や指摘に対する質問等を伝える。TDAnnotator上では、論文の著者及び指摘を行ったユーザに対してメールを送ることが可能となっており、メールには論文の文書へのURLが添付される。このように、著者と指摘者間でオンラインでコミュニケーションをとることで、効率よく修正していくことができる。
図4.16: 論文のバージョン管理
また、本システムでは、クラウドにアップロードされた文書は更新日時と共にバージョン管理されて保存されており、実際に論文がどのように修正されたのかを確認することができる。TDAnnotator上では、[revision]に示すように、どのバージョンに対してどれだけ指摘があったのかを確認することができるようになっており、どの状態でも再現して表示することができる。
本システムでは、[robust]に示すように指摘箇所の文章が修正された場合でも、以前のバージョンに対する指摘箇所に近い場所にアイコンが表示され、指摘があったことが分かるようになっている。アイコンをクリックすると指摘時の修正前のバージョンの文書を閲覧することができ、現バージョンとの差分を確認することができる。しかし、複雑な編集作業が行われると、元の文書には存在した文書の部分要素を示すポイント先が修正後に失われてしまうことがある。本仕組みでは、そのような場合、修正前と修正後で同一の段落アウトラインに含まれる文章であった場合はその段落アウトラインのタイトルの横にアイコンが表示される。ただし、修正の際に段落アウトラインの項目ごと削除されてしまった場合は、右のアノテーション一覧に表示されるようになっている。このようにアノテーション箇所が変更されてしまう際にどのようにユーザに表示すべきかという問題については、Bernheimら[19]が実験で検証しており、大幅な変更が加えられ探索が困難な場合の表示方法については、修正後の文章とは分離して表示しても、それがユーザにとっては最善である場合が多いと述べている。
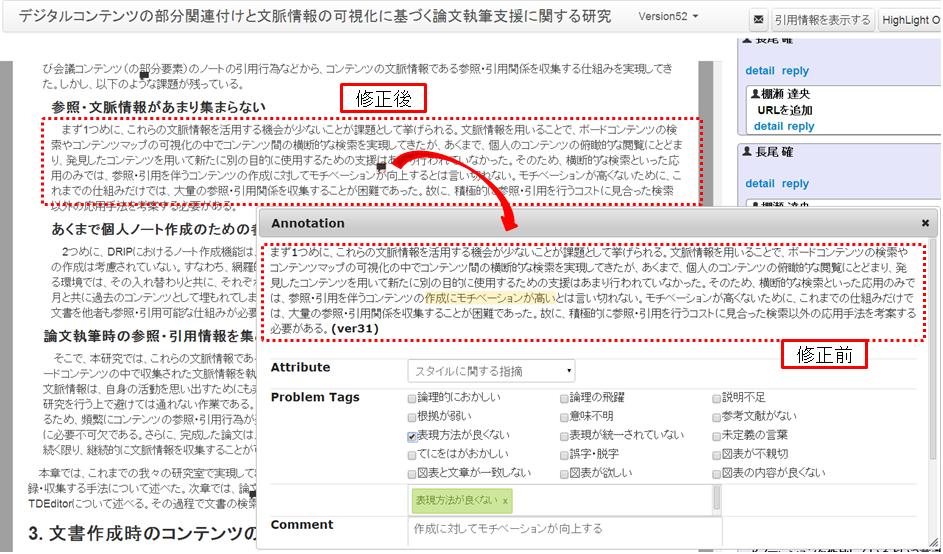
図4.17: 修正前のバージョンの指摘コメントの閲覧
このようにして収集された、論文に対する指摘の情報は、論文のバージョンが変わっても蓄積され続ける。これらの指摘は、単に論文の著者が推敲の参考にする以外にも有用である。例えば、TDEditor上で執筆・公開された論文を同じ研究グループの他者が閲覧・引用する際に、過去にどのような指摘がされてきたかを検索・閲覧可能にし、それらの指摘を参考にすることで、同様な指摘を受けることを防ぐことができる。
本章では、アウトラインに対するコンテンツの部分関連付けの仕組み、関連付けた情報を表示する際に3章までに述べてきた部分引用関係を文脈情報として可視化する仕組み、関連付けたコンテンツを参照・引用して論文を執筆する仕組み、参照・引用関係をグループ内で共有する仕組み、執筆した論文に対して他者から指摘をもらう仕組みについて説明した。次章では、本章で提案したアウトラインに対してコンテンツを関連付ける仕組みの有効性について検証するとともに、実際にTDEditorを通して収集された関連付けや引用関係について分析する。
5 コンテンツの部分関連付けに関する評価実験とデータ分析
前章では、論文のアウトラインに対してコンテンツを関連付ける仕組み、関連付けたコンテンツを実際に参照・引用しながら論文執筆を行う仕組みについて述べた。本章では、このアウトラインに対してコンテンツを関連付ける作業が実際の論文執筆においてどの程度有効であるのかを検証する。前章では、アウトラインに対してコンテンツを関連付けることでアウトラインの内容を執筆するために必要な情報の不足や偏りに気付くことができるという仮説を立てた。この仮説を検証するために、実際に被験者にTDEditorを用いて関連付けを行いながら論文執筆を行ってもらった。被験者には関連付けに関するアンケートに答えてもらい、その前後の変化を分析した。分析では実際にアウトラインに関連付けられたコンテンツの数と種類や実際の執筆に要した時間、論文自体の質との関係を調査した。
5.2 実験方法
5.2.1 関連付けるコンテンツ
我々の研究室の修士の学生4人を被験者として論文を執筆してもらうことで実験を行った。関連付けに関する実験を行う前に、前提として論文執筆開始時に関連付けられるコンテンツが既に十分に記録されている必要があるため、論文執筆開始前にコンテンツ収集期間を設けた。コンテンツの収集は3ヶ月程度とし、その間に被験者ごとに論文執筆に必要だと思われるコンテンツを作成・編集・収集してもらった。収集期間以前に作成・閲覧されたコンテンツも論文執筆に必要と感じたものがあれば、この期間の中で2章で述べた研究活動支援システムの中で編集またはマーキングすることでその期間の中で収集したコンテンツとした。本実験で関連付けの対象としたコンテンツは、画像・スライド・研究ノート・サーベイ文書・論文・Web文書とした。最低限のコンテンツを保証するため、被験者にサーベイを行う論文の数を20本に設定した。サーベイを行う際は、TDAnnotatorに論文を登録してアノテーションを行ってもらいTDEditorを用いてそれらの論文を引用しながらサーベイ文書を作成してもらった。その他のコンテンツは、DMシステムの中で使用されたプレゼンテーションスライド、iStickyで作成された画像や研究ノート、ブックマークレットにより登録されたWeb文書を用いた。サーベイする論文以外のコンテンツの数に条件は設定していない。
5.2.2 アンケートの実施
被験者ごとにコンテンツの収集を行った後に、実際にTDEditorを用いて論文の執筆を行ってもらった。その際に、アウトラインの作成とコンテンツの関連付けを行ってもらった。論文のアウトラインは章・節・項に加え、段落構成まで記述してもらった。コンテンツの関連付けによる影響を検証するために、コンテンツの関連付けを行う前と後でアウトラインの項目ごとに2回ずつアンケートに答えてもらった。コンテンツの関連付けは、論文アウトラインの木構造の親要素を持たない末端の項目に対してのみ行ってもらった。また、本システムで実装したコンテンツのアイコン表示やグラフ構造表示に関して、それらの表示が、関連付けたコンテンツを閲覧する際に有効かどうかを問うアンケートを論文執筆終了後に行った。
関連付けによる影響を検証するために、被験者が作成したアウトライン項目に実際に書く内容をどれだけ整理できているのかについて問い合わせた。これは、著者自身がどのような文章を書けばよいか頭の中でイメージできている度合いについて問うものであり、「十分に整理できている」から「まったく整理できていない」の間で5段階で答えてもらった。本研究では、この度合いを整理度と定義する。整理度が高いと判断されたアウトライン項目は、著者は何を書けば良いか把握している状況であるため、おそらく効率的に文章が書ける部分となる。逆に、整理度が低い場合は、アウトラインを作成してみたものの著者は実際にどのような文章を書けばよいのか分からない状態であり、執筆に時間がかかると考えられる部分となる。ただし、アンケートで答えてもらう整理度は、被験者の主観が入るため、実際の文章の執筆を行った場合に必ずしも整理度が高いほど論文が効率的に書けたとは限らない。そのため、本研究では実際にアウトライン項目の文章を埋める作業に要した時間を大まかに測定することで整理度と執筆速度の関連性を調べた。
整理度に関する設問とは別に、アウトライン項目ごとに関連付けられるコンテンツはどの程度存在するか問う設問を用意した。設問には、「十分存在する」から「まったく存在しない」の間で5段階で答えてもらった。本システムでは、通常では頭の中だけで行われる関連付けの作業を、コンテンツのアイコン表示、タイトル一覧表示、グラフ構造表示により可視化している。この設問では、このように被験者にコンテンツを提示することで、関連付け前と比べ論文に必要となるコンテンツの量に関してどのような変化があったのかを調査する。関連付けの作業を行うことで著者が想定していたよりもコンテンツが少ないことに気付き得るのか、逆にコンテンツが想定より多く存在することにも気付き得るのかどうかを検証した。また、設問で得た5段階評価の結果と実際に関連付けられたコンテンツの数との関連性や整理度との相関についても検証する。
被験者には、章ごとに作成したアウトラインが適切であるかどうかについて、関連付け前と後でどのような変化が現れるか調査した。設問には、「適切である」~「適切でない」の5段階で答えてもらった。この設問では、特定の章や節にのみコンテンツが大量に関連付けられた場合に、被験者はアウトラインが不適切であるかどうか感じるのかどうかを問う。逆に、関連付けることでアウトラインの「適切」である方向に変化する場合もあるのかどうか検証する。
本研究では、コンテンツを関連付けることにより、[icon]のようにコンテンツタイトルの横にコンテンツのアイコンが表示される。このアイコン表示が論文に書く内容の有無を把握する上で参考になったどうかをアンケートにより答えてもらった。また、アイコンの表示からアウトラインの不適切さに気付くことがあったかどうかも問い合わせた。
文脈情報の提示に関する評価
5.2.3 執筆時間と論文の質
コンテンツを関連付けた後は、それぞれのアウトラインの項目の内容の文章を埋める作業を行ってもらった。執筆作業全体の時間とキー入力時間を計測した。執筆作業全体の時間はエディタに執筆開始・終了ボタンを設けることにより計測した。執筆作業時間には、思考時間、文章編集時間、コンテンツ検索・閲覧時間が含まれるが、厳密にそれらを区別して計測することは困難であるため本実験では、文章編集時間であるキー入力時間を計測した。論文の質について評価するために、指導者1名にそれぞれの被験者の論文に対して指摘を行ってもらった。指摘は、4.5節で述べたTDAnnotatorを用いて行ってもらい付与された属性の数や種類を分析する。本実験では、指摘の多い論文は質の低い論文とし、逆に指摘の少ない論文は高い論文と仮定する。
5.3 結果と考察
まず、関連付け後と関連付け前の選択された末端のアウトライン項目全てに対する整理度の平均と分散を求めた。整理度は、5段階評価で最大を5、最小を1とした。作成されたアウトラインの項目数の合計508で、関連付け前で平均4.17・分散0.46、関連付け後で平均4.06・分散0.49となった。[smartg]に整理度の関連付け前後における全体の数を示す。関連付けの前後共に整理度は3~5の値をとることがこの表から分かる。これは、論文のアウトラインは、被験者自身がアウトラインの内容を書くことを想定して作成したものであるから、整理度が3未満になるようなアウトラインはあまり作成されにくいことが考えられる。関連付けの前後の変化を見てみると、整理度5が減り、整理度1、3、4の数が増加している。これらのデータから、全体的に見ると、整理度は関連付けにより下がる傾向にあることが分かる。この表だけでは、どのように整理度が変化しているのか分からないため、関連付け前後でそれぞれのアウトライン項目における整理度の変化の傾向を[sabtract]に示す。被験者ごとに変化の傾向に差が見られ、整理度が減少するアウトライン項目の方が多い傾向にある被験者Aもいれば、被験者Bのように増加・減少傾向が同程度に現れることもあれば、被験者Dのように極端に増加傾向のある場合もあった。[subtract]を見る限り、どちらかというと増加傾向の方が強いことが分かる。関連付け後では、論文に必要な情報を含むと想定されるコンテンツが被験者に可視化されるため、それらのコンテンツを閲覧することにより整理度に影響が出ると考えられる。提示されたコンテンツの中にそのアウトラインの内容を執筆するのに足る情報が予想よりも多く含まれていた場合は整理度が増加する考えられるが、逆に予想より情報が少なかった場合に、整理度は減少することが考えられる。本実験では、いずれにせよ関連付けにより被験者に対し、整理度に関して影響を与えたことを確認できた。被験者の数が少ないため、増加と減少のどちらの傾向が現れやすいかどうかを統計的に結論付けることはできない。しかし、増加するか減少するか否かは、それぞれの被験者の関連付けたコンテンツに含まれる内容に大きく依存するため個人差の影響は大きいと考えられる。
| 関連付け前 | 関連付け後 | |
| 整理度1 | 0 | 3 |
| 整理度2 | 10 | 10 |
| 整理度3 | 62 | 78 |
| 整理度4 | 302 | 316 |
| 整理度5 | 134 | 101 |
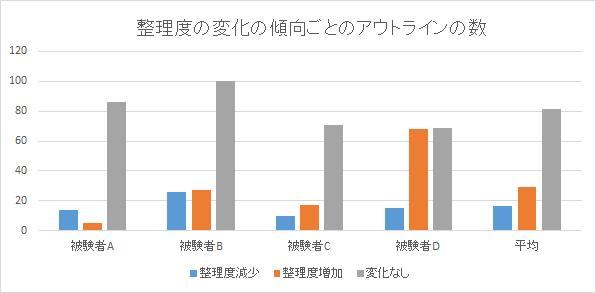
図5.1: 整理度の変化ごとのアウトラインの数
次に、コンテンツの量に関する執筆者の評価に関するアンケートの結果について述べる。整理度と同様に、5段階評価でコンテンツが多く存在すると執筆者が評価する場合の最大を5、最小を1に割り当てた。関連付けられるコンテンツの量ついては、アウトライン項目全体の平均では関連付け前が3.59、分散1.47、関連付け後が3.24で分散が1.58となった。平均はほぼ変化していないが、分布に影響が見られる。[contentg]に示される各アンケートの回答(コンテンツの量に関する5段階評価)ごとのアウトライン項目の数を見ると、整理度と比較してより顕著に影響が表れている。5段階で4とされたアウトラインの項目の数が減少し、2とされたアウトラインの項目の数が増加している。これは全体的に、コンテンツの数が少ないという意識に傾いていることが推測できる。実際に、関連付け前後での変化を見てみると[data2]に示される。被験者Aを除いた被験者3名は関連付け前後で、評価の値が増加する、すなわち関連付け前の予想より、コンテンツの量が多いと感じたことが分かる。ここで、実際に関連付けられたコンテンツの数について[contentdata]に示す。実際に関係付けられたアウトライン項目ごとのコンテンツ(全体)の数は、被験者Aが最も少なく、1.0を下回っている。故に、アウトラインに関連付けるコンテンツが存在しないことで、コンテンツが少ないということを自覚することが多かったと予想できる。被験者Aを除く被験者は、アウトラインの項目ごとに平均1つ以上のコンテンツを関連付けているため、当初の予想よりコンテンツが多いことを自覚しやすい傾向があると考えられる。1アウトラインあたりのコンテンツの数が特に多い被験者Cは他の被験者と比べ予想より少ないと感じることが少ない傾向にあることが分かる。
関連付け前 | 関連付け後 | |
(十分ある)1 | 55 | 62 |
| 2 | 29 | 80 |
| 3 | 125 | 124 |
| 4 | 160 | 107 |
| (少ない)5 | 139 | 135 |
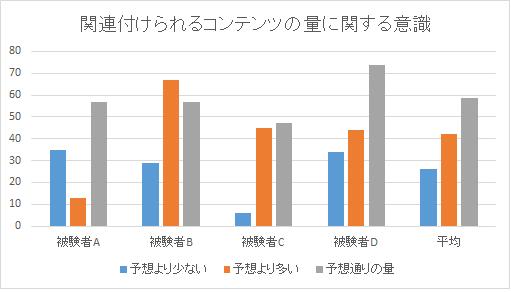
図5.2: 関連付けられるコンテンツの量に関する意識
| 他者の論文 | 自身の論文 | サーベイ文書 | 画像 | プレゼンテーションスライド | 研究ノート | Web文書 | 1アウトライン項目あたりのコンテンツの数平均 | |
| 被験者A | 0.10 | 0.00 | 0.10 | 0.00 | 0.15 | 0.00 | 0.01 | 0.37 |
| 被験者B | 0.30 | 1.80 | 0.08 | 0.00 | 0.36 | 0.18 | 0.00 | 2.72 |
| 被験者C | 0.29 | 3.10 | 0.16 | 0.27 | 0.40 | 0.36 | 0.08 | 4.66 |
| 被験者D | 0.40 | 1.59 | 0.18 | 0.22 | 0.47 | 0.04 | 0.01 | 2.97 |
また、アウトラインに対して関連付けられた実際のコンテンツの数と整理度についての相関を調べたところ[ss]のような結果となった。単純にコンテンツが関連付けられているほど整理度が高いわけではなく、整理度4の場合に最もコンテンツが多く、整理度5の場合には、整理度4の場合よりもコンテンツの数が全体的に少なくなる。コンテンツに含まれる情報が多すぎるが故に整理できていない場合も起こりうることがこの相関から分かる。また、このことから整理度が高い状態は、そのアウトライン項目に対して、必要なコンテンツが過不足なく関連付けられている状況であると推測できる。
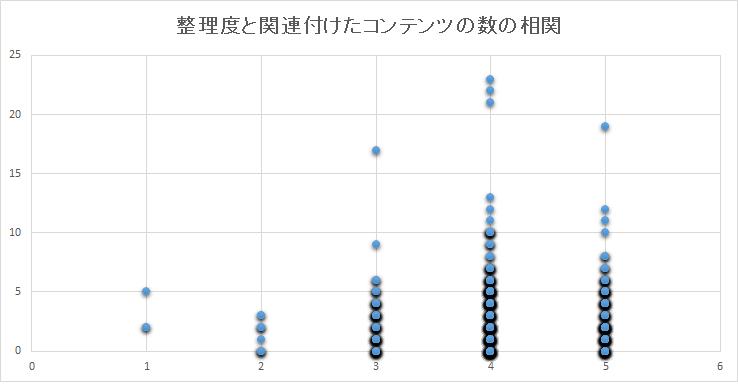
図5.3: 整理度と実際に関連付けられたコンテンツとの相関
次に、整理度は論文執筆速度にどのような相関があるのかについて[speed]に示す。[speed]は整理度ごとの執筆速度[s/100字]を示す。執筆時間はキー入力時間を計測しており、整理度が1、2、3の間で大きく差が見られた。キー入力時間は、バックスペースなどの修正キーを多く押された部分は必然的に入力時間が長く、引用時にコピーアンドペーストを行うと時間は大幅に短縮される。ただし、キー入力時間には個人差があり、入力時間が短い代わりに思考時間は長いケースも考えられるため参考データにとどめる。また、必ずしも入力時間が短いからといって良い文章であるとは限らないため論文の質についても考慮する必要がある。
| 執筆速度[s/100時] | |
| 整理度5 | 76.19 |
| 整理度4 | 70.25 |
| 整理度3 | 140.80 |
| 整理度2 | 171.32 |
| 整理度1 | 525.64 |
次に論文の質について、収集された指摘に基づき分析を行った。被験者ごとの論文に対する指摘の数を[quality]に示す。他の論文と比較して、被験者Cの論文が最も指摘が少ないことが分かる。再び[contentdata]を見ると被験者Cは最もコンテンツを関連付けている被験者であり、また、自身が作成した研究メモ・論文・サーベイ文書を比較的多く関連付けていることが分かる。日頃から論文の中で参考にできるような文章を書く習慣を持つ被験者は、論文の質が高くなる傾向があることが推測できる。一方で最も指摘数の多い被験者Dは、最も多く他者の文書である論文を関連付けており、自身の研究ノートの割合が小さい。他者の文章を文章執筆時に参照・引用する際には、その文章を自身の文章の文脈に合うように適切に編集する必要があるため、その際うまく文脈に合うように編集することができなかったため、スタイルに関する指摘が最も多いのではないかと考えられる。また、最もコンテンツが少ない被験者Aは最も指摘の数が多く、参考にできるコンテンツが少ないため、適切な文章を書くことが困難であったことが予想できる。
| 内容に関する指摘 | スタイルに関する指摘 | アウトラインに関する指摘 | その他のコメント | 指摘数合計 | |
| 被験者A | 107 | 148 | 5 | 7 | 267 |
| 被験者B | 45 | 38 | 1 | 13 | 97 |
| 被験者C | 36 | 27 | 3 | 4 | 70 |
| 被験者D | 50 | 74 | 4 | 6 | 134 |
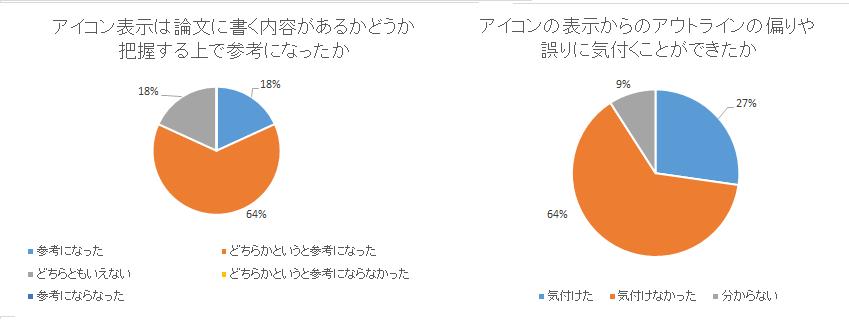
図5.4: コンテンツアイコンに関するアンケート結果
次に、論文執筆後のアンケートの結果を示す。[exicon]にコンテンツのアイコン表示に関する設問に関するアンケート結果を示す。コンテンツのアイコン表示が論文に執筆するための情報が存在するかどうか判断する際に参考になったかという問いに関しては、参考になったかなっていないかの間で5段階で評価してもらった。その結果[exicon]左のように参考になった・どちらかというと参考になった被験者を合わせると82%となった。コンテンツのアイコン表示により、アウトラインに書く内容の偏りや誤りなどの不適切な部分に気付くことができたか否については、[exicon]右に示す通り、気付けない・分からないといった解答が73%であったが、27%の被験者は気付くことができたと答えている。これらの結果から、関連付けられたコンテンツの有無を確認する上でコンテンツアイコンの表示は有効ではあるが、単純にアイコンでコンテンツの種類や数を示すだけでは、アウトラインの不適切さに気付くことが難しいと考えられる。しかし、一部の被験者は、気付くことができたと解答している。これらの結果からアウトラインの適切さまで気付けるかどうかは、実際に関連付けられるコンテンツの量がどの程度あるかに依存すると考えられる。
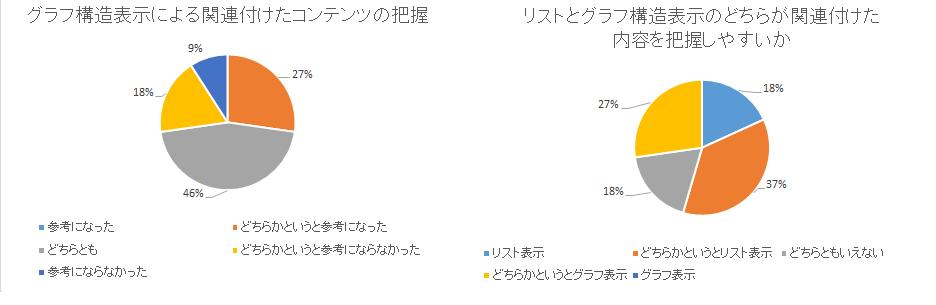
図5.5: グラフ構造表示に関するアンケート結果
グラフ構造表示に関するアンケートの結果は[gresult]に示すようになった。関連付けたコンテンツの量を把握する上で有用であったかどうかについて([gresult]左)は、どちらともいえないと答えた被験者が46%となり、参考にならなかった・どちらかというと参考にならなかった割合は2つ合わせて27%、どちらかというと参考になったが27%となっている。グラフ構造表示と通常のタイトル一覧のリスト表示のどちらが良いかというアンケート([gresult]右)に関しては、リスト表示の方が良いとする意見の方が多かった。アンケートの自由記述では、「関連付けられるコンテンツがもともと多くなかったため、グラフで表示する必要性を感じなかった」「コンテンツが多すぎてよく分からなかった」という被験者も存在した。コンテンツが少ないとグラフによる表示の恩恵はあまり得られないと考えらる。また、多すぎる場合には表示方法を工夫する必要があると考えられる。今後、リスト表示では表現できない部分引用関係を提示する仕組みをグラフ構造表示で実現すれば、このアンケート結果はまた違うものになるであろう。
5.4 議論
本システムで提案したコンテンツの関連付けについて議論する。本手法による論文執筆は、段落アウトラインまで著者に記述させてさらにコンテンツを関連付ける仕組みを提供した。5.2節の実験結果により、関連付けが、整理度や関連付けるコンテンツの量に関する自己評価に関してが影響を与えることを示した。しかし、5.2節の実験結果では言及しなかったが、従来の論文執筆にはない関連付けに要する時間的コストが生じる。高度な検索技術により関連付けに要する時間を短縮できたとしても、全ての段落アウトラインに対して関連付けることは現実的ではない。すべてのアウトライン項目に対してコンテンツを関連付けるのではなく、比較的整理度が低いと思われるアウトラインの項目に対して関連付けることを我々は想定している。頭の中で整理できていな部分に対し、この手法を適用することで、質の高い論文アウトラインが作成できるものと考えられる。本研究では、作成された論文のアウトラインそのものの質についての客観的な評価は行わなかったが、関連付けを行う被験者とそうでない被験者で分けて統計的な有意差を検証する必要がある。また、実験の中では、必ず関連付けを行ってから執筆を行ってもらったが、実際にこの関連付けの仕組みがどのくらいの頻度で利用されるかどうかは、今後運用を続けてデータを収集することで分析する必要がある。
また、本提案手法は、論文執筆の初期段階に論文アウトラインを作成しコンテンツを関連付けることを想定しているが、必ずしも初期段階において0から木構造を作成する必要はないと考えている。別の作成方法として、常日頃から研究活動内容を木構造で整理する、すなわち研究活動アウトラインを作成しておき、論文執筆時にその構造を再利用して論文アウトラインを作成する方法がある。関連付けの作業を研究活動中の日常的な作業として組み込むことで、執筆開始時の関連付けのコストを小さくすることが可能となる。理想的には、このようなアプローチの方が有効であると筆者は考える。しかし、研究に慣れていない学生などは、木構造で研究アウトラインを表現することが困難である可能性があるため、木構造とは別の、例えば、第2章で述べたDRIPシステムのようなグラフ構造でアウトラインを表現する必要がある。
本章では、コンテンツの関連付けがどのように執筆に影響するのか検証した。具体的には、整理度や関連付けるコンテンツの量の自己評価に関する影響を、関連付け前後のアンケート調査により分析し、関連付けられるコンテンツが多いほど、意識に変化が生じやすいことが分かった。また、実際に関連付けられたコンテンツの数や種類について分析し、自身が作成した文書やコンテンツを関連付けている被験者の方が論文の質が高い傾向があることが分かった。今回、文脈情報の可視化の有効性に関する評価は、コンテンツの部分引用関係が十分に記録されていなかったため行わなかった。TDEditorを含む研究活動支援システムを運用していくことによって大量の部分引用関係を収集することで、今後は、これらの可視化に関する仕組みについて、定性的なアンケート以外の定量的な評価を行う予定である。
次章では、本研究の関連研究について述べる。
6 関連研究
本章では、本研究の関連研究として、コンテンツのアノテーションに関する研究、文書作成支援に関する、引用関係を用いた論文の検索に関する研究について述べる。
6.1 コンテンツのアノテーションに関する研究
この節では、多様なコンテンツに対するアノテーションに関する研究について述べる。
文書へのアノテーションは、最も普及しているPDFリーダであるAcrobat Readerを初めとして、EvernoteやGoodReaderなど様々なアプリケーションの機能として既に一般的なものとなっているが、文書へのアノテーションに関する研究はこれまでに盛んに行われてきた。代表的なものとして、Xlibris[8]が挙げられる。Xlibrisでは電子文書の部分要素に対してペンタブレットを用いてアノテーションを付与することができ、アノテーションをユーザ間で共有する仕組みを実現している。ペンを用いたアノテーションを実現することで、紙に対するアノテーションと同様に直感的な操作が行える。TDAnnotorでは主に、PCでの操作のみに対応しているが、携帯端末などで、場所を選ばずに紙と同様に手軽にアノテーションXlibrisのようなインタフェースが望ましいため、今後TDAnnotatorを様々なデバイスに対応させる必要がある。
その他の文書へのアノテーションの仕組みとしては、林らが開発した閲覧時アノテーションシステムがある。林らのアノテーションシステム[20]では、文書への下線やハイライトなどのマーキング行為に対する属性、アノテーションの中で付与するテキストに関するコメント属性を定義し、それらの属性情報を付与したアノテーションを実現し、それらのアノテーションを論文執筆時に検索・引用可能にすることで、文書の引用を支援する仕組みを実現している。TDAnnotator上では必要最小限の属性やタグの入力しか実現していないが、林らのアノテーションシステムのように論文読解時に有用なタグや属性をリストアップしておく必要ことで、引用時の効率的な検索や引用意図の抽出が実現できるものと考えられる。
Bernhardがアノテーションシステムとして開発したWebドキュメントに対するWeb文書に対してアノテーションが行える。また、pilinyやEvernoteなどのアプリケーションでは入力したWebページの一部分をクリップしてコメントの付与やノートの作成が行える。また、pilinyではWebページ及び作成ノートを関連付けグラフ構造で可視化する仕組みを提供している。研究活動においてWeb文書を扱うことは多いため、TDAnnotatorやTDEitor上でWebドキュメントの部分要素を容易に扱える仕組みが今後求められる。
画像や映像のアノテーションの仕組みは既にWebサービスとして実現されている。Flicker[http://www.flickr.com/]はWebサービスでは投稿した画像の部分要素に対してアノテーションが行える。Flickerは個人が撮影した画像を共有するサービスであり、画像の部分に対するコメント記述、画像に対するタグの記述、画像のブログや日記などへの引用などの仕組みを提供している。これによって画像の部分を強調し、画像を閲覧したユーザの注目を集めることができる。大手映像配信サービスであるyoutube[https://www.youtube.com]では映像の特定のタイムコードに対するアノテーションや、映像を個人のWebサイトや他のWebサービス上で引用できる仕組みを提供している。映像を引用する際には指定したタイムコードから再生することも可能となっている。Bernhardらが[15]開発した2次元地図画像に対するアノテーションシステムでは、TDannotatorで実現するような矩形範囲選択に加え、自由線、円、楕円など様々なインタフェースを実装している。今後はこれらのインタフェースを適用することで柔軟な画像へのアノテーションを実現する必要がある。
本システムで利用したSharvieは、山本ら[21]のSynvieを研究室内部向けに開発したものである。Synvieでは映像シーン引用ブログの仕組みを利用したものであり、Youtubeとは異なり、映像の開始点と終了点してブログに引用することができる。さらに、引用先のテキストを解析することで、それらのテキストを映像シーン検索に利用している。TDEditorの仕組みは、このSynvieのブログへの引用の仕組みを論文に適用したものであると言える。
本システムでは、文書作成時の文書における文書の検索について詳しく述べたが、文書作成時の効率的な画像や映像の実現のために、これらの画像や映像のアノテーションの仕組みが今後検索において有用となると考えられる。
本システムでは、様々なシステムやアプリケーションを通して、クラウド上でコンテンツとそのアノテーションを管理し、それらのクラウドのデータを論文執筆に活用する。本システムのように、アノテーションを他のシステムやサービス上でも相互に利用可能にするためのフレームワークについて、Bernhard らが提唱している。Bernhardらは、そのようなアノテーションを相互運用可能にする上で必要な技術的要件について詳細に定義している。その中では、部分要素の定義に関してや、今後増え続ける多様なコンテンツにも対応した拡張可能なアノテーションの記述方法について述べられており、本研究活動支援システムもこのフレームワークを適用すること十分に可能であると考えられる。
6.2 文書作成支援に関する研究
Ulrichら[7]では、論文執筆時の文献の検索支援を目的とした参照・引用情報を可視する仕組みを実現している。具体的には、PDFから機械処理により引用関係を抽出し、さらに、引用関係に加え、どのような目的で引用されているかの分類も行っている。引用関係の抽出にはParsCitと呼ばれるツールを用いており、引用関係取得の精度に関しては高精度の結果を出している。ただし、引用意図の分類の精度は低いことが報告されている。Ulrichらは、それらの機械処理による引用関係に基づき横断的に文献を検索するシステムを提供している。システムで引用関係にり発見された文献では、その実際の引用先のPDFの部分の文書をハイライト表示して閲覧することが可能となっている。この手法では、検索対象となるコンテンツはある特定の分野の論文の集合であり、本提案手法では、論文の著者自身が作成・閲覧した文書の集合に限られるため検索対象が異なる。しかし、参照・引用関係に基づいた論文を横断的に検索させる手法はTDEditorにも適用できるものと考えられる。
google sholorのようなオンラインで文書を同時編集する仕組みが存在する。しかし、時間的な制約のため、作成した文書に対する質問文を自動生成することで、作成文書の理解度を問う研究がある。質問文の自動生成には、wikipediaの情報や特定の単語に対応する。
O'Rourkeら[22]は学術文書作成能力を客観的に評価する仕組みを実現している。具体的には、段落に含まれる文章を解析し、語の出現頻度や及び単語間の共起頻度から段落のトピックモデルを生成し、それらのモデル間の類似度を計算し、2次元空間に表現する。もし作成した文書に含まれる連続する2つの段落間の距離が非常に離れていた場合、客観的にそれらの段落間のつながりが悪いことを知ることができる。
本手法では、アウトラインに対してコンテンツを関連付けることで、段落構成の妥当性を著者に判断せる仕組みを提案しているが、この仕組みでは作成した段落の文章に基づき段落の構成の妥当性を客観的に評価している。この仕組みを適用し、本システムのアウトラインに関連付けたコンテンツの文章を解析することで、アウトラインの妥当性を客観的に評価する仕組みが考えられるが、高度な技術が必要となる。
大野らが作成した文の論理構造デザインツール[11]では、文章の構造の段落に対して、文書の作成者に、タイトル、主題文、展開部を入力させることで論理的な文章構造の作成を支援する。主題文とは、その段落で主張したい内容を記述する1~2文程度の文であり、段落全体の要約となる文、展開部は主題文の内容を詳しく説明する文で1つ以上の文から成り立つと定義されている。論文アウトラインを作成する際は段落の内容を明示的に示すタイトルのみを入力させたが、主題文と展開部を定義することでより文章に書く内容が整理される可能背も考えられる。
また、大野らは、デザインの中で、文書構造であるアウトラインをグラフ表示及び木構造の2通りの表現方法を実現し、それらを必要に応じて切り替えるシステムを実現している。論文においては、すでに論文に内容はある程度決まっているため、木構造表現のみで十分である可能性が高いが、DRIPシステムなどの何か新しくアイデアを考えたり、整理する際は、このようにグラフ構造を用いるほうが良いと考えられる。
7 おわりに
7.1 まとめ
本研究では、研究活動の中で記録される多様なコンテンツ及びコンテンツのアノテーションを論文執筆時に活用することで論文執筆を支援する仕組みについて述べた。そして、被験者実験により支援の有効性を示すと共に、実際に本システムを研究室において運用した。
第2章においては、論文執筆に至るまでのプロセスについて述べ、さらに、我々の研究室で実現してきた研究活動支援システムを用いて、多様なコンテンツ(文書、画像、映像、発表資料、議事録等)を記録する仕組みについて述べた。また、その研究活動支援システムの中で、コンテンツの検索に有用なメタ情報を含むアノテーションを収集する仕組みについて述べ、それらのアノテーションの収集における現状の問題点について述べた。
第3章においては、論文執筆において最も参照される可能性の高い論文などの文書を管理する仕組みであるTDAnnotatorについて述べ、さらにそれらの文書を含むあらゆる研究活動の中で作成・閲覧してきたコンテンツを参照・引用しながらサーベイ報告や発表資料などの公開文書を作成する仕組みであるTDEditorについて述べた。また、既存の研究活動システムでは大量に収集することのできなかったコンテンツの文脈情報である部分引用関係を、文書作成の過程において自然に収集する仕組みを実現した。
第4章においては、研究活動の中で記録してきたコンテンツを論文アウトラインに対して関連付けることで論文執筆を支援する仕組みについて述べた。そして、研究活動の中で自動で収集した部分引用関係をコンテンツの文脈情報としてグラフとして論文執筆時に可視化することで、論文執筆に不慣れな学生に対して論文に必要な情報を把握させる仕組みを実現した。
第5章においては、論文アウトラインに対してコンテンツを関連付ける有効性を検証するために行った、被験者実験について述べた。アウトライン項目ごとにアンケートを行い、関連付けの前後で論文を書く必要な情報が整理できているかどうか、コンテンツが十分に存在するかどうかの意識の変化について調査した。その結果コンテンツの関連付けを行うことにより整理度やコンテンツの量に館する自己評価に影響を与えることが分かった。コンテンツを関連付けている被験者ほど、論文の質が良いことを示した。
第6章では、文書作成支援に関する研究、コンテンツのアノテーションに関する研究、参照・引用関係に基づいた論文の検索支援に関する研究について述べた。
最後に、本研究の課題について述べる。
7.2 今後の課題
今後の課題としては、以下のことがあげられる。
7.2.1 文脈情報の可視化に関する評価
本論文では、十分な量の部分引用関係が記録されていなかったため、文脈情報の可視化に関する評価は行わず、単純なグラフ構造の提示に関するアンケートによるグラフ構造提示の定性的なみを行った。評価を行うためには、継続的なTDEditor、TDAnnotator、DMシステムTMB、iSticky等の運用に基づき文脈情報である部分引用関係を大量に収集する必要がある。また、現在はシステムの中で自動で収集する部分引用関係を用いた可視化を実現しているが、既存のWeb上で公開されている情報やPDFの機械解析に基づいて得られる引用関係と組み合わせることにより、網羅的に引用関係を提示する仕組みを実現する必要がある。
7.2.2 文脈情報の提示の改善
本論文では、論文のアウトラインに関連付けられたコンテンツをグラフ構造を用いて提示したが、より適切な提示方法が今後の課題となる。まず、本研究ではグラフにおけるコンテンツ間のエッジの重みについては考慮していない。今後は、引用意図(反対・賛成・比較等)を引用時に獲得する仕組みが必要となる。その際に、著者に引用意図を入力させる仕組みは編集コストの関係上好ましくないため、引用元と先の文章及びその文脈を機械的に解析することで自動的に収集仕組みが求められる。これらの引用意図の情報の他にコンテンツの種類や作成日時などの情報を組み合わせることで、ユーザの要求に適したグラフ構造を提示することが可能になると考えられる。
7.2.3 論文執筆時のコンテンツの高度な検索・推薦
現状のTDEditor上でのコンテンツの検索機能では、コンテンツタイトル、作成日時、作成者、タグ等を用いた単純な検索のみを実現した。しかし、研究活動が長期にわたり、コンテンツの数が膨大になる場合はこれらの検索だけでは不十分である可能性がある。本研究では、TDEditor及び既存の研究活動支援システムの中で部分引用関係を収集しているため、これらの引用関係を適切に検索に活用することが今後の課題となる。引用関係のようなリンク情報に基づいた検索アルゴリズムはPageRankやHITSなど様々なものがあるため、これらのアルゴリズムを参考にコンテンツの検索精度を向上させることが必要となる。
また、本研究では、執筆の初期の段階でコンテンツの関連付けの仕組みを実現しているため、この関連付けたコンテンツに基づいた文章執筆時のコンテンツの検索・推薦が今後の課題である。あるアウトラインの内容に関するコンテンツを検索する場合に、アウトラインに関連付けたコンテンツに関連するコンテンツのみに絞って検索することで、通常の検索よりも精度の高い検索が期待できる。また、引用関係や執筆中の文章に基づきコンテンツを推薦するといった応用も実現することが可能となる。
7.2.4 参照・引用情報のシステム間での相互運用
TDEditorによって収集されるアウトラインへの関連付けや部分引用関係をTDAnnotator以外の、研究活動支援システムで利用可能にすることが課題として挙げられる。利用例として以下のものが考えられる。
画像や映像はテキストデータとは異なり、一般的に検索が困難であるが、論文に引用されている場合は、引用先の文章の周辺のテキストに基づいて容易に検索することが可能となる。論文の文章は文法的に適切であることがある程度保障されるため、論文の文章を解析することで通常の文書に含まれる画像や映像よりも比較的精度の高い検索が行える。また、本システムでは、映像部分であるシーンを文章の中に引用して埋め込むことが可能となるため、引用先のテキスト情報に基づいた映像シーン検索の仕組みを実現することが可能となる。さらに、引用関係に基づいてあるヒットした画像や映像から関連するものを推薦・提示する手法も実現できる。
論文の中に引用された画像や映像は、そうでないものに比べ再利用性が高いと考えられるためこのような論文に引用された画像・映像の検索システムが求められる。また、検索結果に引用先の論文へのリンクを提示しておくことで論文に対するアクセス手段が増やすことができる。論文は、その分野の初学者などが閲覧する際には、内容によっては理解が困難である場合があるが、画像や映像といった視覚的に理解しやすい情報を検索・閲覧可能にすることで、論文の読解に対する敷居を下げることも期待できる。
2章で述べたTMBシステムでは、画像やノートに加えて、今後スライド・映像・論文など様々なコンテンツを引用できる仕組みを実現する予定である。その場合、TDEditorの仕組みと同様に、引用したコンテンツの部分引用関係を辿ることで、ミーティング時に過去の関連するコンテンツを検索することが可能となる。ミーティング時にこれらのコンテンツを参加者間で閲覧することで、埋もれていたアイデアを思い出すことが可能となる。
TDEditorを用いて作成された論文をその部分引用関係と共に2章で述べたDRIPシステムに反映することで、新たな研究活動マップを作成することも課題の1つである。引用が継続的に行われていれば、自身の研究の発生から論文執筆に至るまでの過程を横断的に閲覧することができる。
また、TDEditor上でこの研究活動マップを検索・関連付け可能にすることでより論文の執筆を支援する手法も考えられる。本システムでは、作成する論文アウトラインに対してコンテンツを関連付ける仕組みを提供したが、最初にアウトラインそのものの作成を支援する仕組みは実現していなかった。論文執筆に至るまでに生成された研究活動マップと作成する論文アウトラインは密接な関係があると考えられるため、研究活動マップから容易に論文アウトラインを生成する仕組みが必要となる。